Online3R is an online learning framework for consistent sequential 3D reconstruction that adapts a frozen geometry foundation model (MASt3R) to novel scenes. It introduces lightweight learnable visual prompts and a local-global self-supervised strategy, achieving state-of-the-art performance in both camera pose estimation and dense geometry on benchmarks like TUM RGB-D and 7-Scenes.
Executive Summary
TL;DR: Online3R is a paradigm-shifting framework that enables frozen 3D geometry foundation models to "learn" and adapt to new environments in real-time. By injecting lightweight visual prompts and staying updated via a local-global self-supervised loop, the system resolves the long-standing issue of geometric inconsistency in sequential reconstruction without requiring expensive full-model fine-tuning or ground truth data.
Positioning: This work is a crucial "adaptation layer" for the recent wave of geometry foundation models. While models like MASt3R provide powerful zero-shot priors, Online3R provides the mechanism to turn these general priors into scene-specific expertise, pushing the boundaries of SOTA in monocular SLAM and dense reconstruction.
Problem & Motivation: The Frozen Prior Dilemma
Foundational models like DUSt3R and MASt3R have revolutionized 3D vision by predicting point clouds directly from image pairs. However, when these models are deployed in a sequential SLAM pipeline, they face a "Local vs. Global" conflict:
- Scene Sensitivity: A model trained on diverse data may still miscalculate geometry in a specific, unseen room due to lighting or texture variations.
- Drift: Without a way to update the model's internal understanding of the scene, small per-frame errors accumulate, leading to "ghosting" effects where the same wall appears in two different places in the reconstructed map.
Previous attempts either involved heavy backend optimization (BA) or memory-intensive recurrent units. The authors of Online3R argue that it’s more efficient to adapt the model's input processing through prompts rather than fighting the model's outputs.
Methodology: Adaptation via Dual-Consistency
The core of Online3R is Online Prompt Tuning. Instead of changing millions of weights, it optimizes a small set of "Prompt Tokens" (32 tokens, 1024-dim) inserted into the Vision Transformer (ViT) layers.
1. Architecture Overview
Online3R leverages a frozen MASt3R backbone. The visual prompts interact with image tokens via self-attention, effectively "steering" the foundation model's interpretation of the current scene geometry.
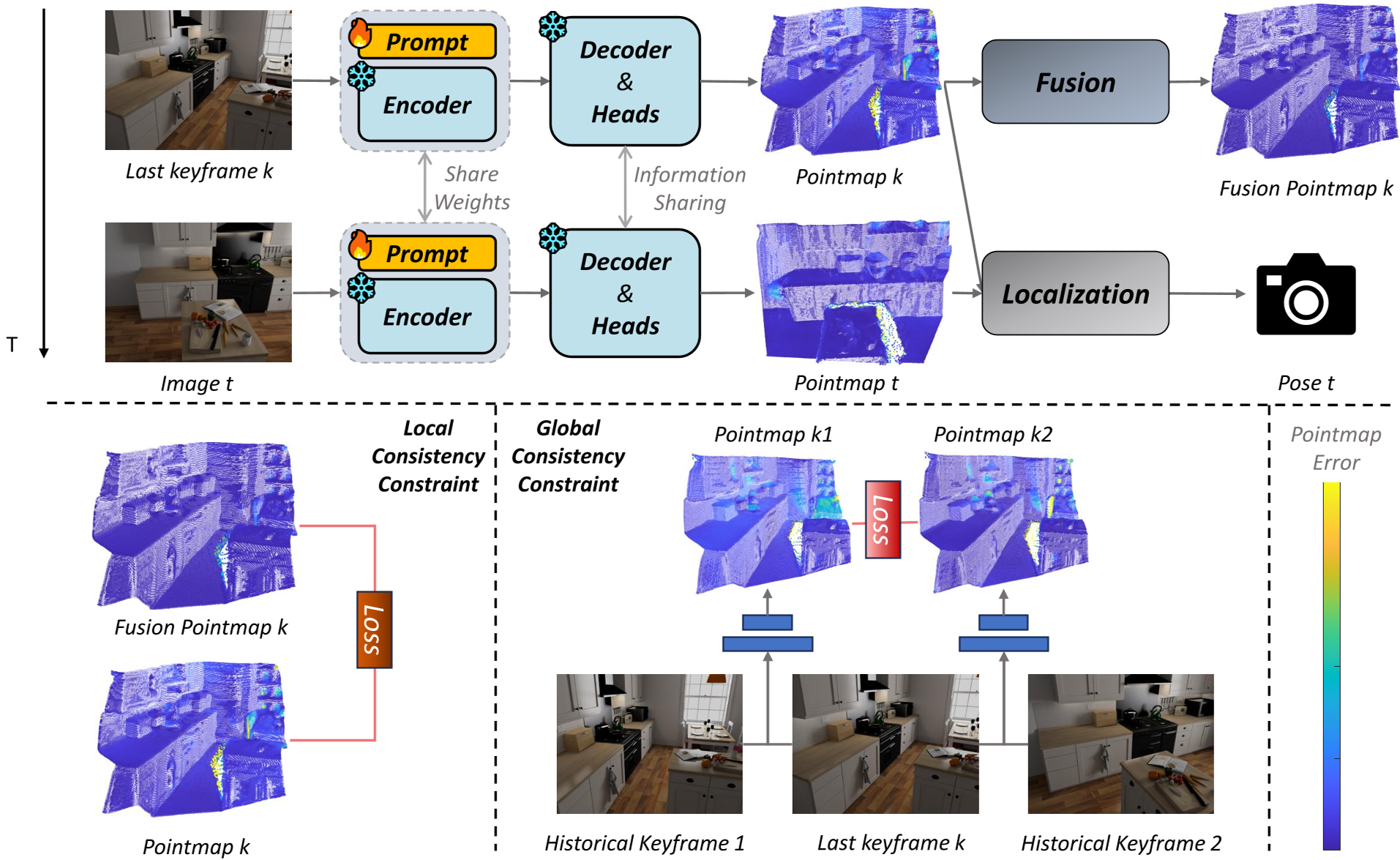
2. The Self-Supervision Engine
Without ground truth (GT) at test time, how do we train the prompts? Online3R introduces two clever constraints:
- Local Consistency: It uses a "running weighted average" of point clouds (Map Fusion). Since fused maps are less noisy than single-frame predictions, the fused map serves as a Pseudo-GT to refine the prompt.
- Global Consistency: It enforces a "view-invariant" constraint. If the model looks at the same point from two different historical keyframes, the predicted 3D coordinates must match. This prevents the "forgetting" effect and stabilizes long-term trajectories.
Experiments & Results: SOTA Efficiency
The researchers tested Online3R on the TUM RGB-D and NRGBD datasets. Despite being a monocular method (no depth input), it consistently outperformed existing SLAM systems.
Performance Gains
In camera pose estimation, the refinement of the 3D prior led to higher tracking accuracy. On the 7-Scenes dataset, Online3R achieved an Accuracy improvement of ~42% (from 0.068 to 0.039) over the baseline MASt3R-SLAM.

Visual evidence (Figure 2 in the paper) shows that Online3R produces much "cleaner" and more aligned point clouds compared to non-adaptive versions, where misalignments and noise are prominent.
Efficiency Trade-off
While online learning adds overhead, the "lightweight" nature of prompts keeps the system fast. Online3R runs at 10 FPS on an A100, which is sufficient for many robotic applications, whereas full fine-tuning would be impossible in real-time.
Critical Analysis & Conclusion
Takeaway: Online3R proves that the future of 3D foundation models isn't just about "bigger models" or "more data," but about smarter adaptation. By treating the foundation model as a fixed "Geometric Encyclopedia" and the prompts as a "Context-Specific Highlighter," the authors have created a robust path for real-world deployment.
Limitations:
- Computational Cost: 10 FPS is good but might struggle on edge devices (Jetson, etc.).
- Static Scenes: The method currently assumes a static world; moving objects would likely break the local-global consistency constraints.
Future Outlook: The integration of Prompt-based learning with 4D (dynamic) scenes or multimodal inputs (Audio/Tactile) could be the next frontier for this line of research.