OPT-Pose is a unified feed-forward Transformer framework for model-free unseen object pose estimation. It bridges two previously disjoint paradigms—category-level absolute SA(3) pose and relative SE(3) pose—achieving SOTA performance on benchmarks like REAL275, HouseCat6D, and Omni6DPose without requiring CAD models or category labels.
TL;DR
OPT-Pose (Object Pose Transformer) is a breakthrough framework that unifies category-level absolute pose and cross-view relative pose estimation into a single, model-free Transformer. By factorizing the task into depth, point maps, and NOCS prediction, it eliminates the need for CAD models, category labels, or manual camera calibration, setting new SOTA benchmarks across multiple datasets.
The Paradigm Shift: Why Unified Pose Matters
Traditionally, researchers treated absolute pose (where is this cup in 3D space?) and relative pose (how has this object moved between Frame A and Frame B?) as separate problems.
- Category-level methods (like NOCS) are great at absolute pose but "die" if they encounter an object not in their training taxonomy.
- Relative methods are robust to unseen objects but are "blind" to the global coordinate system in a single view.
The authors of OPT-Pose realized these two tasks are actually complementary. If you can reason about an object's geometry in both camera space (via point maps) and canonical space (via NOCS), you can leverage multi-view consistency to solve single-view ambiguities.
Methodology: The Power of Task Factorization
The core "magic" of OPT-Pose lies in its geometric factorization. It predicts several layers of information from raw RGB(-D) inputs:
- Depth + NOCS: Maps pixels to a shared [0, 1]³ canonical box. This recovers SA(3) (Rotation, Translation, and Scale).
- Depth + Point Map: Represents objects in the camera's local 3D coordinate system, enabling SE(3) (Relative alignment).
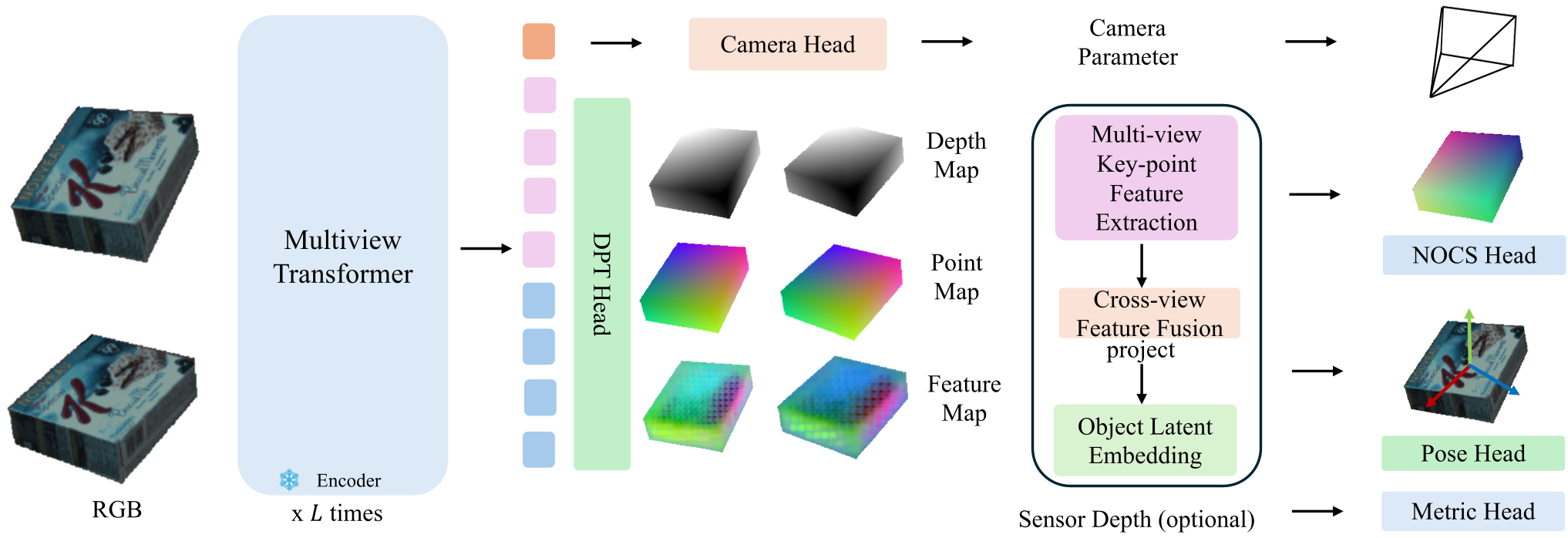
Key Technical Innovations:
- Contrastive Latent Space: The model uses an InfoNCE loss to ensure that features of the same object type (or instance) cluster together in a latent space. This allows the NOCS head to be "conditioned" on an object code without needing a text label like "mug" or "drill."
- Visual-Geometric Fusion: Unlike simple MLP heads, OPT-Pose uses a transformer-based fusion block that integrates local 3D neighborhood context (from point clouds) with global visual features (from DINOv2/ViT backbones).
- Camera-Agnostic Design: It estimates camera intrinsics on-the-fly, allowing it to work on uncalibrated web images or diverse robot sensors.
Experimental Results: Dominating the Benchmarks
OPT-Pose was tested on "Unseen" scenarios—objects the model never saw during training.
1. Absolute Pose (Category-Level)
In the scale-agnostic REAL275 benchmark, OPT-Pose crushed prior methods. Specifically, at the strict 10° threshold, it achieved 82.5% accuracy, a massive jump from the previous best of 68.8% (UniDet).
2. Relative Pose (Unseen Objects)
On the NOCS-REAL dataset for relative transformation, OPT-Pose reached 94.2 ADD(-S), compared to 53.5 for Any6D. This demonstrates the framework's superior ability to align points across views.

3. Multi-view Synergy
One of the most impressive findings (Table 2 in the paper) is that by simply feeding the model more views (S=2, 3, or 4) during inference, the absolute pose accuracy for the anchor frame increases. This proves that "relative geometric reasoning" helps the model "understand" the 3D structure of the object better.
Critical Analysis & Future Directions
Takeaway
OPT-Pose proves that 3D vision is moving away from "naming objects" (classification) toward "understanding geometry" (point-based reasoning). By treating all objects as geometric entities in a latent space, we achieve true Open-Vocabulary performance.
Limitations
- Object-Centric Requirement: The model still requires a bounding box or crop of the object.
- Illumination Sensitivity: Like most RGB-based methods, extreme lighting changes can degrade the point map accuracy.
- Symmetry: Ambiguities in symmetric objects (e.g., a perfect sphere or cylinder) remain a challenge for canonicalization.
In the future, seeing this integrated into a large-scale pre-trained model (like a 3D version of GPT) could lead to robots that can manipulate any object in any environment from the moment they are turned on.
Reference: Li, W. et al. "Object Pose Transformer: Unifying Unseen Object Pose Estimation." Technical University of Munich & Toyota Motor Europe.