This paper introduces Perceptual Flow Network (PFlowNet), a framework that decouples visual perception from reasoning in Large Vision-Language Models (LVLMs) through structured "perceptual flows." By applying variational reinforcement learning and a multi-dimensional reward system, it achieves SOTA results on V* Bench (90.6%) and MME-RealWorld-lite (67.0%), significantly reducing language bias and hallucinations.
TL;DR
PFlowNet addresses a fundamental flaw in current Large Vision-Language Models (LVLMs): the reliance on rigid, high-precision geometric priors that actually hinder reasoning. By introducing "Perceptual Flows"—a structured sequence of visual thoughts—and optimizing them via variational reinforcement learning, PFlowNet achieves SOTA performance on benchmarks like V* and MME-RealWorld, proving that the most helpful visual evidence isn't always the most geometrically precise one.
The "Tunnel Vision" Problem in Precise Grounding
In the quest to reduce hallucinations, many researchers have turned to Grounded RLVR, where models are rewarded for aligning their RoIs (Regions of Interest) with expert annotations from models like GroundingDINO.
However, the authors of PFlowNet uncover a counter-intuitive truth: the highest IoU (Intersection over Union) with expert labels does not lead to the highest reasoning accuracy. As shown in the paper's preliminary study, expert annotations often create a "tunnel vision" effect, cropping out the vital context needed to answer "Why" or "How." PFlowNet shifts the paradigm from imitation of experts to exploration of utility.

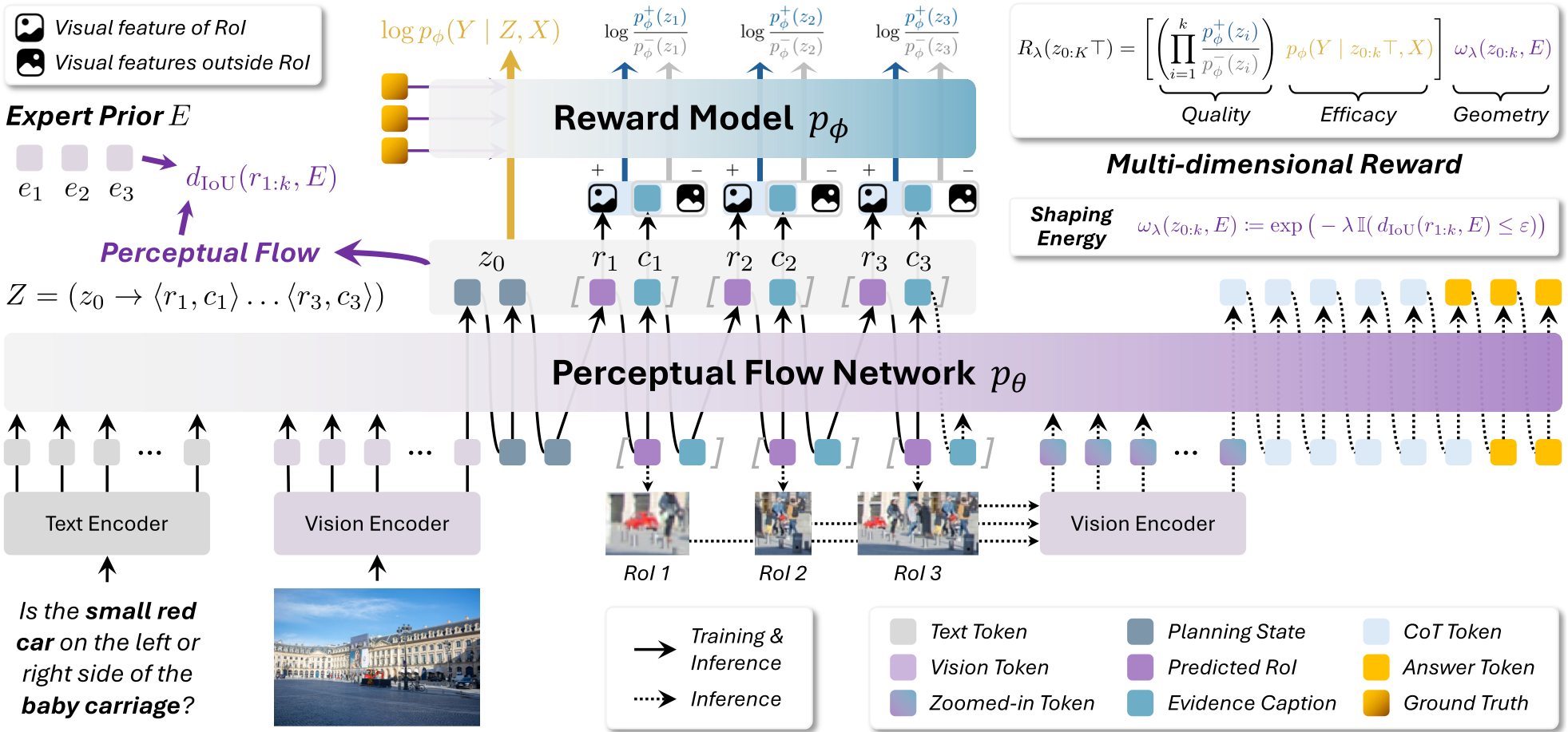
Methodology: The Perceptual Flow
PFlowNet structures the model's "internal monologue" into a Perceptual Flow , which consists of:
- Planning State (): An
<analyze>block where the model decomposes the user's query. - Perceptual States (): A sequence of
<localize>blocks containing both a bounding box and a descriptive caption.
The Variational RFT Strategy
Unlike standard PPO or MLE, PFlowNet uses Sub-Trajectory Balance (SubTB). This hierarchical objective provides dense intermediate supervision. The core innovation lies in the Multi-dimensional Reward:
- Contrastive Quality Reward: Compares the likelihood of a caption given the "zoomed-in" evidence vs. the "outside" context. This forces the model to generate captions that are actually derived from the pixels, not hallucinated from language priors.
- Reasoning Efficacy Reward: Measures how much the sampled flow actually helps in generating the correct answer .
- Vicinal Geometric Shaping: Instead of a "hard" constraint, it applies an energy penalty only when the model wanders too far from a sensible "vicinity" of the object.
Experimental Performance & SOTA Results
PFlowNet, built on the Qwen3-VL 8B backbone, dominates across the board.
| Benchmark | Qwen3-VL 8B (Base) | PFlowNet (Ours) | Gain | | :--- | :---: | :---: | :---: | | V Bench* | 77.5 | 90.6 | +13.1% | | MME-RealWorld-lite | 48.6 | 67.0 | +18.4% | | TreeBench | 44.9 | 55.3 | +10.4% |
Beyond just accuracy, PFlowNet excels in Performance-Efficiency Trade-offs. While "agentic" frameworks (which call external tools) suffer from high latency and long context, PFlowNet’s structured internal flow is lightweight and execution-free.
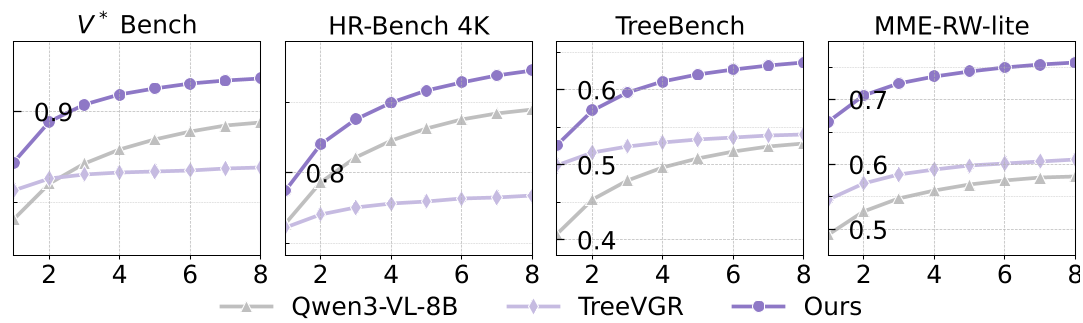
Test-Time Scaling (Pass@k)
One of the most impressive findings is PFlowNet's ability to "think harder." Because it optimizes a variational distribution (rather than a collapsed point-estimate), sampling multiple reasoning paths (Pass@k) leads to consistent performance gains, a property many RLVR models lack.
Deep Insight: Why Does It Work?
The theoretical analysis in the paper (Theorems 3.1 and 3.4) provides a provable guarantee. By calibrating the intensity of the geometric shaping () and the radius of the vicinity (), PFlowNet strictly tightens the distance to an "idealized" posterior.
In practice, this means the model learns to prioritize precise localization early in the sequence and elaborate on context later, effectively "zooming in" to see details and "zooming out" to understand relationships.
Conclusion
PFlowNet proves that the key to solving hallucinations isn't just "more grounding"—it's smarter grounding. By decoupling perception as an optimizable latent flow, we get models that are not only more accurate but are also interpretable, showing us exactly what evidence they used to reach a conclusion.
Future Outlook: The next step is "Adaptive Perception"—allowing the model to decide whether a question is simple enough to answer directly or complex enough to require a deep Perceptual Flow.