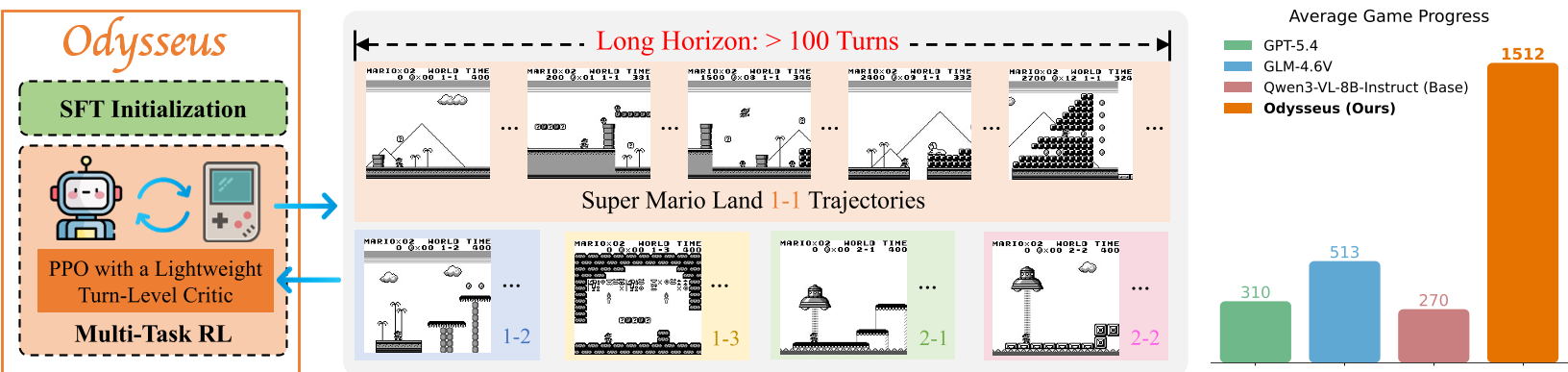
The paper introduces Odysseus, an open training framework that scales Vision-Language Models (VLMs) to handle long-horizon (100+ turns) decision-making in games like Super Mario Land. By combining a lightweight turn-level CNN critic with an adapted PPO algorithm, the authors achieve a 3x to 6x improvement in game progress over frontier models like GPT-4 and the Qwen-VL base model.
TL;DR
While Vision-Language Models (VLMs) excel at reasoning, they often fail as "agents" in complex, long-turn environments. Odysseus changes this by proving that with the right Reinforcement Learning (RL) recipe—specifically an adapted PPO with a lightweight CNN critic—VLMs can master games requiring 100+ turns. Odysseus outperforms proprietary giants like GPT-4 by over 300% in game progress while maintaining general-domain reasoning.
The "Horizon" Problem: Why VLMs Get Lost
Current AI agents are mostly "short-sighted." In standard benchmarks, tasks are finished in 20-30 steps. Scaling to 100+ steps (like a full level of Super Mario Land) introduces the Credit Assignment nightmare: which specific action among 100 turns actually led to success or failure?
Prior works tried to solve this with:
- Imitation Learning (SFT): Hard to scale because human data is expensive.
- Critic-free RL (GRPO/Reinforce++): These often fail in long-horizon games because they can't accurately estimate the value of a state without a dedicated critic.
Methodology: The "Secret Sauce" of Odysseus
The researchers identified that you don't need a massive 8B parameter model to tell you if Mario is in a "good" or "bad" position.
1. The Lightweight Turn-Level Critic
Instead of using a second VLM as a critic (which doubles VRAM usage), Odysseus uses a simple CNN critic originally designed for classical Atari RL. This critic looks at the game frame and provides a scalar value. This makes PPO training feasible on consumer-grade hardware while providing the stable baseline needed for long-term rewards.
2. Positive-Advantage Filtering
The team found that samples with negative advantages (actions that performed worse than expected) often destabilized the VLM’s transformer weights. By clipping these at zero, they focused the model on climbing the gradient of "what worked."
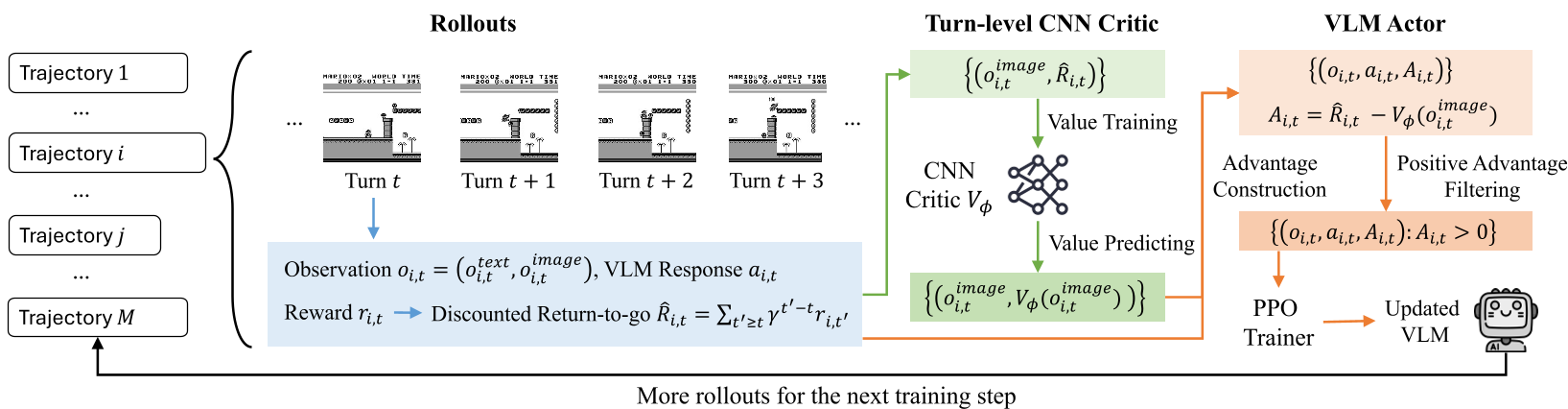
3. Auto-Curriculum
In multi-level training, agents often spend too much time on easy levels (where they survive longer) and neglect hard ones. Odysseus uses inverse trajectory weighting, automatically shifting training focus toward levels where the agent dies quickly, ensuring balanced mastery.
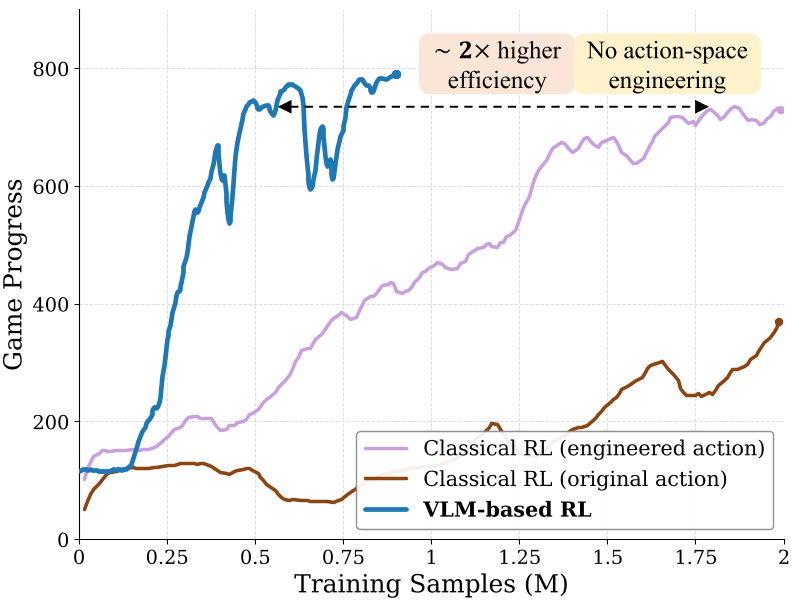
VLM-based RL vs. Classical RL: The Prior Knowledge Advantage
A fascinating insight from the paper is the comparison between Odysseus and a classic CNN-based RL agent trained from scratch.
- Classical RL: Needs "action engineering" (manually limiting buttons) to even start learning.
- VLM-based RL (Odysseus): Uses the VLM's inherent understanding of "right," "jump," and "enemy" to explore efficiently.
As a result, Odysseus is 2x more sample-efficient. It doesn't just learn to press buttons; it uses its world knowledge to understand why it should press them.
Results & Generalization
Odysseus achieved massive gains across all five training levels. More importantly, it showed Zero-shot Generalization:
- In-game: Handled unseen levels of Super Mario Land.
- Cross-game: Successfully played Super Mario Bros (NES), a different game with similar mechanics.
- General Intelligence: Unlike many RL agents that become "idiot savants," Odysseus retained its scores on benchmarks like MMMU and RealWorldQA.
Conclusion: A Blueprint for Embodied AI
Odysseus demonstrates that we don't necessarily need bigger models for better agents; we need smarter RL training loops. By offloading temporal reasoning to a lightweight critic and leveraging the rich visual priors of VLMs, we can build agents capable of sustained, complex interactions in the real (or virtual) world.
Key Takeaway: The future of embodied agents lies in hybrid architectures where "System 2" reasoning (VLM) is grounded by a "System 1" value estimator (CNN Critic).