本文提出了 P2O (Joint Policy and Prompt Optimization) 框架,通过将提示词优化(Prompt Optimization)与强化学习(RL)协同,解决了推理任务中“硬样本”导致的训练受阻问题。该方法在 Qwen3-4B 模型上实现了 AIME24 准确率提升 12.9%,显著刷新了中量级模型的推理 SOTA。
TL;DR
在强化学习提升 LLM 推理能力的浪潮中,硬样本(Hard Samples)始终是导致模型性能瓶颈的“毒药”。当模型在 16 次乃至 64 次采样中都无法完成一次正确的证明题时,强化学习便失去了监督信号。本文提出的 P2O (Joint Policy and Prompt Optimization) 框架,通过遗传算法(GEPA)动态生成“提示词导火索”,引燃硬样本的搜索空间,再通过上下文蒸馏将这份智慧刻入模型参数。
背景定位
目前 Reasoning Alignment 的主流是 RLVR(如 DeepSeek-R1 采用的 GRPO)。然而,纯粹的 RL 极易陷入局部最优(Local Optima)。P2O 并不满足于在现有的概率凸起处修修补补,而是试图在“奖励沙漠”中通过提示词优化强行开辟出一条通往正确答案的路径。
痛点深挖:消失的梯度与硬样本的饥饿
在传统的 GRPO 中,优势函数(Advantage)依赖于组内推理轨迹的相对得分。
- 逻辑困境:如果对于某个数学题,模型跑了 K 个候选答案全是错的,那么
r_mean为 0,每个轨迹的Advantage也几乎为 0。 - 后果:硬样本在训练中被事实性地抛弃了,模型只能在简单题目上“刷分”,导致其推理上限被锁死。
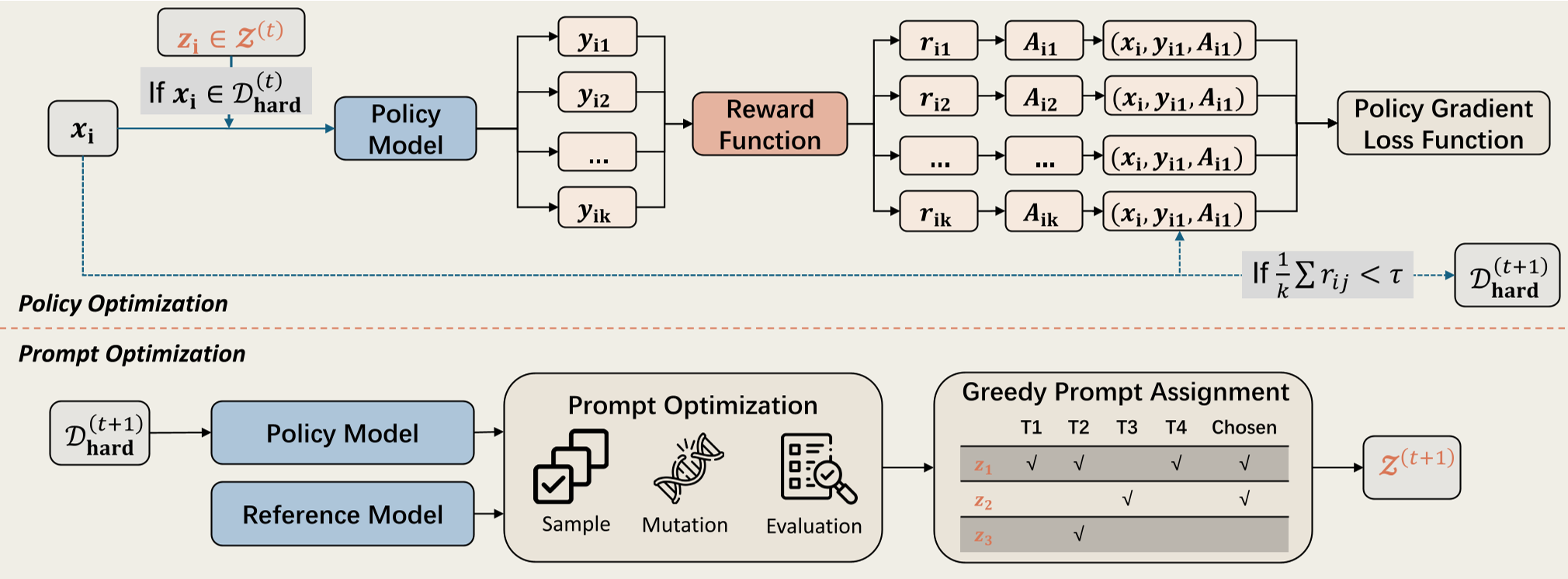
核心方法论:P2O 的“双相周期”
P2O 巧妙地设计了一个交替优化方案:
1. 策略优化与上下文蒸馏 (Context Distillation)
这是 P2O 的核心 Insight。为了避免模型在推理时产生“提示词依赖”(即离开提示词就不会做题),作者提出:生成时用提示词,计算梯度时不用。
- 公式解读:。注意这里的 是在带提示词的 环境下生成的,但 的输入仅仅是原始查询 。这强迫模型在没有任何暗示的情况下,内化那条复杂的推理链路。
2. 进化提示词优化 (GEPA)
当模型在当前策略下遇到无法攻克的题目时,启动 GEPA 算法。它利用一个“反射模型”(Reflective LLM)观察错误记录,像生物进化一样变异提示词模板,直到发现能让模型“开窍”的模板 。
实验与结果:刷新中量级模型上限
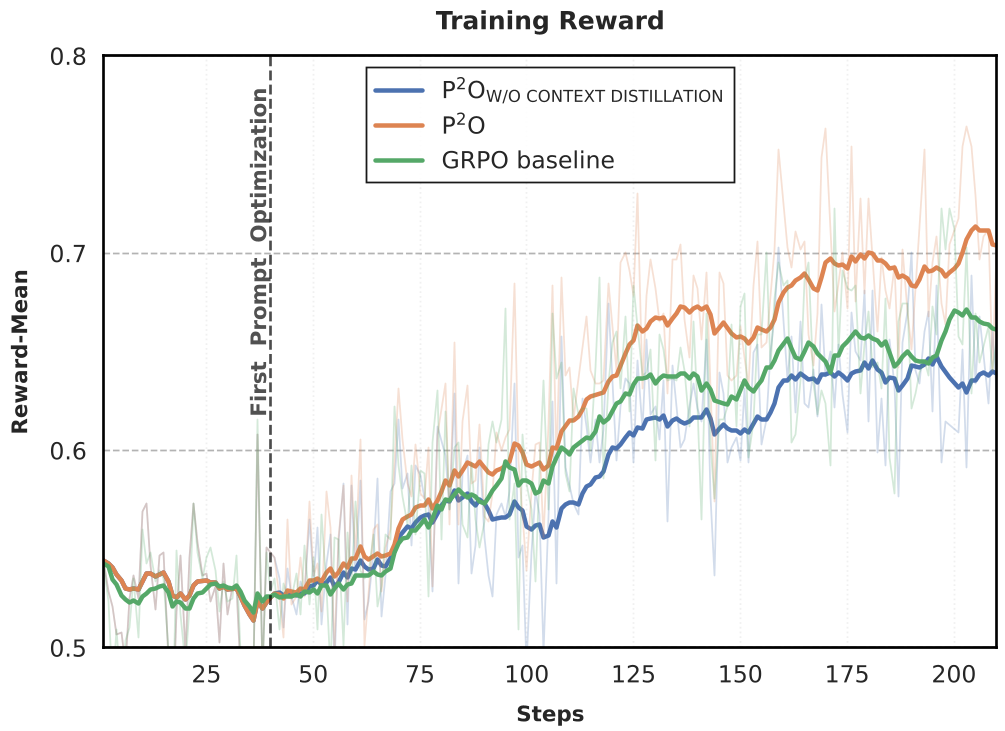
实验采用了 Qwen3-4B 作为 Backbone。在只有 5000 条训练数据的情况下,P2O 展现了极强的泛化能力。
- SOTA 对比:在 DeepScaler-5K 数据集上,AIME24 准确率从 GRPO 的 46.9% 飞跃至 59.8%。
- 学习曲线分析:如下图所示,P2O 的训练奖励(红色)始终高于基线,这意味着模型在训练过程中从未停止对新知识的“进食”。
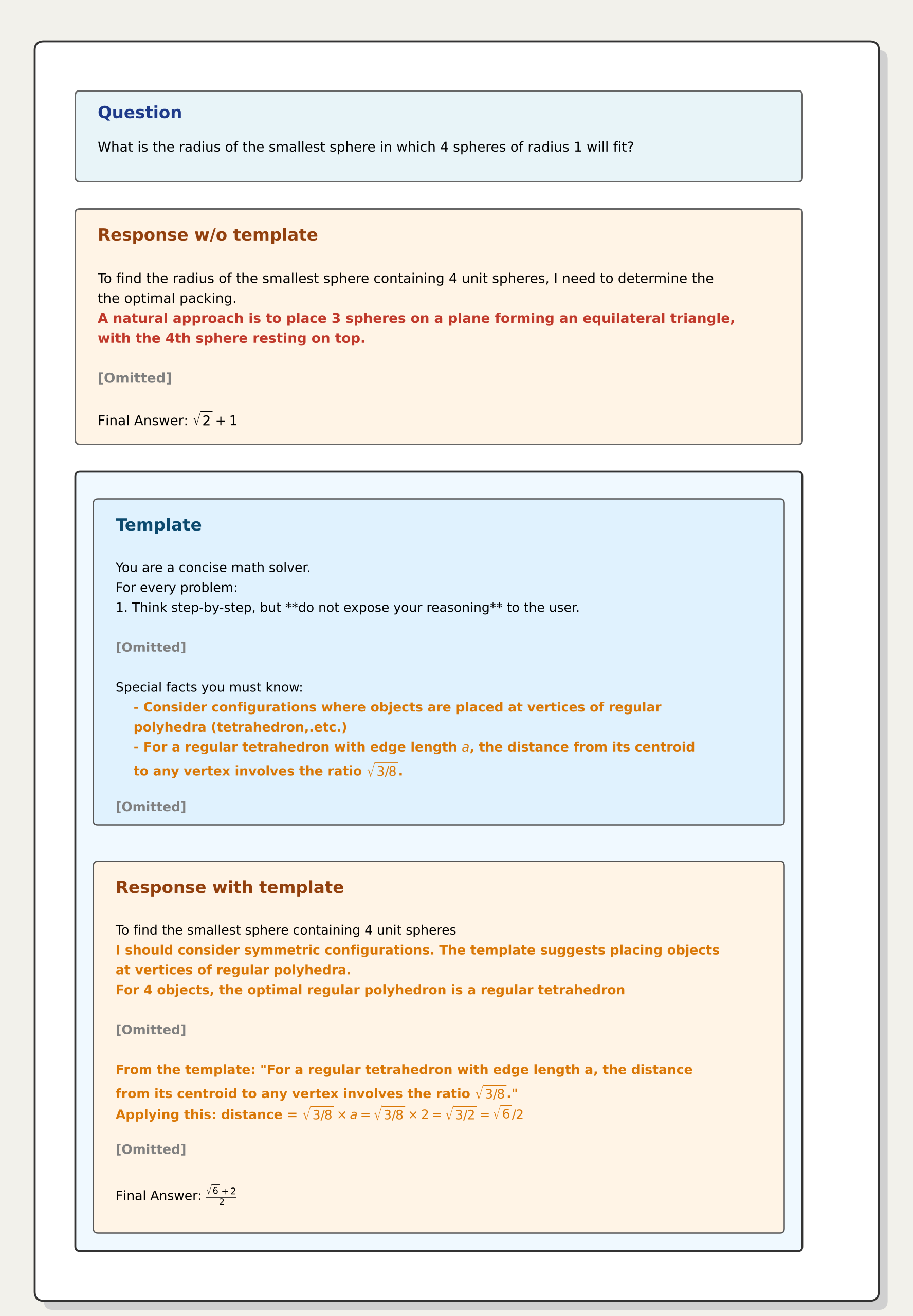
深度洞察:提示词是步进器,参数是蓄电池
P2O 的成功实际上论证了一个哲学观点:LLM 现有的参数中往往潜藏着正确答案,只是在特定分布(Manifold)下难以触达。
- 定性分析:在处理一个关于“四个单元球体外接球半径”的几何题时,原模型会陷入“平面排列”的思维定式。而进化出的提示词通过引入“正四面体中心”等核心概念,强行改变了模型的 Top-K 采样空间,一旦正确的 Trajectory 被抓到,蒸馏机制就会确保这种“顿悟”被永久固化。
总结与未来启示
P2O 为解决强化学习的探索瓶颈提供了一个极其优雅的范式。
- 局限性:提示词进化的过程依然依赖一个强大的 Reflection Model(如 Kimi-K2 或自我反射),这带来了额外的计算开销。
- 结论:它证明了“提示词工程”不应仅仅是 Inference-time 的调优手段,更应该是 Training-time 的优化目标。未来,这种参数与指令协同进化的路径,可能是通往通用推理能力的必经之路。