本文提出了一种结合视觉、本体感知(Proprioception)与多点触觉(Multi-contact Touch)的多模态 3D 生成重建方法。该方法基于 Flow-matching 扩散模型,通过在 SDF 潜在空间中引入物理约束,实现了在手部严重遮挡下的度量级(Metric-scale)物体形状与位姿精准重建。
TL;DR
在机器人操作中,手部遮挡通常是视觉感知的噩梦。本文提出了一种全新的物理感知生成重建架构,通过将手部本体感知与多点触觉信号注入到流动匹配(Flow-matching)扩散模型中,实现了即使在物体被完全包裹的情况下,也能生成符合物理逻辑、具备真实度量尺度的 3D 模型。
背景定位:从“看起来像”到“物理可行”
传统的单目 3D 重建(如 SAM3D)在面对干净、无遮挡的图像时表现惊艳,但在机器人抓取场景下会迅速“破防”。主要的痛点在于:
- 视觉欠定性:遮挡区域的形状可以有无数种可能,仅靠视觉先验生成的模型往往会穿过机器人的手指。
- 尺度缺失:视觉模型难以精准恢复物体的真实物理尺寸,导致抓取规划失效。
本文的方法论核心在于:如果视觉看不见,那就通过“触碰”和“物理排他性”来推断。
核心方法:基于物理导向的生成式重建
1. 结构化 SDF 表征与 VAE
作者首先通过一个 Structure-VAE 学习 3D 符号距离场(SDF)的潜在空间。与简单的体素(Voxel)不同,SDF 能够提供连续且可微的几何表示,这为后续的物理梯度导向(Guidance)提供了数学基础。
2. 多模态条件融合
模型的输入不再仅仅是 RGB。作者设计了一个多分支跨注意力机制:
- 视觉通路:处理被手部掩码(Mask)裁剪后的物体图像。
- 本体感知通路:将已知位姿的手部几何栅格化并编码,作为“负向空间”约束。
- 触觉通路:将触点位置编码为 3D 占据张量。
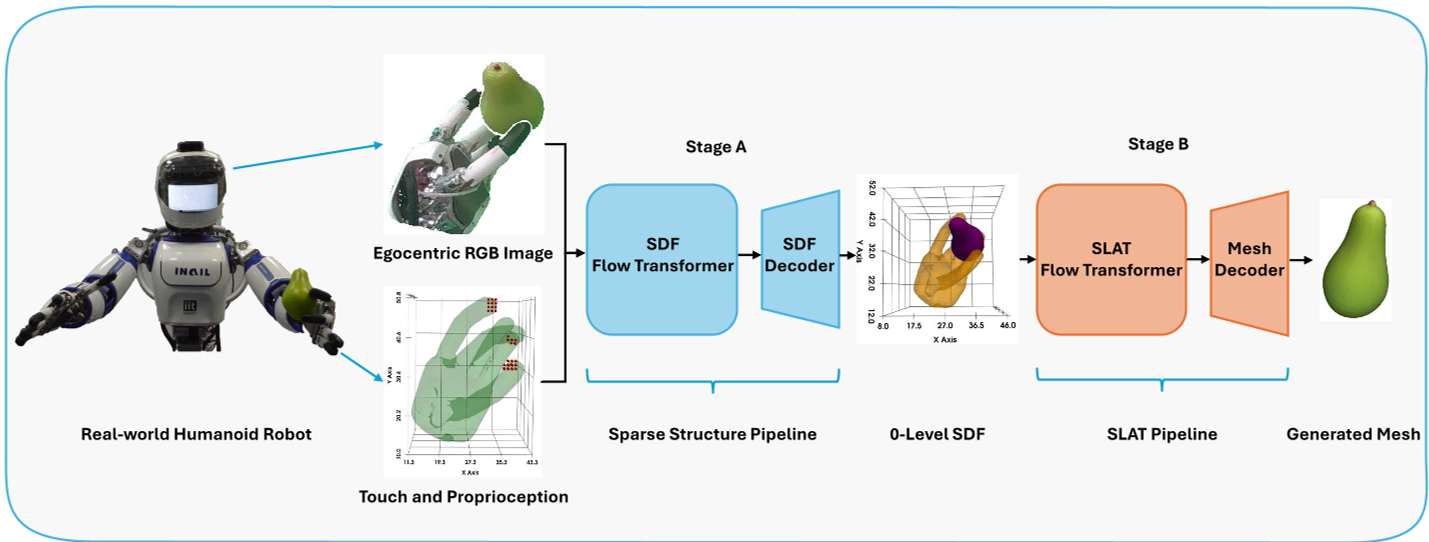 图 1:感知推理流程。系统融合了视觉掩码、手部几何与触觉传感器数据,通过 Flow Transformer 生成符合物理规律的 SDF。
图 1:感知推理流程。系统融合了视觉掩码、手部几何与触觉传感器数据,通过 Flow Transformer 生成符合物理规律的 SDF。
3. 推理阶段的物理导向(Physics Guidance)
这是本文最精妙的地方。在扩散模型的每一步迭代中,算法都会反向传播两个物理损失:
- 非穿透损失():如果生成的物体侵入了手部的空间,产生惩罚。
- 触点一致性损失():如果物体表面没有经过传感器探测到的触点,产生惩罚。 这种“即时修正”确保了最终生成的模型不仅视觉上美观,而且在物理上是可操作的。
实验结果:遮挡下的霸主
在 YCB 数据集的测试中,面对不同程度的遮挡,本文方法展现了极强的韧性。
1. 精度对比
对比 vision-only 的 SOTA 基线 Amodal3R 和强大的 SAM3D,本方法在 Voxel-IoU 和 Chamfer Distance 上均显示出显著优势。尤其是在极端遮挡阶段(Bin 5),基线模型几乎失效,而本方法凭借触觉约束依然保持了较高的重建一致性。
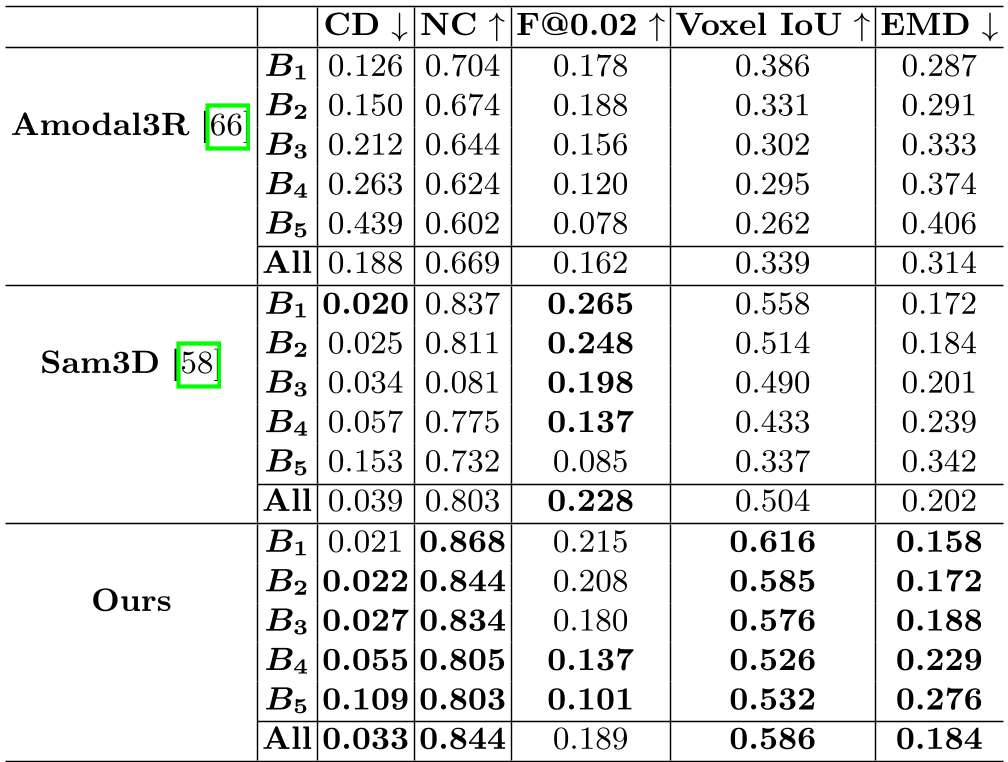 表 1:不同遮挡程度下的重建性能,Ours 在各项指标上均表现稳健。
表 1:不同遮挡程度下的重建性能,Ours 在各项指标上均表现稳健。
2. 可视化分析
从定性结果看,Vision-only 模型经常会在被遮挡的部分生成碎片或错误的尺寸,而本文的方法能精准生成与手部契合的几何结构。
 图 2:仿真展示。注意看第二列(Ours),物体与手指的接合处极其自然,没有严重的重叠穿插。
图 2:仿真展示。注意看第二列(Ours),物体与手指的接合处极其自然,没有严重的重叠穿插。
深度洞察与总结
本文的贡献不仅在于刷榜,而是在于提供了一种“具身智能”的感知范式。 传统的 CV 模型将环境视为“旁观者”,而本工作将其视为“参与者”。通过将末端执行器的运动学模型作为几何先验,物理接触作为显式观测,作者成功地将一个原本欠定的数学问题(单目遮挡重建)转化为一个约束优化问题。
局限性与展望
- 分辨率权衡:目前基于 的网格重建,对于物体细微特征(如剪刀刃)的刻画仍显不足。
- 标定依赖:实机测试表明,手部-相机的标定误差会严重影响触觉信号的对齐。 -未来方向:将触觉进一步扩展为物理属性(如摩擦力、刚度)的推断,从而实现不仅能“看清”几何,还能“感知”动态。
Takeaway: 物理常识(Physics-basis)是 3D 重建从虚拟图像走向现实机器人操作的最后一块拼图。