本文提出了 Online3R,一个基于几何基础模型(如 MASt3R)的在线连续三维重建框架。通过在冻结的基础模型中引入轻量化可学习的视觉 Prompt(Visual Prompts),该方法能够在测试阶段实时动态适应新场景,显著提升了序列重建的几何一致性。
TL;DR
传统的 SLAM 或三维重建系统在进入新环境时往往表现出“水土不服”,导致几何结构错位或轨迹漂移。Online3R 提出了一个巧妙的方案:不改变预训练模型(如 MASt3R)的本体,而是通过在线学习一小组轻量化的视觉 Prompt,让模型在“边走边看”中学习新场景的特定先验。凭借局部与全局的自监督约束,它在保证实时性的前提下,大幅刷新了单目序列重建的一致性指标。
背景定位:从“预训练”到“终身学习”
近年来,以 DUSt3R 和 MASt3R 为代表的几何基础模型(Geometry Foundation Models)通过在大规模数据集上的预训练,实现了强大的零样本(Zero-shot)重建能力。然而,这些模型在部署时往往是“冻结”的。
作者指出:没有任何一个静态模型能完美覆盖所有现实场景。 特别是在长序列重建中,微小的单帧误差会随时间累积,导致模型在处理回环或重复观测区域时出现严重的不一致性。Online3R 的核心动机就是赋予模型**测试时性能增强(Test-time Adaptation)**的能力。
核心机制:Visual Prompt 与局部-全局自监督
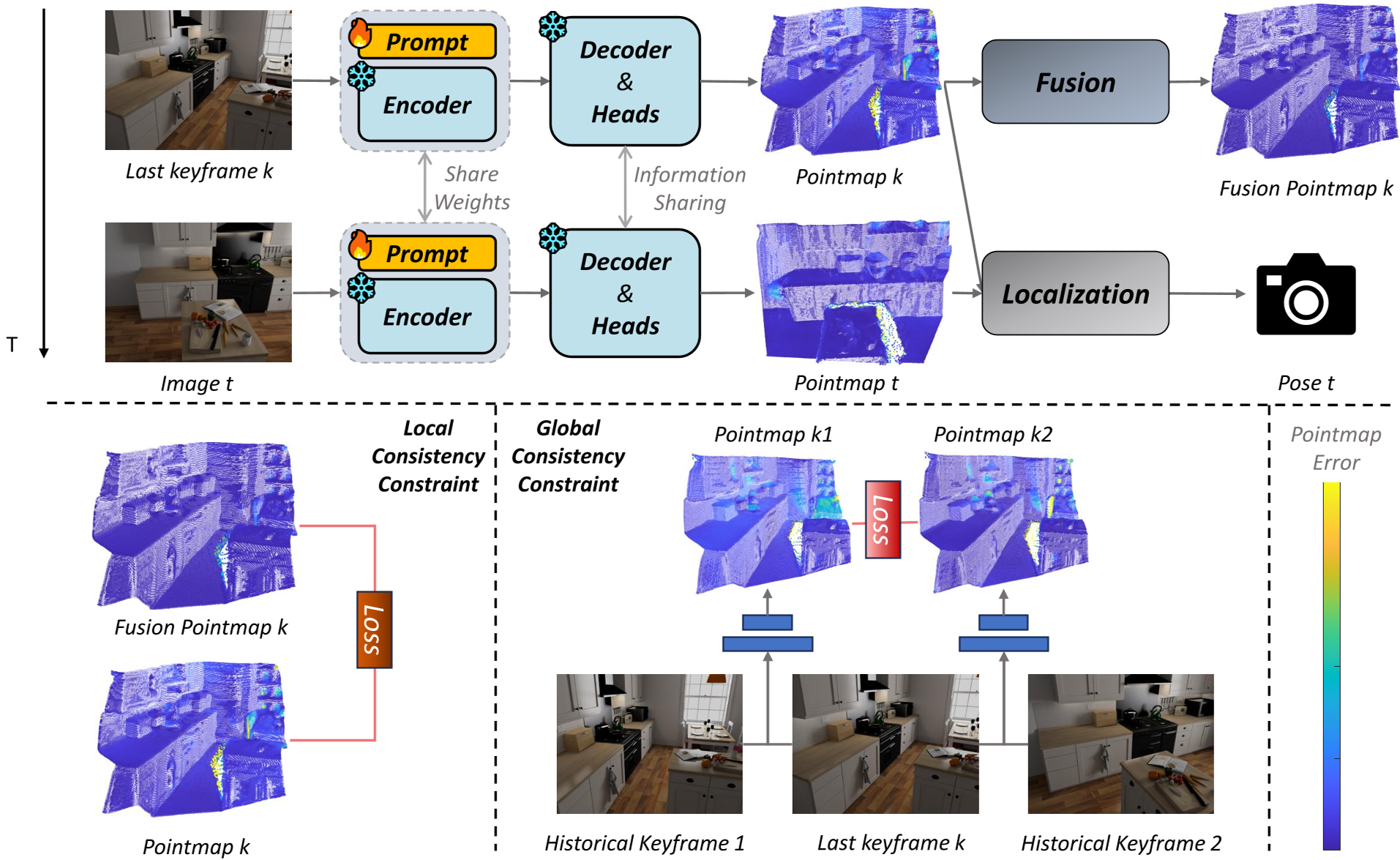
1. 轻量化的视觉适配器
不同于全参数微调(Full Fine-tuning)对算力的恐怖消耗,Online3R 采用了 Visual Prompt Tuning (VPT)。它在 ViT 层的输入序列中插入了一组可学习的 Token。
- 优点:更新参数量极小(不到 1%),且不破坏模型已有的泛化几何知识。
- 物理直觉:Prompt 就像是给模型戴上了一副“针对当前场景定制的眼镜”,调整其特征提取侧重点,以适应当前特定的光照、纹理和物体结构。
2. 局部-全局自监督(Local-Global Consistency)
由于在线运行没有 Ground-truth,作者利用了几何学中的自一致性规律:
- 局部约束 (Local):系统通过滑动窗口将过去多帧的预测结果进行“置信度加权融合”。融合后的几何质量通常高于单帧预测。Online3R 将这个融合结果作为伪真值(Pseudo GT),要求模型在后续处理同区域时产生一致的输出。
- 全局约束 (Global):为了防止模型“见新忘旧”产生漂移,系统会在关键帧池中随机采样。它要求:无论当前帧是与哪一个历史关键帧配对,输出的该帧 3D 坐标图(Pointmap)必须保持一致。
实验战绩:一致性的质跃
在多个公开数据集上的测试表明,Online3R 在精度和一致性上均表现卓越:
- 轨迹精度:在 NRGBD 数据集中,平均 ATE 从基线的 0.090 降至 0.076。
- 重建质量:在 7-Scenes 任务中,精度(Acc)提升明显,甚至在某些指标上击败了拥有全局优化后端(Global Alignment)的离线方法。
 上图清晰展示了在线 Prompt Tuning 的威力:相比于传统的 MASt3R-SLAM,Online3R 的点云拼接更加缜密,没有出现明显的层叠或错位。
上图清晰展示了在线 Prompt Tuning 的威力:相比于传统的 MASt3R-SLAM,Online3R 的点云拼接更加缜密,没有出现明显的层叠或错位。
深度洞察:为什么这很重要?
Online3R 的成功在于其精准捕捉到了基础模型在实际应用中的“缺失环节”——场景特定知识(Scene-specific Prior)。
更有趣的是文中的消融实验(Figure 3):当模型面对完全不重叠的视野时,原始基础模型往往无法有效恢复几何,但 Online3R 的 Prompt 似乎“记住了”场景的隐式表达,能够基于已学习的 Prompt 补全出更合理的结构。这表明,Prompt 不仅是性能优化器,更是一种高效的隐式场景记忆载体。
总结与局限
Online3R 成功地将“大数据驱动的几何先验”与“实时在线的自监督优化”结合在一起。虽然它引入了约 25% 的计算开销(从 13.2 FPS 降至 10 FPS),但换取的一致性提升对于机器人导航和高质量 AR 建模至关重要。
未来的挑战:目前的系统主要针对静态场景。如何在保持一致性的同时,处理动态物体(如行人、车辆)带来的干扰,将是该技术走向真实复杂世界(4D Reconstruction)的关键一步。
本文为学术技术深度解读,旨在提供最前沿的 AI 研究洞察。