OpenSeeker-v2 is an advanced 30B-parameter search agent that achieves State-of-the-Art (SOTA) performance using only Supervised Fine-Tuning (SFT). Developed by an academic team at Shanghai Jiao Tong University, it outperforms industrial models like Tongyi DeepResearch and RedSearcher on 4 major benchmarks including BrowseComp and Humanity’s Last Exam.
TL;DR
OpenSeeker-v2 proves that you don't need the massive compute of Big Tech to build a world-class search agent. By focusing on the granularity and difficulty of training data rather than complex RLHF or Continual Pre-training pipelines, an academic team has set new SOTA records on four major benchmarks using a simple SFT (Supervised Fine-Tuning) approach.
Background: Breaking the "Closed-Door Game"
In the current LLM landscape, "Deep Research" capabilities are the new frontier. However, the recipe for models like OpenAI's Deep Research or Alibaba's Tongyi DeepResearch usually involves a prohibitive pipeline: massive Continual Pre-training (CPT) + SFT + Reinforcement Learning (RL).
The authors of OpenSeeker-v2 challenge this status quo. They argue that the bottleneck isn't the training algorithm, but the informativeness of the trajectories. If an agent is trained on "shallow" data, it will never learn the "deep" intuition needed for complex scholarly or technical searches.
Methodology: Engineering Difficulty
The core philosophy of OpenSeeker-v2 is to force the model to "work harder" during training. They achieved this through three primary modifications to their synthesis pipeline:
1. Scaling Graph Size for Richer Exploration
Instead of generating questions from small, localized data points, they expanded the expansion budget for source subgraphs. This means the model must connect dots across a much larger "information map," naturally leading to multi-hop questions that cannot be answered by a single Google search.
2. Expanding the Tool Set
By increasing the variety of tools (e.g., specialized search, calculators, site-specific scrapers), the agent learns functional flexibility—choosing the right tool for the right sub-task rather than defaulting to generic searches.
3. Strict Low-Step Filtering
This is perhaps the most vital "quality control" measure. The authors discarded any synthetic trajectory that was solved in too few steps (). This ensures the training set is composed entirely of long-horizon problems requiring sustained reasoning.
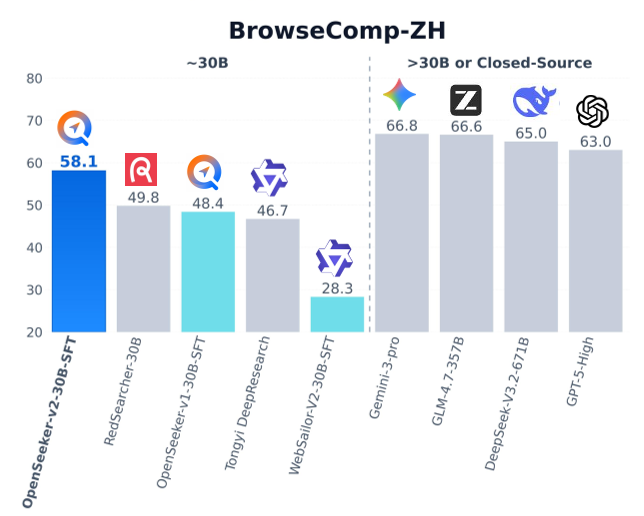
Experiments and Results: SFT vs. The World
Despite being trained on a relatively tiny dataset of 10.6k samples, OpenSeeker-v2 (instantiated from a Qwen3-30B base) achieved stunning results.
Performance Highlights:
- BrowseComp: 46.0% (Beating Tongyi DeepResearch's 43.4%).
- BrowseComp-ZH: 58.1% (An 11.4% lead over the industrial baseline).
- Trajectory Depth: The average tool-call count reached 64.67 steps, far exceeding RedSearcher (36.01) and OpenSeeker-v1 (46.97).
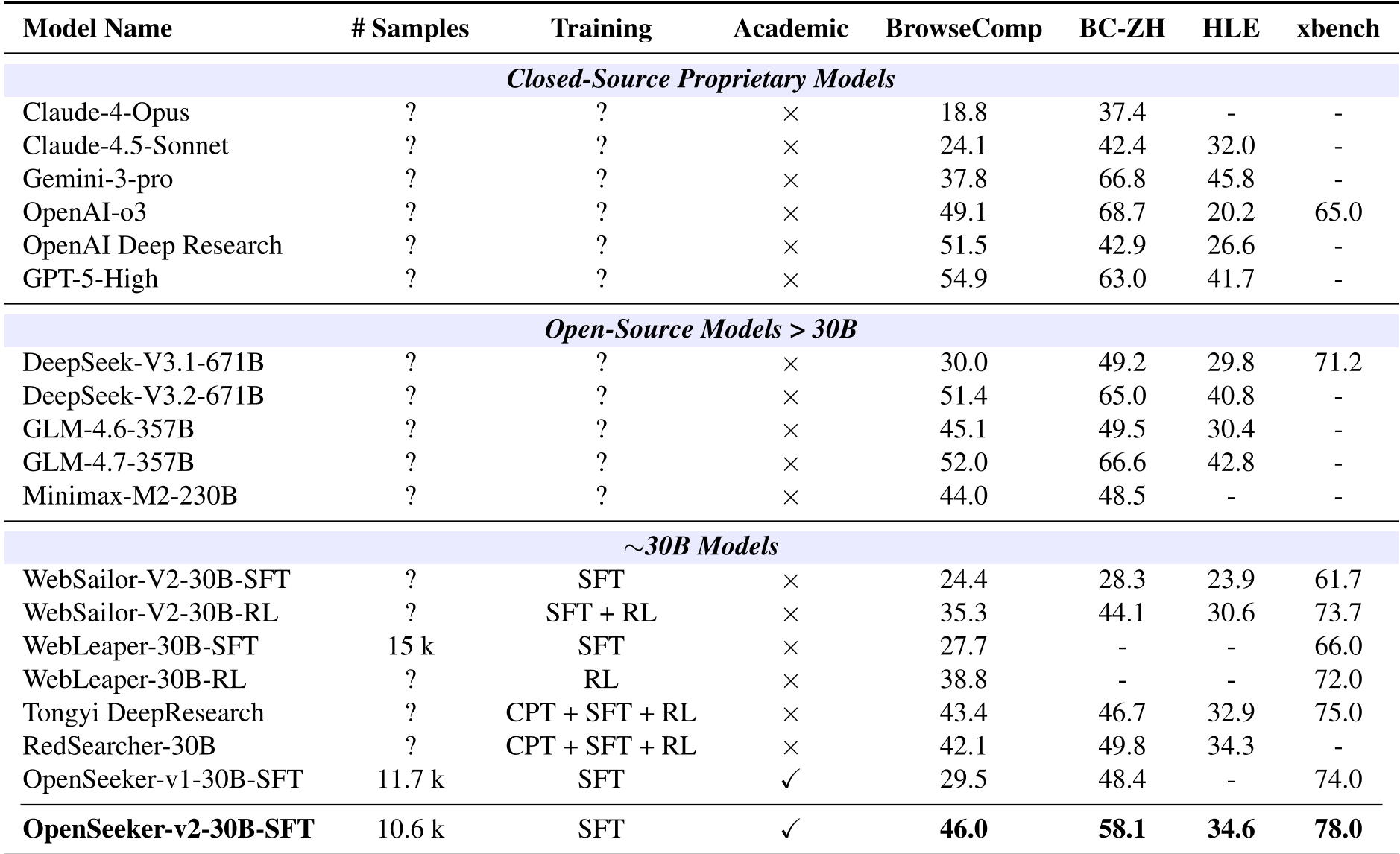
The results in the table above show that OpenSeeker-v2-30B-SFT not only beats models of similar size but even challenges much larger models like DeepSeek-V3.1-671B and Claude-4.5-Sonnet in specific research-oriented benchmarks.
Deep Insight: The Value of Persistent Reasoning
Why does it work? The data suggests that trajectory length is a proxy for agent intelligence. By filtering for long-horizon tasks, the model develops "grit"—the ability to recover from failed searches or ambiguous results without giving up or hallucinating a final answer prematurely.
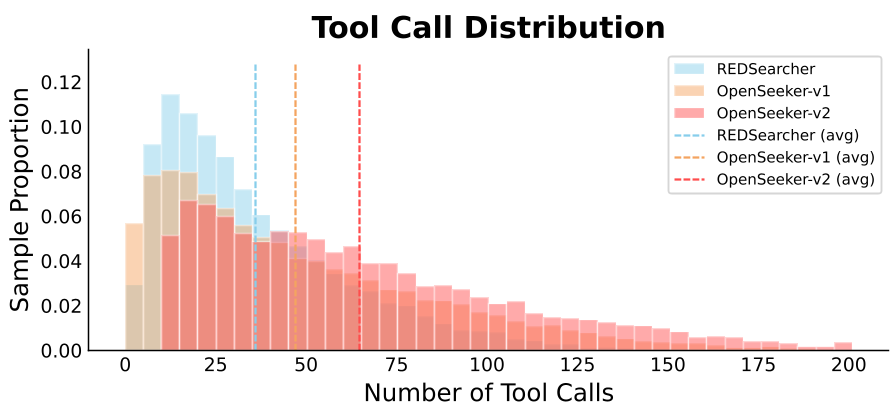 Figure 2: Comparison of average tool calls, showing OpenSeeker-v2's commitment to deeper exploration.
Figure 2: Comparison of average tool calls, showing OpenSeeker-v2's commitment to deeper exploration.
Conclusion & Future Outlook
OpenSeeker-v2 is a triumph for the open-source community. It proves that data synthesis logic is a massive lever that can compensate for smaller compute budgets.
Takeaways for Researchers:
- Stop worrying about RL until your SFT data is truly difficult.
- Use Knowledge Graphs to generate structural multi-hop queries.
- Filter your data by "reasoning density" (i.e., step count).
The team has open-sourced both the weights and the data synthesis findings, paving the way for the next generation of academic search agents.