本文提出了 Persistent Visual Memory (PVM),一个旨在解决多模态大模型(LVLMs)在长序列生成中视觉感知能力衰减的轻量化模块。该方法通过在 Transformer 的 FFN 层旁建立并行的视觉检索路径,在 Qwen3-VL-8B 模型上实现了 4.8% 的平均性能提升,且参数量仅增加约 0.32%。
TL;DR
在自回归生成中,随着对话变长,模型往往会“忘记”最初看到的图像。本文提出的 Persistent Visual Memory (PVM) 通过在 Transformer 内部增加一条平行的视觉专用检索通道,成功对抗了长文本带来的“视觉信号稀释”。在 Qwen3-VL 上,它以极小的计算开销(<5% 吞吐下降)显著提升了长文本推理的准确率。
背景定位:视觉信号的“慢性死亡”
当前的自回归多模态模型(如 LLaVA, Qwen-VL)通常将图像 token 放在序列开头。然而,随着模型生成越多的文本,Self-Attention 机制会将注意力权重分配给越来越多的历史文本。作者从理论上证明了 Visual Signal Dilution (视觉信号稀释) 定理:视觉注意力的质量会随着生成长度 的增加呈 的幂律衰减。这就好比你在看图写长篇作文,写到后面,脑子里全是刚才写的字,反而忘了图里画了什么。
核心洞察:从被动保留到主动看图
现有的方法往往通过“视觉注入”(重新插入图像 token)来补救,但这会干扰模型的逻辑推理流。作者的直觉是:既然主干网络容易分心,那就给它配一个专门的“视觉外挂”。
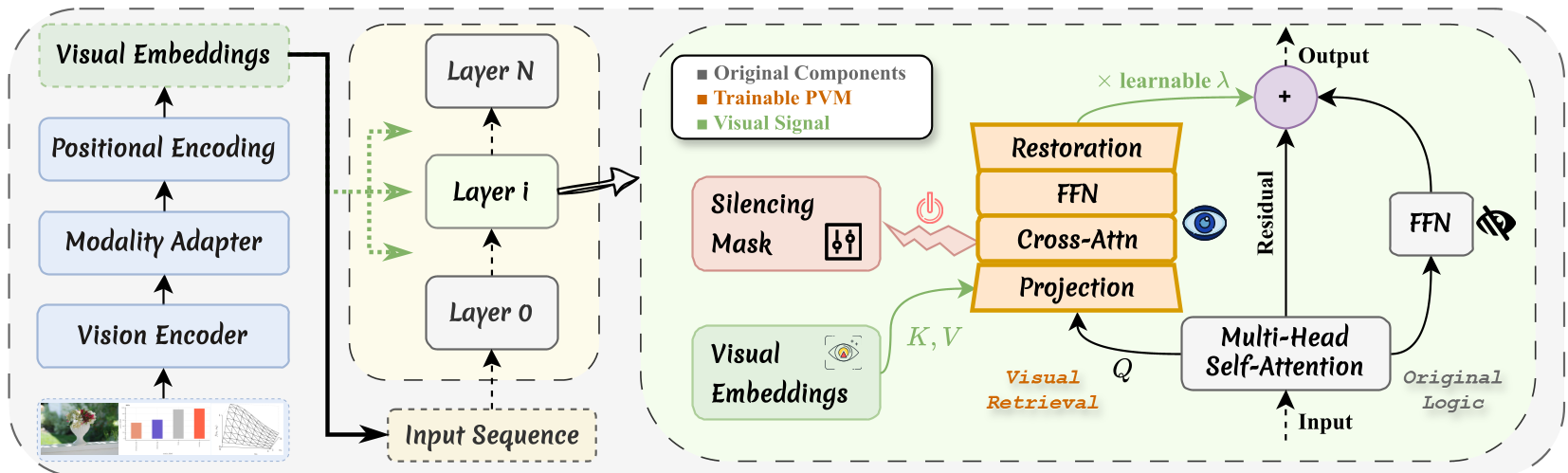
Persistent Visual Memory (PVM) 架构
PVM 不是简单地把图再看一遍,而是作为 FFN 的并行分支(Looking Path)存在。
- 结构分离:当隐藏状态进入 Transformer 层时,一部分走原有的推理路径(FFN),另一部分作为 Query 进入 PVM。
- 独立归一化:在 PVM 内部,Cross-Attention 的 Key 和 Value 仅限于原始视觉 token。由于分母不包含文本 token,视觉信号永远不会被稀释。
- 轻量化适配:通过瓶颈(Bottleneck)结构进行降维检索,仅增加 27.9M 参数(相对于 8B 模型仅 0.3%)。
实验战绩:长序列下的暴力飞跃
实验结果显示,PVM 在 MMMU、MMBench 等 8 个主流榜单上全面超越了基线。
- 长度越长,优势越大:在 MathVerse 任务中,当输出长度较短时,提升只有 6.1%;但当输出变为长推理链时,PVM 的提升达到了惊人的 27.3%。
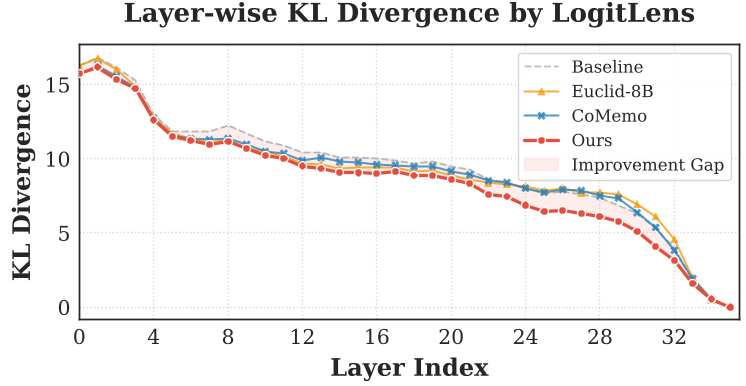
- 推理加速收敛:通过
LogitLens分析发现,由于 PVM 提供了清晰的视觉证据,模型的中层表示更快地锁定了最终答案(KL 散度下降更快)。
深度分析:为什么不直接加大模型?
很多人会问,增加 FFN 的尺寸(参数)效果不是更好吗?作者进行了 Iso-Parameter Control(同参数对照实验): 将 PVM 换成一个参数量完全相同的传统 MLP 分支。结果发现,单纯增加参数量带来的增益远低于 PVM。这证明了 “主动检索原始视觉特征” 这一机制本身,而非参数量的增加,才是解决视觉衰减的真药。
总结与启示
PVM 的成功告诉我们,现有 Transformer 架构在多模态理解上存在天然的结构性缺陷——文本和视觉在同一注意力空间里的“存量竞争”牺牲了视觉的持久性。通过引入并行的专用记忆通道,我们不仅能抑制幻觉,还能显著增强模型在长逻辑链任务(如数学竞赛、长视频分析)中的表现。
未来,这种“分离视觉检索”的思想或许会成为解决大模型“长文本视而不见”问题的标准配置。