PerceptionComp 是一个专门为长程、以感知为核心的视频推理任务设计的基准测试集。它包含 1,114 个高质量的人工标注五选一问题,涵盖 279 个高复杂度视频,旨在评估多模态大模型(MLLM)在处理需要反复回看、多步骤证据收集任务时的性能。
TL;DR
清华、南洋理工与华盛顿大学联合发布了 PerceptionComp,这是一个针对 MLLM 的“地狱级”视频感知基准。它不同于以往靠长视频刷记忆力的测试,而是通过高密度的场景快照和多步组合逻辑,强制模型必须像人类专家一样“反复回看”才能找到答案。目前最尖端的模型(如 Gemini-3-Flash, GPT-o3)在此基准上的准确率均徘徊在 45% 左右,揭示了当前 AI 在细粒度视觉推理上的巨大鸿沟。
背景定位:当逻辑推理遇到“视觉干扰”
在 LLM 领域,OpenAI 的 o1 系列证明了通过增加“思考时间”可以解决复杂的数理逻辑。但在视频理解领域,单纯的文字思考有用吗?
作者指出,目前的视频基准测试往往无法区分模型是真的“看懂了”还是靠“猜中了”。
- 痛点一:视频太简单,看一眼就能概括。
- 痛点二:任务太逻辑,视觉输入变成了符号背景。
- PerceptionComp 的核心直觉:真正的视觉智能应该体现为“感知驱动的组合推理”。你需要先识别物体 A,跟踪它到第 3 分钟,观察它与物体 B 的空间关系,再判断 B 的颜色。每一个中间环节出错,整个推理链条就会崩塌。
方法论详解:如何制造“无法作弊”的难题
为了确保题目足够难且无法靠语言先验(Language Prior)解决,PerceptionComp 在两个维度发力:
1. 场景复杂度筛选
利用 SAM2 进行实例分割统计,结合 RAFT 计算光流。只有那些物体极多、运动剧烈、场景切换频繁的视频(如城市漫步、极限运动、游戏直播)才会被入选。
2. 组合推理设计
每个问题被拆解为多个 Subconditions(子条件),并分为两类逻辑:
- 合取逻辑 (Conjunctive):你要找的人必须符合“穿红衣服”且“拿咖啡杯”且“在两辆车之间”。
- 顺序逻辑 (Sequential):先找到 A,看 A 做了什么动作,然后判断动作指向的 B 是什么颜色。
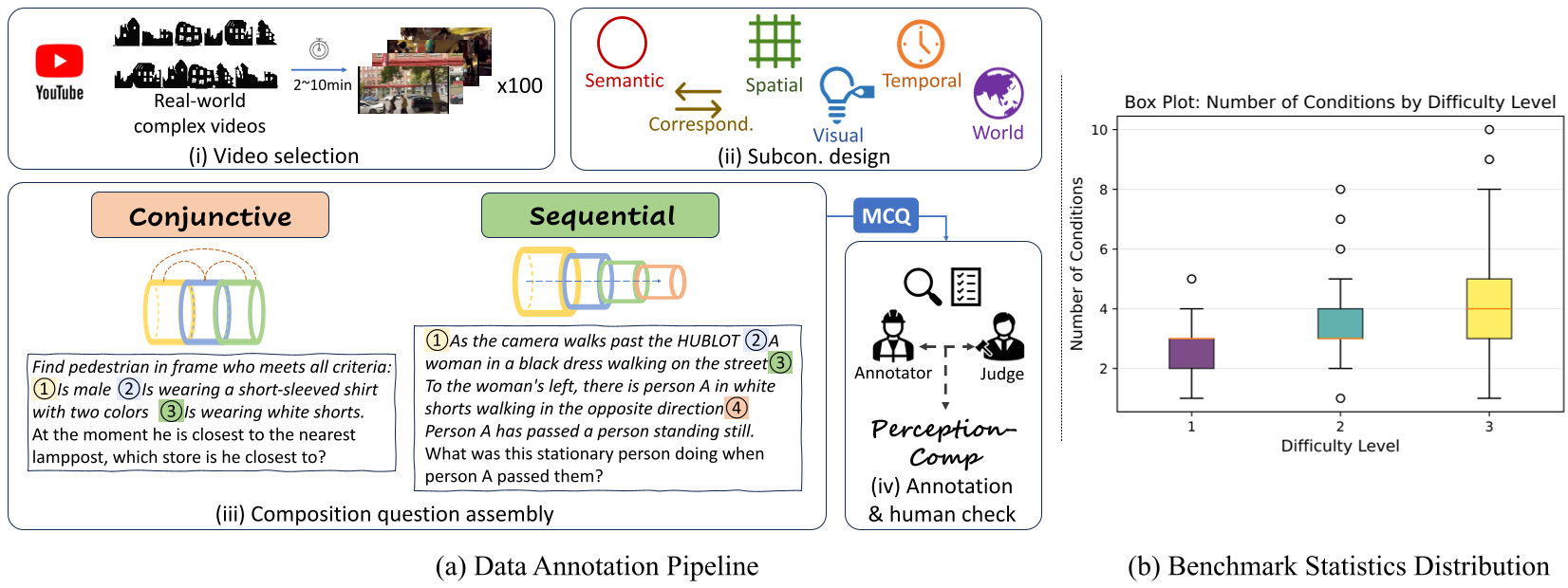 图 1:PerceptionComp 的标注流程,通过组合多种感知技能(语义、空间、时序)构建高难度问题。
图 1:PerceptionComp 的标注流程,通过组合多种感知技能(语义、空间、时序)构建高难度问题。
实验结果:模型集体的“滑铁卢”
研究团队评估了包括 Gemini-3、GPT-5、Qwen3-VL 在内的数十个闭源及开源模型。结果令人震惊:
- 人类表现:专家反复观看可获 100% 准确率。单次观看(不许重看)的人类表现暴跌至 18.97%(接近盲猜)。
- 模型表现:目前的 SOTA 模型最高仅为 45.96%。更有趣的是,轻量级的 Gemini-3-Flash 反而超过了 Pro 版本。作者认为这是因为 Pro 版容易过度关注无关细节,产生“逻辑幻觉”,而 Flash 版在处理长序列时逻辑更纯粹(Streamlining Effect)。
 表 1:各大主流模型在 PerceptionComp 上的表现。可以看出,即便是最强的模型在 Level 3 难度下的表现也极差。
表 1:各大主流模型在 PerceptionComp 上的表现。可以看出,即便是最强的模型在 Level 3 难度下的表现也极差。
关键洞察:
- 帧数决定感知上限:增加输入帧数(从 16 帧到 64 帧)能稳定提升模型准确率,说明模型需要更细碎的视觉证据。
- Thinking 越多效果越好:对于 Gemini-2.5-Flash 等模型,分配更多的计算 Token 能够显著改善推理质量,这证明了 Test-time Scaling 在视觉领域同样有效。
深度分析:为什么 AI 依然很“瞎”?
通过对 Gemini-3 的失败案例分析,作者发现大部分错误发生在推理链的中段。
- 空间理解错误:60% 的中段失败源于对 3D 空间关系的误解。模型能看到物体,但分不清“左边”和“后面”。
- 幻觉级联:由于是多步推理,模型在第一步识别错了对象,后续的思考哪怕逻辑再严密,也只是在错误的道路上渐行渐远。
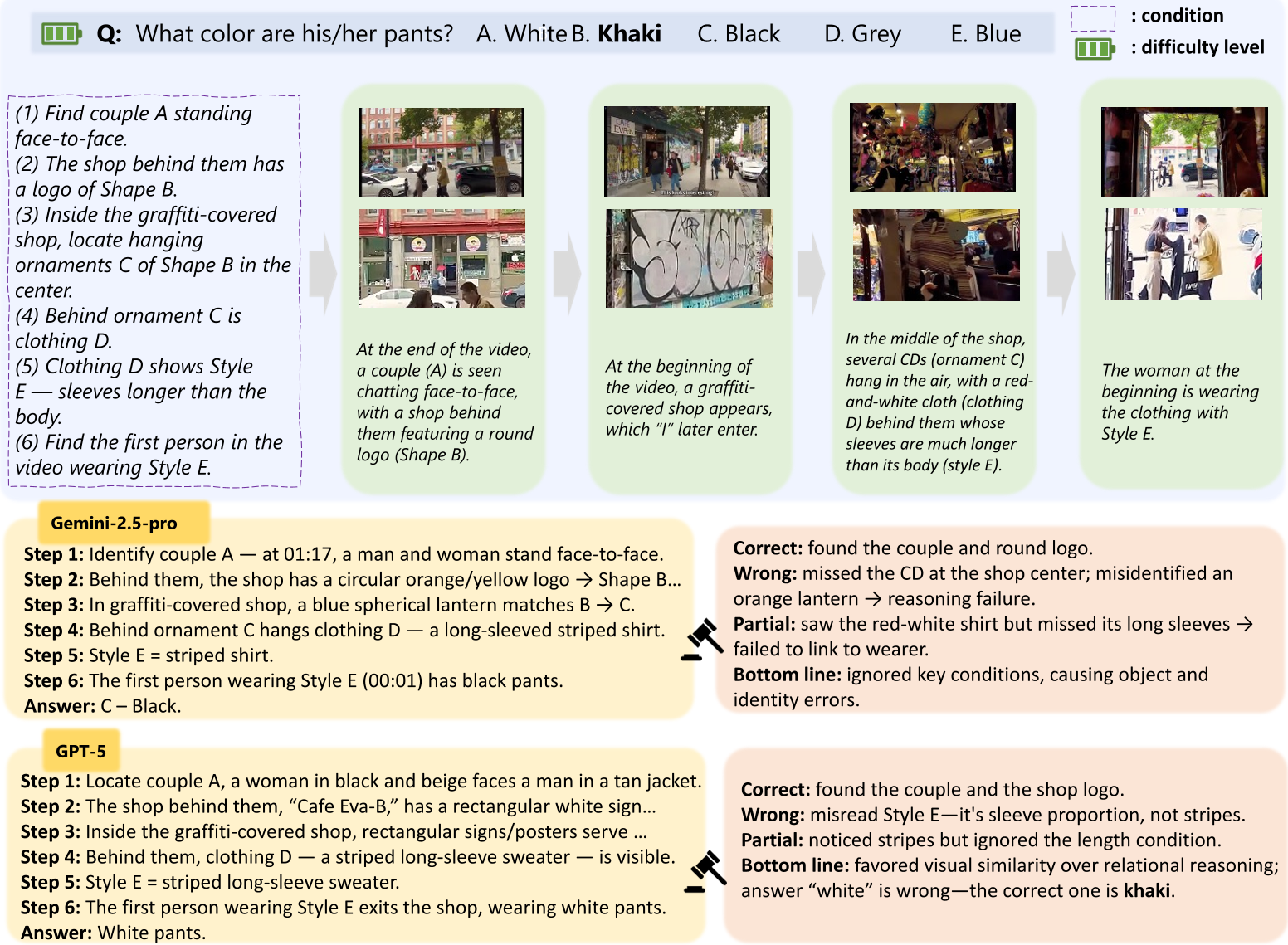 图 2:模型推理失败的典型案例,由于无法维持长期的视觉变量绑定,导致最后一步“指鹿为马”。
图 2:模型推理失败的典型案例,由于无法维持长期的视觉变量绑定,导致最后一步“指鹿为马”。
总结与启示
PerceptionComp 的出现不仅提供了一个更难的榜单,它实际上在拷问现在的模型设计:我们是否过度依赖语言层面的 CoT(思维链),而忽略了视觉层面的“反复寻证”能力?
对于未来的多模态研究,仅仅堆叠参数是不够的。如何让模型具备真正的“视觉搜索”直觉,在长视频中精准地定位并修正每一个感知的 Subcondition,才是通往视频 AGI 的关键钥匙。