PackForcing is a unified framework for autoregressive video diffusion that enables long video generation (up to 120s) using only short-video (5s) training. It introduces a three-partition KV-cache strategy and a 128x spatiotemporal compression module, achieving state-of-the-art results on VBench with a strictly bounded memory footprint of ~4GB.
TL;DR
Training a model on 5-second clips typically limits its "imagination" to short durations. PackForcing shatters this limitation, enabling 120-second high-fidelity video generation using a novel three-partition KV cache. By compressing history by 128x and using dynamic "Top-k" retrieval, it maintains global coherence and rich motion while keeping GPU memory usage at a constant ~4GB.
The Dilemma: Context vs. Memory
Autoregressive video generation is a game of memory. To keep a video "on track" (preventing semantic drift), the model needs to remember what happened a minute ago. However, video tokens are dense. For a 2-minute video, the KV cache would balloon to ~749K tokens (~138 GB), far exceeding the capacity of a single GPU.
Previous works either:
- Truncate history: Leading to "amnesia" where the model forgets the initial prompt.
- Sliding Windows: Losing long-range consistency and causing background "warping."
PackForcing argues that we don't need to remember everything at full resolution; we just need to remember the right things.
Methodology: The Three-Partition Architecture
The core innovation is the decomposition of the generation history into three functional zones (Figure 2):
- Sink Tokens (The Anchors): The first few frames are kept at full resolution. They act as semantic anchors (similar to StreamingLLM) to ensure the scene layout and subject identity remain stable.
- Compressed Mid Tokens (The Archive): The bulk of the video is compressed via a Dual-Branch module. It achieves a 128x volume reduction (32x token reduction) by fusing High-Resolution (3D Convolutions) and Low-Resolution (VAE re-encoding) pathways.
- Recent Tokens (The Working Memory): The last few frames are kept at full resolution to ensure the current movement is smooth and lacks flickering.
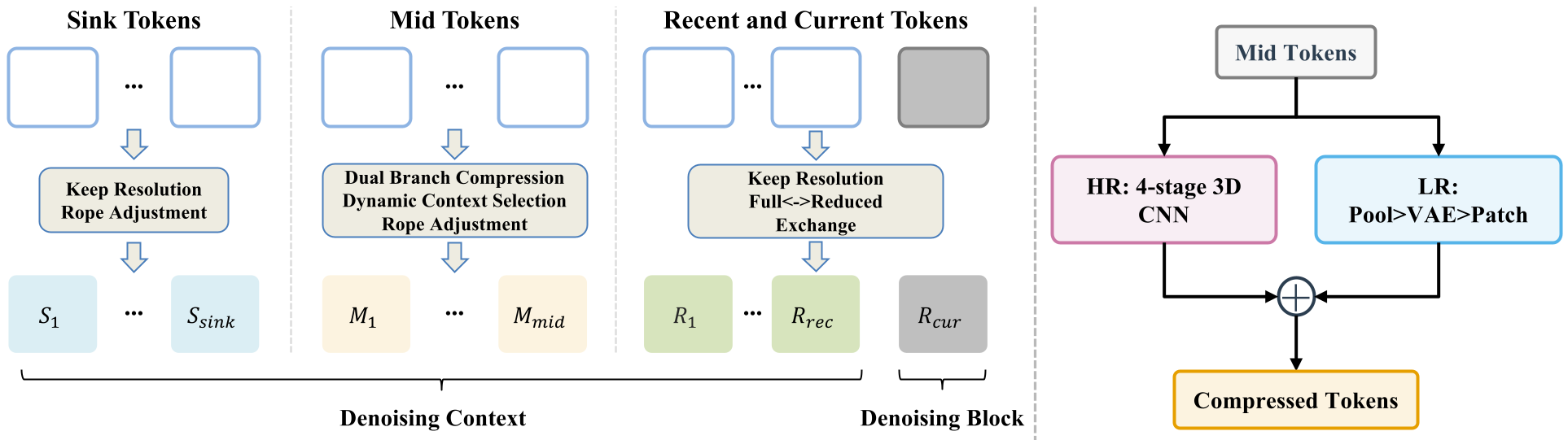
Solving the "Hole in Time": Incremental RoPE
When you dump old tokens to save space, you create a "positional gap" in the timeline. Standard Rotary Positional Embeddings (RoPE) break down here. PackForcing solves this with Incremental RoPE Adjustment. By applying a multiplicative temporal-only rotation to the Sink keys, they "slide" the relative time back into alignment without recomputing the entire cache.
Experiments: 24x Temporal Extrapolation
One of the most impressive feats of PackForcing is its ability to generalize. Despite being trained on 5-second clips, it generates 120-second videos with almost zero degradation in Subject Consistency.
| Metric | CausVid | Self-Forcing | PackForcing (Ours) | | :--- | :---: | :---: | :---: | | Dynamic Degree | 50.00 | 30.46 | 54.12 | | Subject Consistency | 83.24 | 74.40 | 92.84 | | Overall Consistency| 23.13 | 23.42 | 26.05 |
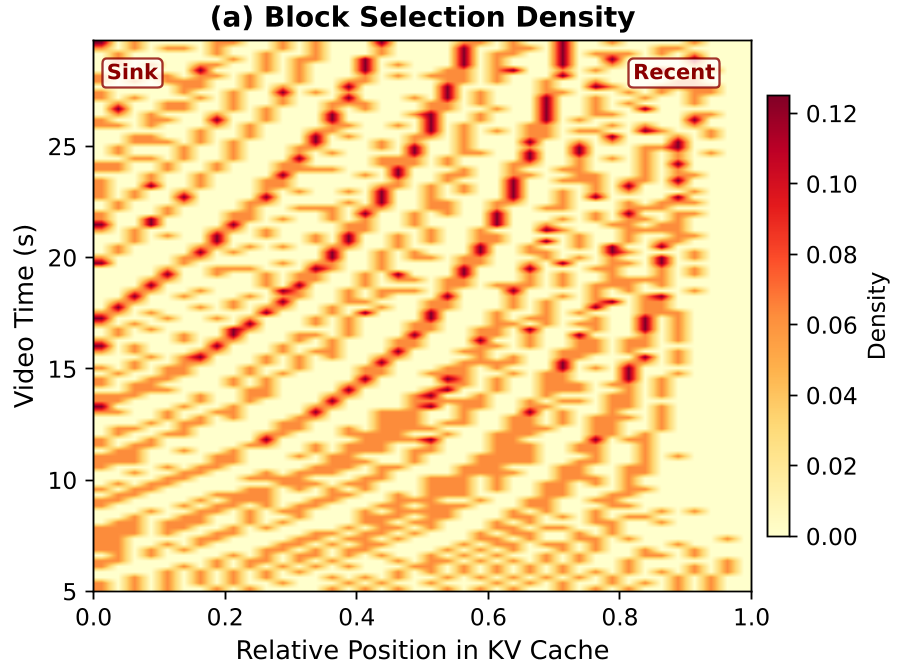 Figure: Attention patterns justify the design—attention is sparse but spans the entire history, proving that FIFO eviction is suboptimal.
Figure: Attention patterns justify the design—attention is sparse but spans the entire history, proving that FIFO eviction is suboptimal.
Deep Insight: Why Why Short Video Training Suffices?
The authors provide a profound insight: Representation Compatibility. By training the compression layer end-to-end within the latent subspace, the Transformer learns to treat compressed "Mid" tokens and full-res "Recent" tokens as part of the same semantic continuum. This prevents the "distribution shift" that usually occurs when a model encounters longer sequences than it saw during training.
Conclusion & Future Outlook
PackForcing proves that we can achieve "unbounded" video generation on standard consumer hardware. While current results show a slight trade-off in subject preservation compared to heavy-static models (like LongLive), the Motion Richness (Dynamic Degree) is unparalleled.
The future of video AI isn't just about bigger GPUs—it's about smarter memory management.
Main Takeaway: By managing the KV cache as a hierarchical memory system rather than a flat buffer, PackForcing enables high-fidelity, long-duration video synthesis with constant-time complexity.