本文提出了 Plug-and-Steer 框架,旨在通过解耦“音频分离”与“目标选择”两个过程来优化音视频目标发言人提取(AV-TSE)任务。核心方法是引入了一种极简的线性变换矩阵——潜空间转向矩阵(LSM),使冻结的纯音频分离(AOSS)模型能够根据视觉信号将目标声音路由至指定通道,在 MossFormer2 等模型上实现了比肩 SOTA 的性能,且保持了极高的人声保真度。
TL;DR
在音视频目标发言人提取(AV-TSE)领域,传统的“端到端深度融合”路线正面临挑战。本文提出的 Plug-and-Steer 另辟蹊径:它不再尝试让视觉特征参与复杂的音频分离计算,而是将视觉模态作为“方向盘”,通过控制一个极小的线性矩阵(LSM)来重定向潜空间特征。这种方法不仅保住了预训练音频模型的高保真音质,还显著降低了计算成本。
1. 痛点:为什么 SOTA 音频模型一加视觉就变“笨”了?
音频分离(AOSS)技术目前已非常成熟,但在实际应用中存在排列歧义性(Permutation Ambiguity):模型分出了两个人的声音,却不知道哪一个是用户想听的。
传统的做法是把视频特征塞进音频模型里,用 Cross-Attention 或 Concat 进行深度融合。但作者指出,这存在两个致命伤:
- 保真度天花板:音视频数据集(如 VoxCeleb2)通常噪声很大,直接在上面全参数微调,会破坏模型在纯净音频(如 LibriSpeech)上学到的精致先验。
- 冗余性:AOSS 引擎明明已经能分得很好了,为什么要为了“选择”而重学一遍“分离”?
2. 核心直觉:潜空间里的“换位思考”
作者发现,现代的分离模型(如 TF-GridNet, MossFormer2)在内部深层结构中,已经清晰地将不同说话人的特征按照通道分离了。之所以选不对,只是因为通道顺序是随机的。
既然如此,我们不需要重构音频,只需要在潜空间里做一个“二选一”的逻辑路由。这就是 Latent Steering Matrix (LSM) 的由来:一个 的恒等矩阵(或交换矩阵),通过视觉信号来决定是否进行通道交换。
3. 架构解析:如何实现“即插即用的转向”?
Plug-and-Steer 的流程非常优雅:
- 冻结主干:保留预训练 AOSS 模型的所有权重。
- 插入 LSM:在最后一个分离块(Separator Block)处插入转向矩阵 。
- 视觉转向模块:通过目标发言人的唇动特征(Lip motion),预测一个门控值 。如果发现当前通道不是当前目标,则激活 进行潜空间路由切换。
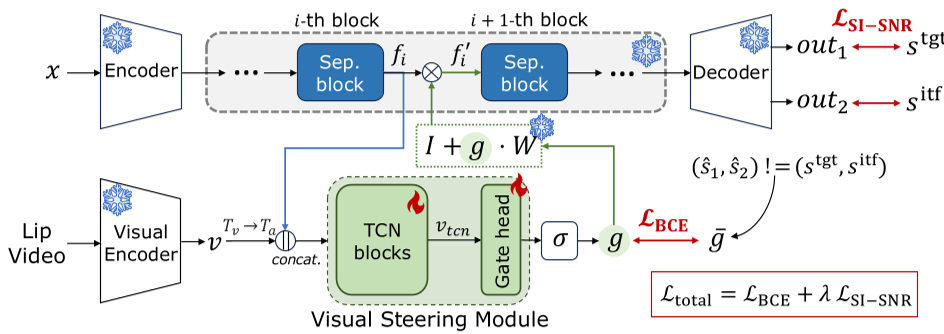 图 1:Plug-and-Steer 整体流程,视觉模块作为 steering wheel 指引音频特征流向
图 1:Plug-and-Steer 整体流程,视觉模块作为 steering wheel 指引音频特征流向
 图 2:针对第 i 个分离块训练 LSM 以实现通道交换的逻辑示意
图 2:针对第 i 个分离块训练 LSM 以实现通道交换的逻辑示意
4. 实验结果:保真度与效率的双赢
4.1 层级实验:在哪里“转向”效果最好?
实验显示(见下图),模型越深,发言人特征的解耦程度越高。在最后一个 Block 进行转向,几乎可以实现 100% 的性能保持率。
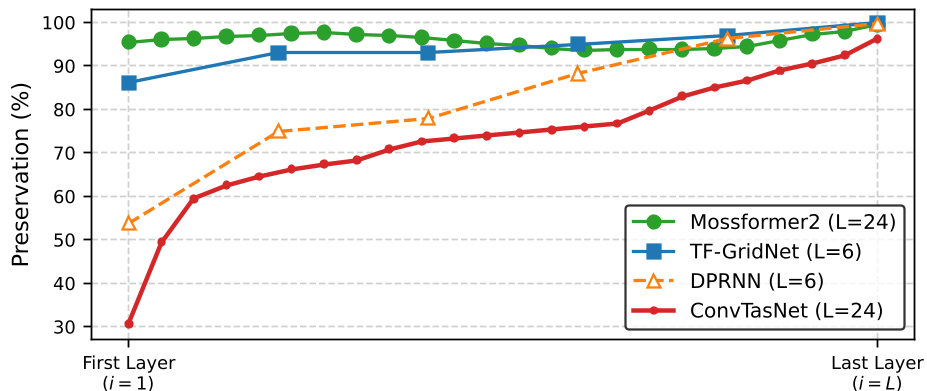 图 3:不同 AOSS 主干在不同层实现 LSM 的性能保持率对比
图 3:不同 AOSS 主干在不同层实现 LSM 的性能保持率对比
4.2 SOTA 对标:不只是快,而且更好听
在 LRS2-2mix 上的测试表明,尽管传统的残差微调(Residual Fine-tuning)在 SI-SDRi(信号干扰比)上有时略高,但其 DNSMOS(感知质量)却大幅下降。
- MossFormer2 + LSM:保持了 2.88 的 DNSMOS,而全量微调降到了 2.53。
- 效率提升:由于不需要重新解码和复杂的跨模态同步,实时因子(RTF)大幅优化。
5. 深度洞察与总结
Plug-and-Steer 成功的背后是一个重要的设计哲学:模块化解耦。
- 稳定性:它将 TSE 问题退化为一个简单的“二分类路由”问题,梯度流更直接,训练极其稳定(仅需 100k steps 即可收敛)。
- 可扩展性:未来只要出现更强大的音频分离引擎(例如基于 Mamba 或扩散模型的),都可以像换零件一样接入该框架,无需复杂的重新调优。
局限性:目前该研究主要针对 2-speaker 混合场景。对于 3 人及以上的复杂场景,LSM 需要从简单的二进制门控扩展为更复杂的置换矩阵预测。
总结:这篇论文为工业界提供了一个非常务实的路径——不要尝试去重训那个庞大的音视频模型,给它套个“转向灯”,它能跑得更稳、更清晰。