本文推出了 PERMA,这是一个旨在评估个性化记忆智能体在长时间维度下“画像一致性(Persona Consistency)”的深度基准测试。该框架摒弃了传统的静态偏好检索,通过事件驱动(Event-Driven)的对话重构、噪声注入及语言风格对齐,挑战模型在复杂交互中推断、整合并维持动态用户画像的能力。
TL;DR
构建具备长程记忆的个性化 AI 智能体不仅是存储对话,更是要构建一个随时间演进的“画像(Persona)”。本文提出的 PERMA 基准测试,通过事件驱动的对话模拟和真实感噪声注入,戳破了现有模型在长文本检索上的虚假繁荣,揭示了跨领域偏好整合才是通往“终身陪伴 AI”的核心瓶颈。
1. 痛点:为什么“大海捞针”救不了个性化?
目前的长文本评估方法大多遵循“检索式”逻辑:在冗长的文本中塞入一句话,看模型能不能找出来。但真实的人机交互绝非如此。
- 偏好是隐性的:用户不会一上来就报出详细清单,而是在反馈和纠正中逐渐表露。
- 偏好是动态的:随着会话推移,用户的需求会发生修正、深化或漂移。
- 环境是嘈杂的:真实的输入充满了歧义(Ambiguous requests)和语言习惯(Idiolects)。
PERMA 认为,一个优秀的智能体不应只是个“搜素引擎”,而应是能维护 Persona State 的观察者。
2. 方法论:如何构建一个“真实的”虚拟世界?
为了模拟真实的画像演进,作者设计了一个精妙的两阶段数据生成管线:
2.1 事件驱动的对话重构 (Event-Driven Reconstruction)
系统首先由一个“策划智能体”根据人口统计学背景生成时间轴,将事件分为 新生偏好 (Emergence)、补充偏好 (Supplement) 和 任务探测 (Task)。这确保了偏好不是一次性灌输,而是通过多个 Session 迭代生成的。
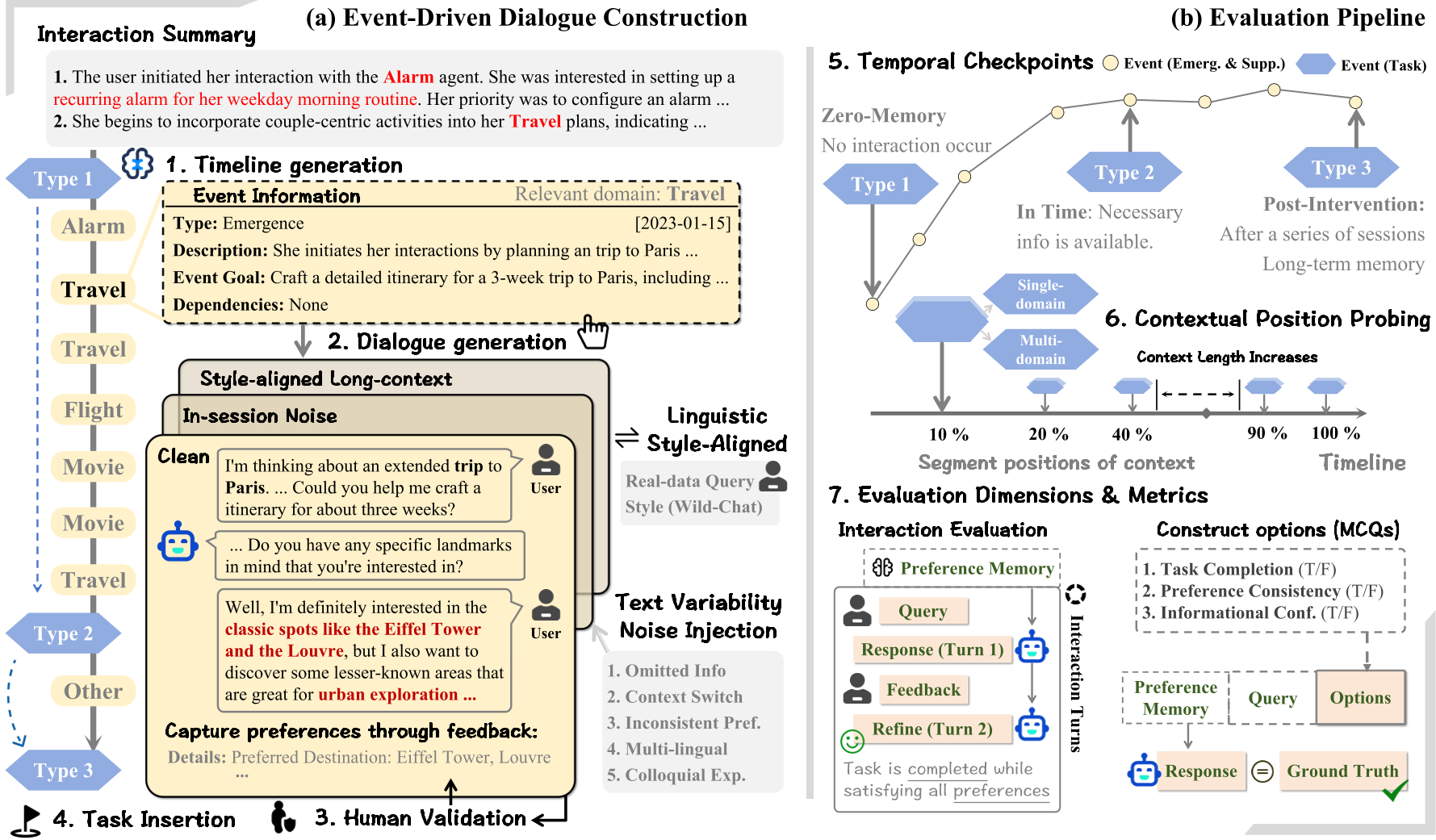 图 1:PERMA 的事件驱动生成流与三级评估 Checkpoints 示意
图 1:PERMA 的事件驱动生成流与三级评估 Checkpoints 示意
2.2 注入“人性”的噪声
为了防止模型通过简单的语义匹配“作弊”,PERMA 引入了两种增强手段:
- 文本变异 (Text Variability):模拟人类常见的 5 种 Prompt 缺陷,如信息缺失、频繁切题和矛盾偏好。
- 风格对齐 (Linguistic Alignment):通过 WildChat 语料库修正 LLM 那股“AI 味”,让用户的提问方式更符合真实的口语习惯。
3. 实验发现:谁才是真正的“记忆大师”?
团队测试了从 Llama 3.3 到 GPT-4o 的多种独立 LLM,以及包括 MemOS, Mem0, EverMemOS 在内的专门记忆系统。
3.1 记忆系统 vs 原生大模型
实验数据表明,专门的记忆系统(如 MemOS)在效率上具有压制性优势。相比于把几十万 tokens 全部塞进上下文,记忆系统通过结构化关联(Graph/Tree),仅用不到 1% 的 token 消耗就达到了接近甚至超过原生长文本模型的准确率。
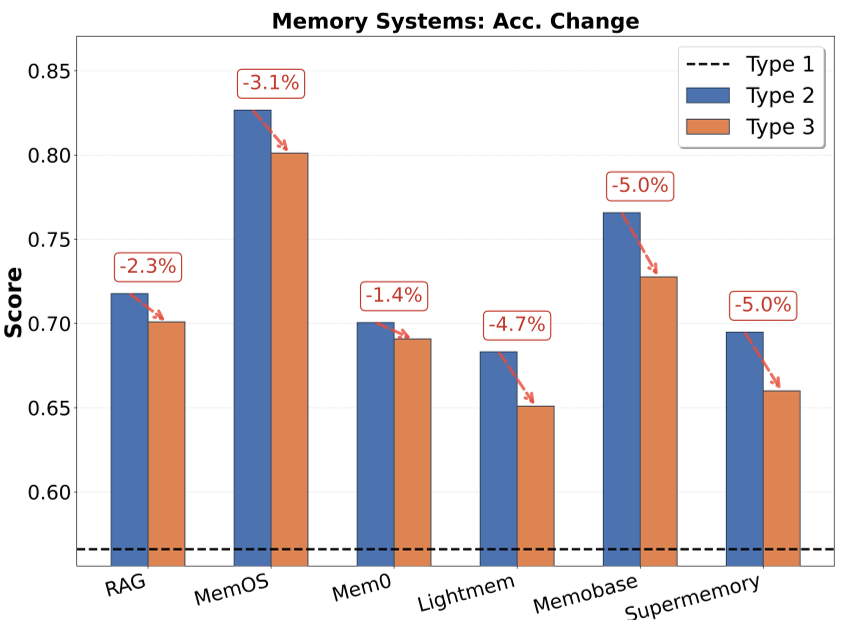 图 2:在不同时间深度(Type 1-3)下,各记忆系统的 MCQ 表现。可以看到随着干扰增加,大多数平衡性系统表现出比 RAG 更强的韧性。
图 2:在不同时间深度(Type 1-3)下,各记忆系统的 MCQ 表现。可以看到随着干扰增加,大多数平衡性系统表现出比 RAG 更强的韧性。
3.2 跨领域任务:目前的“阿喀琉斯之踵”
尽管在单领域任务表现抢眼,但当查询涉及跨领域(如结合购物习惯去订酒店)时,所有系统的表现均大幅下滑。这说明目前的智能体虽然能记住“点”,但还不擅长把散落在不同记忆切片里的“线”串联起来。
4. 深度洞察:未来个性化记忆的三大趋势
通过 PERMA 的测试结果,我们可以预见未来 AI 画像系统的进化方向:
- 从 Episodic 到 Semantic 的抽象:单纯记录对话碎片(Episodic Memory)是不够的,必须具备从中提炼出稳定用户特质(Semantic Preference)的能力。
- 抗噪与自愈能力:能够识别用户暂时的“意图漂移”与长期的“稳定习惯”,不被单次的随机需求所带偏。
- 任务自适应检索:当前的检索策略(如 Top-K)过于僵化,未来的记忆系统应能根据任务复杂度动态决定检索的深度与广度。
总结
PERMA 的出现标志着 AI 个性化评估进入了“实战阶段”。它不仅证明了结构化记忆系统在工程上的必要性,更指明了跨领域推理和复杂环境适应才是下一代个性化智能体的真正战场。