The paper introduces OpenVLThinkerV2, a generalist multimodal reasoning model trained using a novel Reinforcement Learning objective called Gaussian GRPO (G2RPO). By mapping diverse task rewards to a standard normal distribution via 1D Optimal Transport, it achieves SOTA performance across 18 benchmarks, including a 71.6% score on MMMU and 79.5% on MathVista.
TL;DR
OpenVLThinkerV2 is a generalist multimodal model that tackles the instability of Reinforcement Learning (RL) in diverse visual domains. By introducing Gaussian GRPO (G2RPO)—a method that uses 1D Optimal Transport to map any reward distribution to a standard normal curve—the researchers at UCLA have created a model that outperforms GPT-5 and Gemini 2.5 Pro on benchmarks like DocVQA and MathVista.
The "Reward Topology" Nightmare
Training a single model to handle both visual grounding (where rewards are continuous IoU scores) and mathematical reasoning (where rewards are sparse and binary) is an optimization nightmare.
Current state-of-the-art RL objectives like GRPO rely on linear normalization (subtracting mean, dividing by standard deviation). In a multi-task setting, this leads to:
- Inter-task Imbalance: High-variance tasks dominate the gradients, while low-variance tasks are ignored.
- Sensitivity to Outliers: "Lucky" responses with abnormally high rewards can inflate the variance, suppressing the learning signal for all other samples.
- Entropy Pathologies: Models either "overthink" simple perception tasks (entropy explosion) or become "lazy" and over-confident in reasoning (entropy collapse).
Methodology: Gaussian G2RPO
The core innovation is G2RPO. Instead of linear scaling, it uses Optimal Transport (OT) to find a mapping function that transforms the empirical reward distribution of any task into a Standard Normal Distribution .
1. Non-linear Distributional Matching
By utilizing the Cumulative Distribution Function (CDF), G2RPO assigns advantages based on the relative rank of a response. This mathematically:
- Caps Outliers: Extreme values are mapped to the tails of the Gaussian, preventing gradient spikes.
- Ensures Equity: Every task, regardless of its original reward scale, produces the same gradient magnitude.
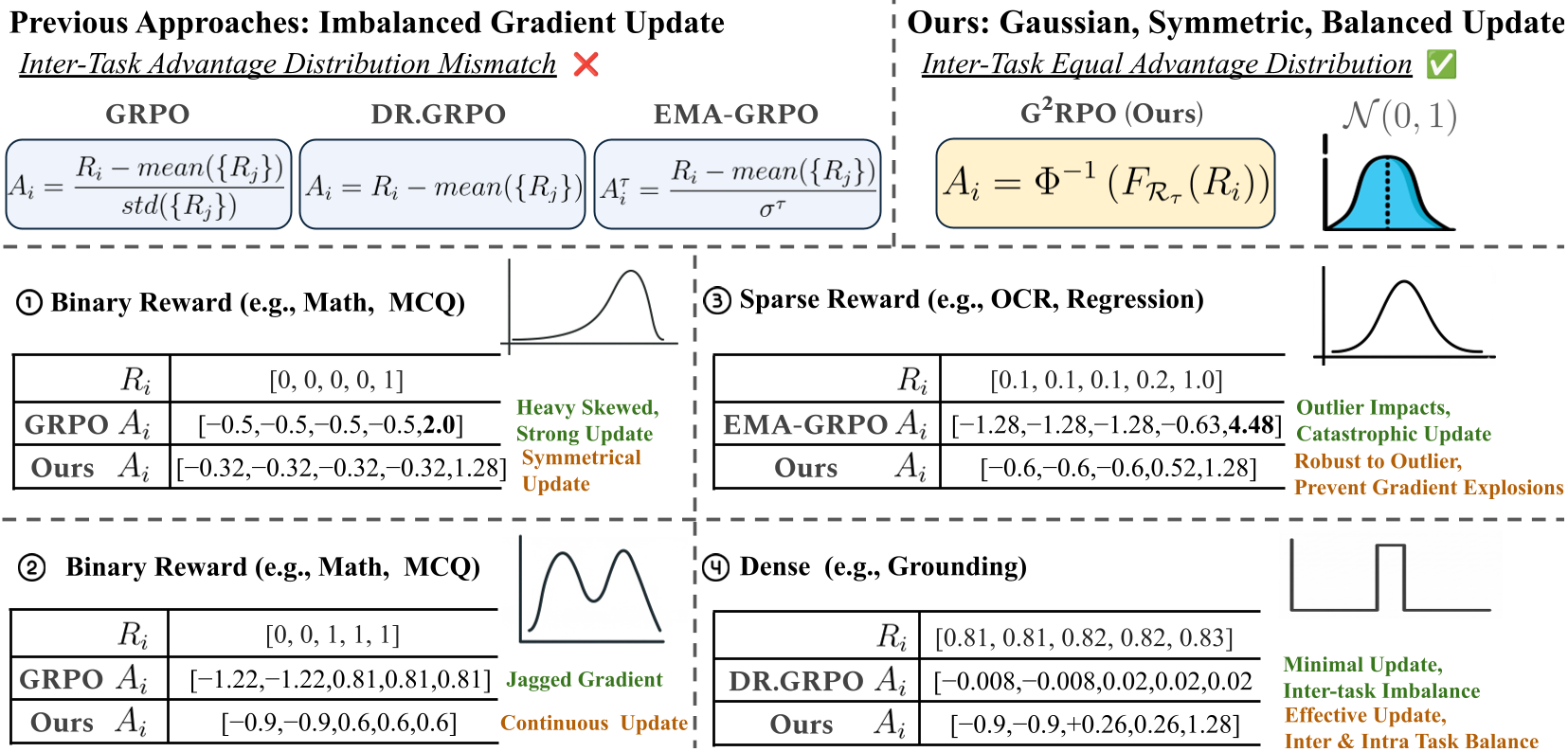 Figure: Comparison of G2RPO against prior methods. It provides intrinsic robustness and uniform variance across tasks.
Figure: Comparison of G2RPO against prior methods. It provides intrinsic robustness and uniform variance across tasks.
2. Task-level Shaping
To address the divergent needs of perception and reasoning, the authors introduced two "shaping" mechanisms:
- Length Shaping: A trapezoidal reward envelope that encourages the model to generate long "Chain-of-Thought" (CoT) for math, but penalizes "overthinking" (hallucinated verbosity) for OCR and grounding tasks.
- Entropy Shaping: A margin-based penalty that keeps the model within a "Goldilocks zone" of exploration, preventing the incoherent generation (explosion) or premature convergence (collapse).
 Figure: Length dynamics during training. G2RPO successfully elicits reasoning chains while enforcing concise visual grounding.
Figure: Length dynamics during training. G2RPO successfully elicits reasoning chains while enforcing concise visual grounding.
Experiments and Results: Slaying the Giants
OpenVLThinkerV2 was evaluated on 18 benchmarks. Despite being an 8B-parameter model, it consistently outperformed proprietary frontier models.
- Math & Science: Surpassed GPT-4o on MMMU (71.6%) and MathVista (79.5%).
- Document Understanding: Achieved 911 on OCRBench, outperforming GPT-5 and Gemini 2.5 Pro.
- Visual Grounding: Reached 93.4% on RefCOCO, proving that it hasn't lost its "low-level" perception skills while learning "high-level" reasoning.
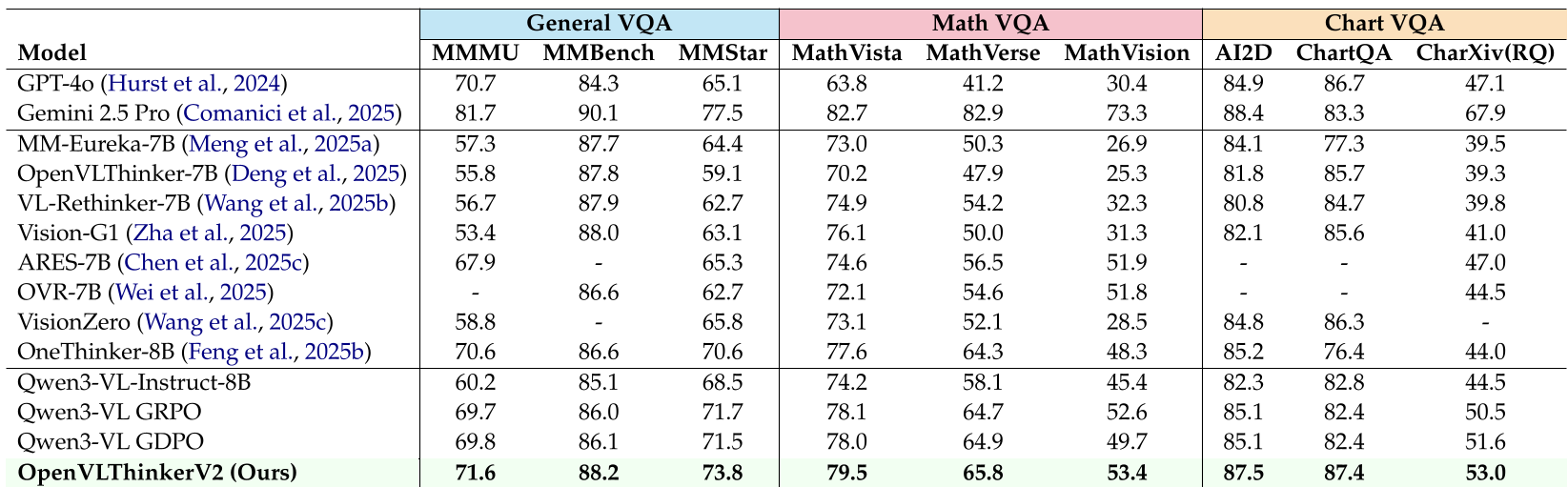 Figure: Evaluation across General, Math, and Chart VQA. OpenVLThinkerV2 leads the open-source pack.
Figure: Evaluation across General, Math, and Chart VQA. OpenVLThinkerV2 leads the open-source pack.
Critical Insight: Why G2RPO Matters
The shift from linear normalization to distributional matching via Optimal Transport is a profound change in how we think about RL for LLMs. It acknowledges that "reward" is not an absolute physical value but a relative signal. By forcing the advantage into a Gaussian shape, the researchers have created a universal "exchange rate" for gradients across different task domains.
Conclusion & Future Work
OpenVLThinkerV2 proves that intelligent RL objectives can compensate for smaller model sizes. The G2RPO framework is naturally suited for other heterogeneous domains like SWE-bench (coding) or GUI navigation. The next frontier will likely involve automated hyperparameter search for the length and entropy envelopes to remove the need for empirical "shaping" entirely.
Takeaway: If you are training multi-task RL models, stop standardizing your rewards—start mapping them to a Gaussian.