本文提出了 OpenVLThinkerV2,这是一个通用的多模态推理模型。其核心贡献是引入了 Gaussian GRPO (G2RPO) 强化学习目标函数,通过非线性分布匹配将各任务的 Advantage 强制收敛至标准正态分布,从而在 18 个多模态基准测试中取得 SOTA 性能,超越了 GPT-4o 和 Gemini 2.5 Pro。
TL;DR
UCLA 的研究团队发布了 OpenVLThinkerV2,这是一款通过强化学习(RL)大幅进化的多模态大模型。它通过独创的 G2RPO(Gaussian GRPO) 技术,利用高斯分布强制对齐了不同视觉任务的奖励信号,解决了多任务训练中的梯度失衡问题。模型在 18 个榜单上刷榜,在数学、文档理解和空间推理等高难度领域展现出碾压 GPT-4o 和预览版 GPT-5 的实力。
1. 痛点:为什么多模态 RL 这么难?
在构建通用多模态模型时,研究者通常面临一个尴尬的局面:
- 奖励拓扑的极端差异:数学 VQA 任务的奖励往往是二元的(对或错),而视觉定位(Grounding)任务的奖励是连续的 IoU 分数。传统的 GRPO 使用线性标准差归一化(Standardization),这会导致高方差任务主导梯度更新,而低方差任务被边缘化。
- “离群值”毒素:如果某个样本因为“走运”得到了极高分,线性缩放会放大这种噪声,导致梯度爆炸。
- 感知与推理的矛盾:模型在需要精细感知的 OCR 任务中容易“过度思考”产生幻觉,而在复杂推理任务中又可能“浅尝辄止”。
2. 核心技术:G2RPO — 强化学习的“降维打击”
为了解决奖励不稳定的问题,作者从数学底层出发,将 Advantage 估计建模为一个 一维最优传输(Optimal Transport) 问题。
2.1 高斯分布的神奇映射
不同于传统的减均值除方差,G2RPO 采用非线性映射:
- 它首先计算当前任务奖励的百分比排名(Rank)。
- 随后通过标准正态分布的逆累计分布函数(Inverse CDF),将排名直接映射到 。
直觉: 无论你的原始分数波动多大,映射后的 Advantage 分布永远是完美的“钟形曲线”。这意味着即使出现极端的离群回馈,它也会被强行压制在正态分布的高分挡位,而不会因线性放大搞崩模型。
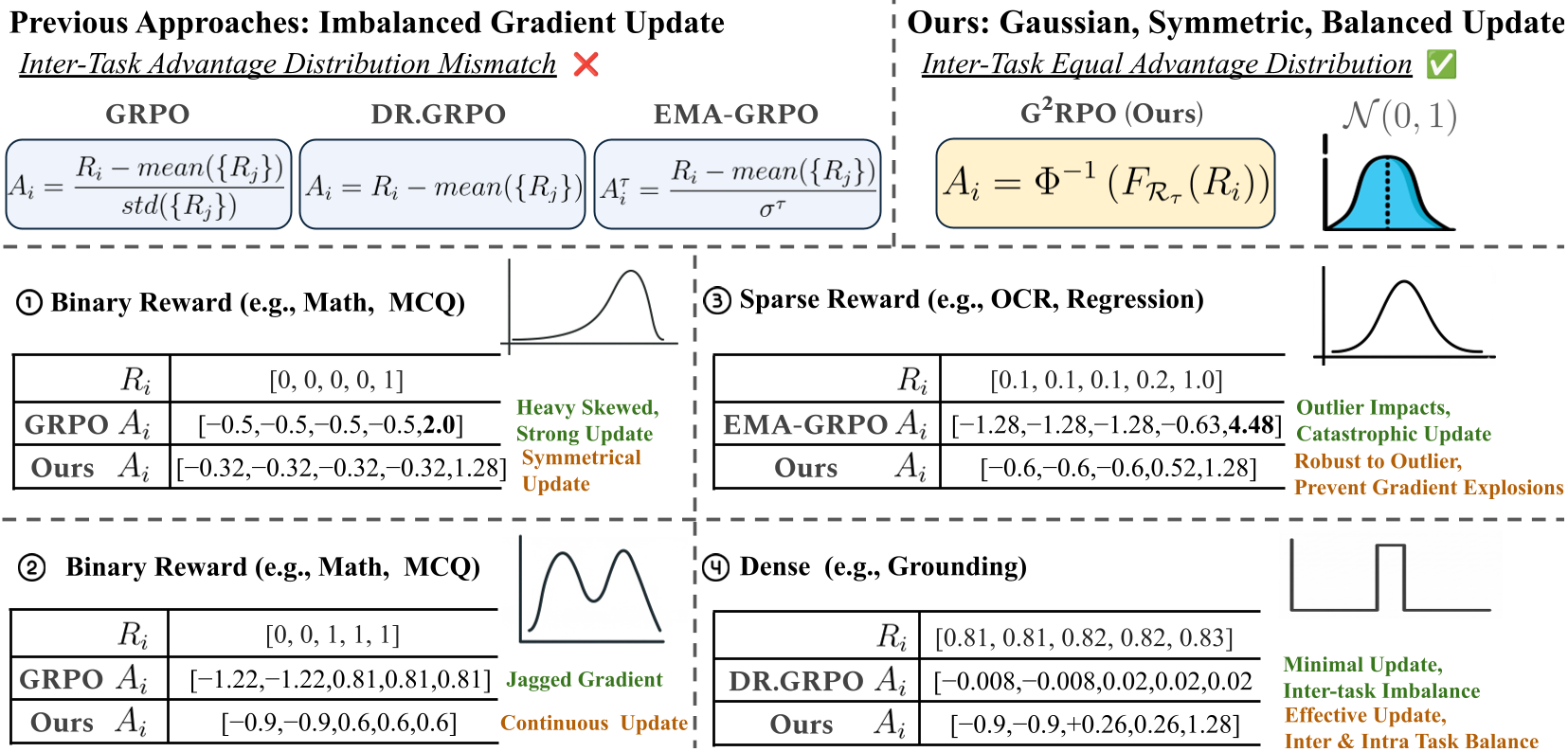 图1:标准 GRPO、Dr.GRPO 与本文 G2RPO 的对比。可以看到 G2RPO 提供了天然的离群值鲁棒性和任务间梯度公平性。
图1:标准 GRPO、Dr.GRPO 与本文 G2RPO 的对比。可以看到 G2RPO 提供了天然的离群值鲁棒性和任务间梯度公平性。
3. 行为微操:长度与熵的高度自动控制
不仅在损失函数上发力,OpenVLThinkerV2 还通过“行为塑造”来平衡感知与推理:
- 长度塑造(Length Shaping):
- 对于推理任务:设置奖励陷阱,鼓励模型写出长思维链(CoT)。
- 对于视觉任务(如 OCR):强制简洁输出。图示显示,这种机制让推理任务在经历初期的性能震荡后,迅速收敛到更深层的逻辑输出。
- 熵塑造(Entropy Shaping):
- 针对推理任务预防“熵爆炸”(防止生成语无伦次的废话)。
- 针对视觉任务预防“熵崩塌”(防止模型过早锁定某个 token 停止探索)。
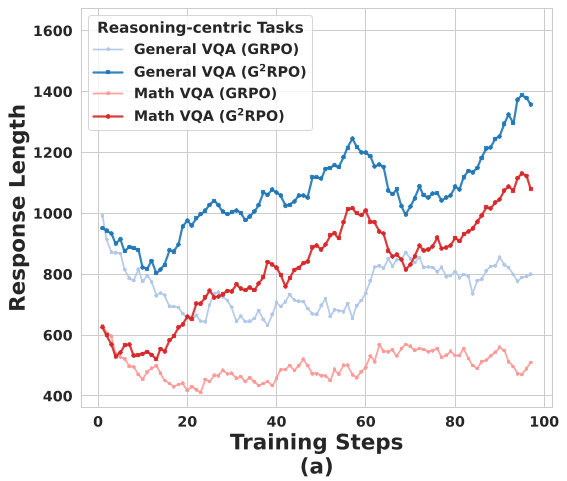 图2:G2RPO 有效引导了不同任务的生成长度收敛,提升了视觉定位的准确性并减少了推理过程的幻觉。
图2:G2RPO 有效引导了不同任务的生成长度收敛,提升了视觉定位的准确性并减少了推理过程的幻觉。
4. 暴力性能:拳打 GPT-4o,脚踢 GPT-5
实验结果相当震撼。在 8B 规模的基础上,OpenVLThinkerV2 在多个关键领域实现了跨代超越:
- 通用视觉推理:MMMU 达到 71.6%,超越 GPT-4o (70.7%)。
- 数学与图表:MathVista 79.5%,比基准 Qwen3-VL 提升了 5 个点以上。
- 专业文档理解:在 OCRBench 上达到 911 分。作为对比,号称最强的 GPT-5 仅为 810 分,Gemini 2.5 Pro 为 866 分。
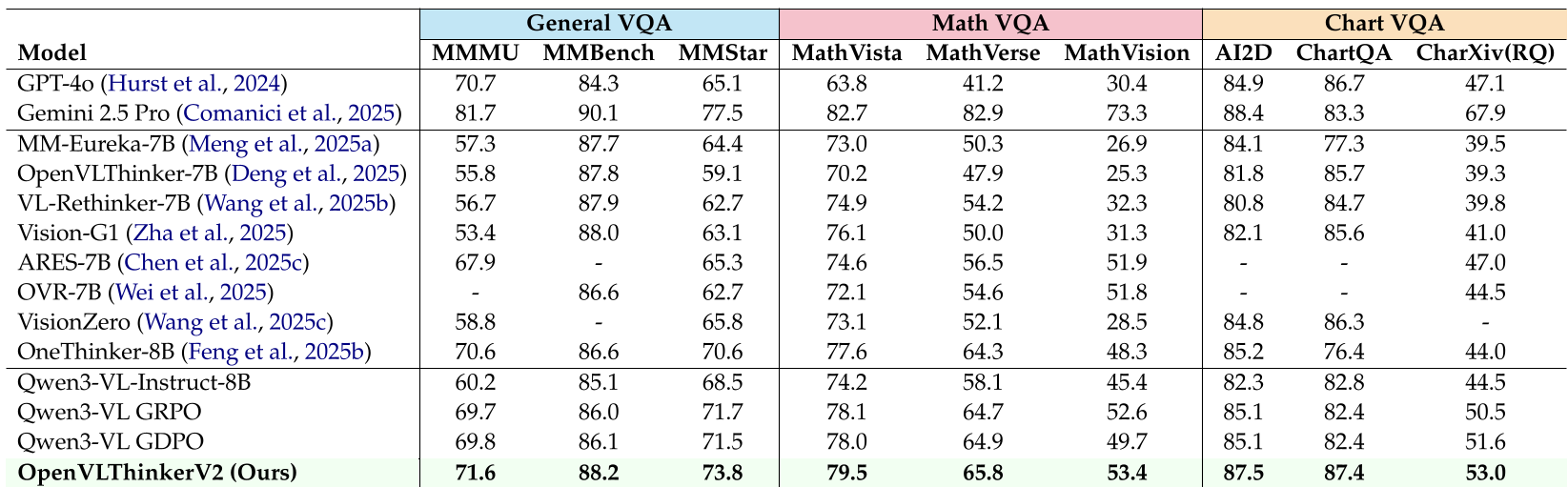 表1:在多项视觉推理任务中,OpenVLThinkerV2 稳坐 open-source SOTA 宝座,并频繁超越顶级的闭源模型。
表1:在多项视觉推理任务中,OpenVLThinkerV2 稳坐 open-source SOTA 宝座,并频繁超越顶级的闭源模型。
5. 深度洞察:为什么这篇论文值得读?
这篇论文的真正价值在于它对 Reinforcement Learning Post-training 的细颗粒度控制。研究者不再单纯依赖“喂更多高质量数据”,而是通过 Distributional Matching(分布匹配) 这种更高级的统计学手段,解决了多任务学习中根深蒂固的权衡难题。
局限性分析: 虽然 G2RPO 表现优异,但其目前依赖于一组预定义的超参数(如长度阈值 )。未来的研究可能会探索如何根据任务难度自动学习这些约束边界。
总结
OpenVLThinkerV2 证明了:通过数学上对奖励分布的精确微操,我们可以让一个 8B 的模型在特定复杂推理领域战胜参数量巨大的闭源巨头。这为开源社区开发“小而精”的多模态专家模型指明了方向。
本文由资深学术技术主编重构。更多细节请参考 UCLA 官方仓库。