Perceptio is a perception-enhanced Large Vision-Language Model (LVLM) that integrates 2D semantic segmentation and 3D depth estimation directly into its autoregressive output sequence. By generating explicit spatial tokens before producing text, it achieves state-of-the-art performance on RefCOCO/+/g benchmarks and improves spatial reasoning accuracy on HardBLINK by 10.3%.
TL;DR
While Large Vision-Language Models (LVLMs) can describe an image with poetic detail, they often fail to tell you which object is closer to the camera. Perceptio fixes this by turning spatial perception into an explicit intermediate step. By generating 2D segmentation and 3D depth tokens before the text response, Perceptio acts as a "Spatial Chain-of-Thought" engine, setting new SOTA records on RefCOCO and drastically improving depth reasoning on benchmarks like HardBLINK.
Deep Dive into the Motivation: The "Blindness" of Current LVLMs
Even the most advanced LVLMs (like InternVL or LLaVA) suffer from a lack of "Spatial Intelligence." They treat images as a flat bag of visual features. Previous attempts to fix this usually fell into two camps:
- Specialist Pipelines: Models that only do segmentation or depth but can't talk.
- Implicit Learners: Large models that hope spatial awareness "emerges" from scale—which the authors prove it doesn't.
Perceptio’s core insight is that perception should be a first-class citizen of the language objective. If a model is forced to explicitly "draw" the depth and boundaries of a scene before answering, its final text response will be grounded in physical reality, not just statistical linguistic patterns.
Methodology: The Perception-Enhanced Sequence
Perceptio introduces a unified architecture that routes visual signals through three pathways: a standard image encoder, a frozen SAM2 encoder for 2D cues, and a VQ-VAE depth codebook distilled from "Depth Anything V2."
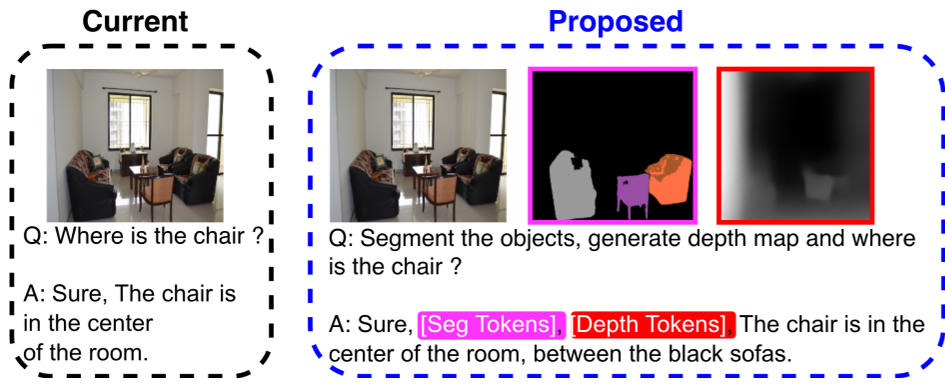
The Spatial Chain-of-Thought
The model generates a sequence follows this template:
[seg tokens] + [depth tokens] + [text tokens]
By generating these in order, the autoregressive nature of the LLM ensures that the final text is conditioned on the segmentation and depth it just "saw."
Solving the "Discrete vs. Continuous" Gap
One of the paper's key technical contributions is the Soft Depth Reconstruction. Standard VQ-VAE uses hard index selection, which is non-differentiable. Perceptio uses a soft-merging technique where codebook embeddings are weighted by predicted probabilities, allowing gradients to flow back into the LLM.
To keep the LLM from hallucinating meaningless tokens, they introduced a Composite Depth-Token Loss:
- Marker Loss: Ensures the
[d_start]and[d_end]tokens appear where they should. - Token Loss: Ensures the depth values are accurate compared to the teacher model.
- Count Loss: Penalizes the model if it generates too few or too many depth tokens.
Experiments and Results: SOTA Performance
Perceptio-8B dominates across the board. In Referring Expression Segmentation (RES), it outperformed the previous leader, Sa2VA, by significant margins.

In the HardBLINK depth reasoning task—where models must decide which of several points is closest to the camera—Perceptio-8B achieved 71.0% accuracy, a massive 10.3% jump over LLaVA-Aurora. This proves that the explicit depth tokens aren't just "show," they are actually informing the model's internal logic.

Critical Insights: The Multi-Modal Trade-off
The ablation studies title an interesting story:
- Perception is Vital: Removing depth tokens collapsed HardBLINK accuracy by 25.8%.
- Synergy: 3D depth and 2D segmentation are complementary; removing segmentation dropped MMBench and SEED-Bench scores, showing that "geometry alone is not enough—you need labels."
- The Optimization Tension: Interestingly, the authors noted that removing depth slightly improved general VQA. This suggests a "tax" on the model's capacity when learning to generate precise geometric tokens—a hurdle for future multi-task curriculum learning to solve.
Conclusion
Perceptio marks a shift from models that merely look at images to models that perceive them. By integrating dense 2D and 3D signals into the text stream, Amazon researchers have provided a blueprint for more physically grounded AI. Future work in video and robotic manipulation will likely build on this "perception-as-tokens" approach.