PhysInOne is a large-scale synthetic dataset designed for visual physics learning and reasoning, featuring 2 million videos across 153,810 dynamic 3D scenes. It covers 71 fundamental physical phenomena across mechanics, optics, fluid dynamics, and magnetism, establishing a new SOTA benchmark for physics-grounded world models.
TL;DR
PhysInOne is an unprecedented synthetic dataset containing 2 million videos designed to teach AI the laws of physics. Covering mechanics, optics, fluids, and magnetism, it provides the scale necessary to move beyond visually "hallucinated" videos toward physically grounded world simulators. By fine-tuning models on this suite, researchers achieved significant gains in motion fidelity, though complex 3D reasoning remains an open challenge.
The Motivation: Why AI Still Fails "Physics 101"
Despite the brilliance of models like Sora or Kling, they frequently fail at basic intuition: a ball might pass through a wall, or a fluid might not exhibit buoyancy. The root cause is a data scarcity: existing physics datasets are either too small or oversimplified (e.g., just cubes and spheres). To build a true "World Simulator," we need a dataset that is to physics what ImageNet was to object recognition—massive, diverse, and precisely annotated.
Methodology: Building a Universe in a Box
The creators of PhysInOne didn't just record videos; they built a multi-engine simulation pipeline to ensure "Physical Ground Truth."
1. The Simulation Stack
Instead of relying on one engine, the authors utilized a specialized trifecta:
- Chaos Physics (UE5): For rigid body dynamics and complex mechanical constraints.
- Taichi (MPM): For high-fidelity deformable objects and granular substances (sand, plasticine).
- Doriflow (SPH): For realistic fluid dynamics (Newtonian and non-Newtonian).
2. Multi-Physics Complexity
Real-world scenes are rarely "single-variable." PhysInOne emulates this by combining 71 basic phenomena into 3,284 unique activities, ranging from simple gravity to triple-physics interactions (e.g., wind hitting a car rolling up a slope with friction).
 Figure 1: The PhysInOne pipeline spans 71 phenomena, involving 2,231 objects across 528 backgrounds.
Figure 1: The PhysInOne pipeline spans 71 phenomena, involving 2,231 objects across 528 backgrounds.
A New Metric: Physical Motion Fidelity (PMF)
Standard metrics like FVD evaluate how "real" a video looks to the eye, but they miss how "right" the motion is. The authors introduce PMF, a Fourier-based metric.
- Insight: By comparing the energy spectra of a generated video vs. a reference, PMF measures motion dynamics while being invariant to simple pixel shifts or color changes.
- Why it matters: It forces the model to be evaluated on its kinematic accuracy rather than its ability to render pretty textures.
Experimental Results: The Gap in 3D Reasoning
The paper benchmarks four critical tasks: Video Generation, Future Prediction, Property Estimation, and Motion Transfer.
Key Finding 1: Fine-tuning Works
Fine-tuning models like SVD or Wan2.2 on PhysInOne drastically increased their PMF scores (e.g., Wan2.2 improved from 2.04 to 2.97). This suggests that models can inherit physical priors if the data is representative enough.
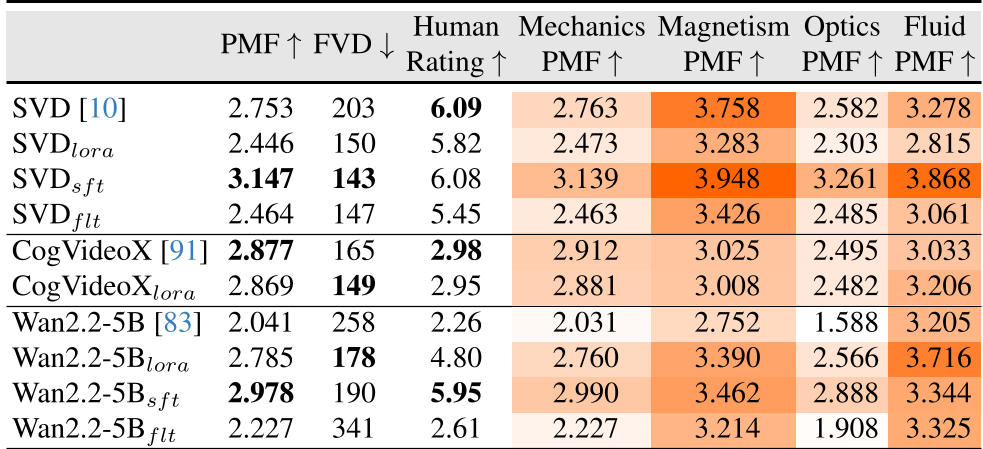 Table 1: Quantitative improvements in PMF and Human Ratings across different video models.
Table 1: Quantitative improvements in PMF and Human Ratings across different video models.
Key Finding 2: The "3D Novel View" Wall
While models could predict future frames for "seen" camera angles, their performance plummeted for novel viewpoints. This reveals that current AI doesn't yet have a 3D-consistent internal model of physics—it is still largely performing 2D pattern matching.
 Figure 2: Qualitative examples of long-term future frame prediction. While trained views are stable, complex dynamics still lead to artifacts.
Figure 2: Qualitative examples of long-term future frame prediction. While trained views are stable, complex dynamics still lead to artifacts.
Critical Analysis & Conclusion
PhysInOne is a massive leap forward. By providing 2 million videos with exact physical parameters, it removes the "data bottleneck" for world models.
Takeaways for Practitioners:
- Synthetic Data is Key: High-quality physics data cannot be easily scraped from the web (which is full of "magic" and editing). Simulation is the only way to get true supervision.
- Multimodal Physics: The inclusion of text descriptions (e.g., "collision displaced the box") allows Large Multimodal Models (LMMs) to link verbal descriptions to physical outcomes.
- The Road Ahead: The failure of current models on "Property Estimation" (guessing the Young's modulus or viscosity from video) shows that AI is still far from being a "virtual scientist."
PhysInOne establishes the benchmark; now it's up to the community to build the architectures that can actually solve it.