The paper introduces PersistWorld, a Reinforcement Learning (RL) post-training framework designed to stabilize action-conditioned video diffusion world models for robotics. By optimizing the model on its own autoregressive rollouts using a contrastive RL objective, it achieves a new SOTA on the DROID dataset, reducing LPIPS by 14% and significantly improving long-horizon rollout fidelity.
Executive Summary
TL;DR: PersistWorld addresses the fatal flaw of autoregressive world models—exposure bias. While standard models "hallucinate" or dissolve objects after a few seconds of generation, PersistWorld uses a novel Reinforcement Learning post-training scheme to ensure the model remains stable even when feeding its own noisy outputs back as context. By training on self-generated rollouts and using contrastive rewards, it sets a new SOTA for long-term video prediction in robotics.
Academic Positioning: This work moves beyond simple supervised fine-tuning (Teacher Forcing) and positions itself in the emerging intersection of Diffusion Models and Online RL. It is a "structural fix" for the rollout stability problem in the DROID dataset ecosystem.
The "Closed-Loop Gap": Why Predictions Dissolve
The core challenge in robotic world models is Autoregressive Drift. In a standard setup, a model predicts frame $t+1$ based on ground-truth frames $1...t$. However, at test time, it must predict $t+2$ based on its own predicted $t+1$.
If $t+1$ has even a tiny artifact (e.g., a slightly blurred gripper), the model interprets this as "ground truth" for the next step. These errors compound exponentially. As shown in the paper's qualitative analysis, a bowl might "dissolve" into an amorphous texture because the model was never trained to recover from its own small mistakes.
Methodology: Contrastive RL for Diffusion
The authors introduce a framework to train the model on its own "failures."
1. $x_0$-Adapted Contrastive Objective
Unlike previous methods that require backpropagating through the entire denoising chain (which is computationally ruinous), the authors adapt DiffusionNFT. They construct a "Positive Branch" (pushing the model toward high-reward samples) and a "Negative Branch" (pulling it away from low-reward ones).
The beauty of this math is that it works directly on the $x_0$ (clean image) prediction, making it compatible with high-performance backbones like Ctrl-World and Stable Video Diffusion (SVD).
2. Variable-Length Prefix Branching
How do you give a video model "options" to learn from?
- Step S1: The model generates a "Prefix" of length $P$. This prefix is self-generated and thus contains the "natural" errors the model makes.
- Step S2: From that corrupted state, it generates $K=16$ different possible futures.
- Step S3: These futures are ranked using a multi-view reward function.
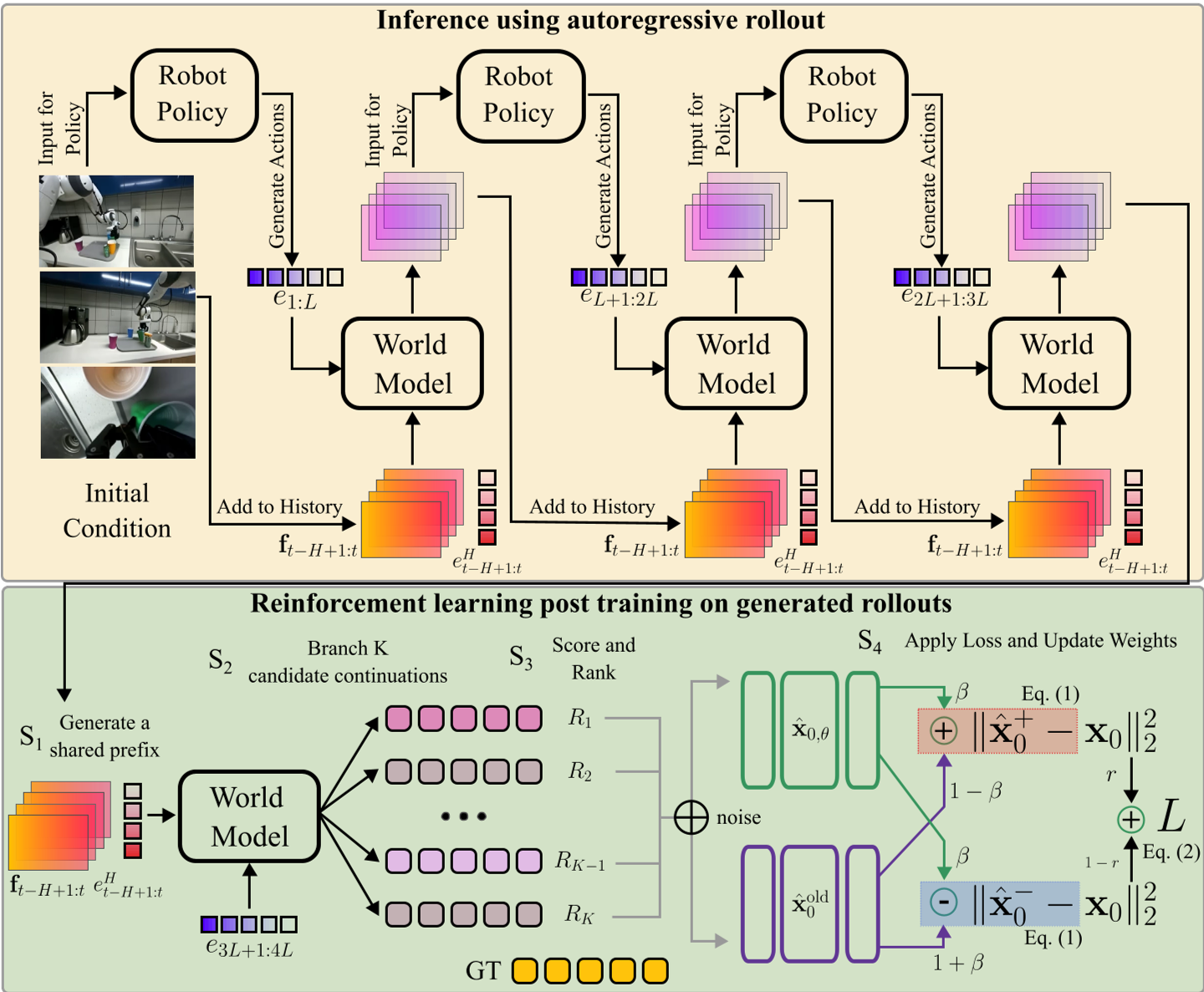 Caption: The training protocol: (S1) Generating a self-conditioned prefix, (S2) Branching multiple candidates, and (S3-S4) Scoring and updating via contrastive loss.
Caption: The training protocol: (S1) Generating a self-conditioned prefix, (S2) Branching multiple candidates, and (S3-S4) Scoring and updating via contrastive loss.
Experiments and Results
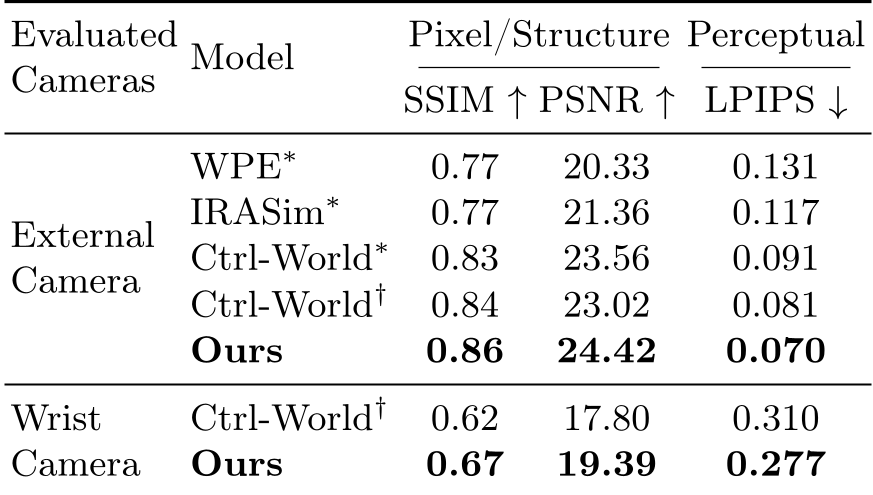
The model was tested on the DROID dataset, focusing on long-horizon rollouts (~11 seconds).
SOTA Performance
PersistWorld outperformed all major baselines (WPE, IRASim, Ctrl-World) consistently.
- LPIPS (Perceptual Loss): Reduced by 14% on external cameras.
- Wrist Camera: Significant improvement in SSIM (+9.1%), which is crucial because the wrist camera captures the fine-grained "hand-object" interactions that define successful manipulation.
Human Preference and Persistence
In a blind study, humans preferred PersistWorld's rollouts 80% of the time. Qualitatively, the difference is stark: while baseline models lose the structural identity of objects (e.g., a cup becoming a blob), PersistWorld maintains structural persistence.
 Caption: Comparison of long-horizon (11s) stability. Note how PersistWorld (right in each pair) maintains the cup's structure while the baseline (left) decoheres.
Caption: Comparison of long-horizon (11s) stability. Note how PersistWorld (right in each pair) maintains the cup's structure while the baseline (left) decoheres.
Deep Insight: Beyond Background Preservation
Many world models cheat by simply "freezing" the background to get high PSNR scores. PersistWorld proves its value through Object-Centric Evaluation. By masking the object and robot, the authors show that their gains are specifically in the dynamic parts of the scene. This suggests the model has actually learned the "physics" of the interaction better, rather than just becoming a better static image replicator.
Conclusion and Future Outlook
PersistWorld demonstrates that the bottleneck for robotic world models isn't just "more data"—it's the training objective. By exposing the model to its own distribution shift via RL, we can create simulators that don't "hallucinate" a failure just because the gripper moved slightly differently than in the training set.
Future Work: The authors point toward incorporating explicit physics-informed constraints (e.g., gravity, collision) into the reward function to further enhance the "common sense" of these neural simulators.