PokeGym is a visually-driven, long-horizon benchmark for Vision-Language Models (VLMs) instantiated in a complex 3D open-world RPG, Pokémon Legends: Z-A. It features 30 automated tasks spanning navigation and interaction, requiring agents to operate solely on raw RGB pixels while achieving success verified by independent memory scanning.
TL;DR
PokeGym is a new 3D benchmark utilizing Pokémon Legends: Z-A to push Vision-Language Models (VLMs) to their limits. By enforcing pure-pixel inputs and providing automated, memory-based scoring, it reveals a startling truth: the smartest AI models are often physically "clumsy," getting stuck behind simple fences because they lack 3D spatial intuition, even when they know they are trapped.
The "Privileged Information" Problem
Most current "embodied" AI benchmarks cheat. They give the agent hidden data—like exact coordinates or object IDs—which bypasses the most difficult part of being an agent: vision. When you remove the training wheels and force an agent to look at raw RGB frames, the performance of even the most advanced models (like GPT-5 series or Gemini-3-Pro) takes a massive hit.
The authors of PokeGym argue that true embodied competence requires four things: long-horizon planning, realistic 3D visuals, pixel-only observation, and scalable automated evaluation. Existing benchmarks like ALFRED or MineDojo usually trade one for another. PokeGym solves this by using a modern game engine while keeping the internal game state hidden from the AI.
Methodology: Probing the VLM Brain
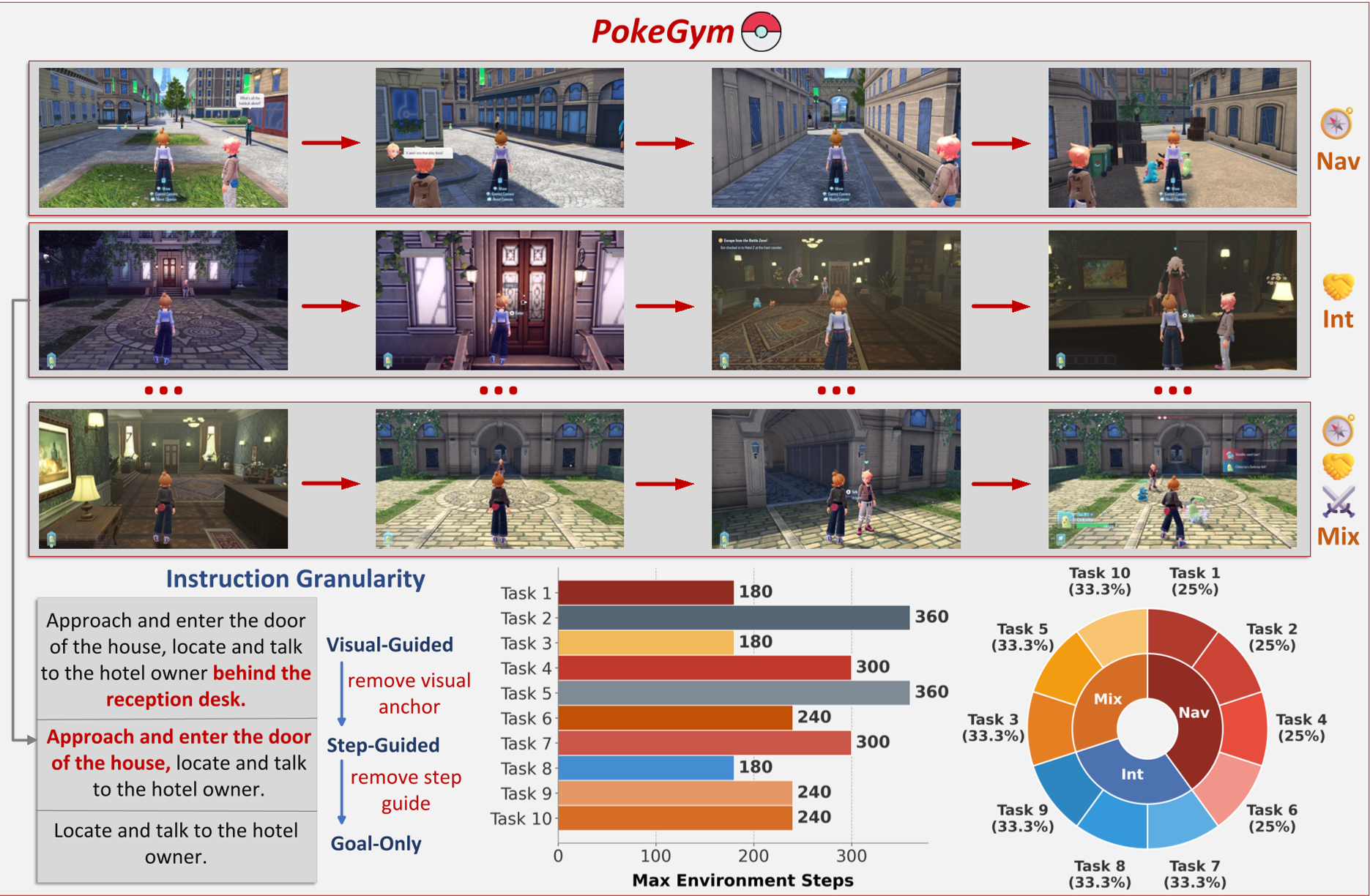
PokeGym isn't just a leaderboard; it’s a diagnostic tool. It uses three levels of "Instruction Granularity" to see where the AI's cognitive chain breaks:
- Visual-Guided: Includes visual anchors (e.g., "look for the red house"). Tests Visual Grounding.
- Step-Guided: Provides sub-goals but no visual cues. Tests Semantic Reasoning.
- Goal-Only: Only gives the final objective. Tests Autonomous Exploration.
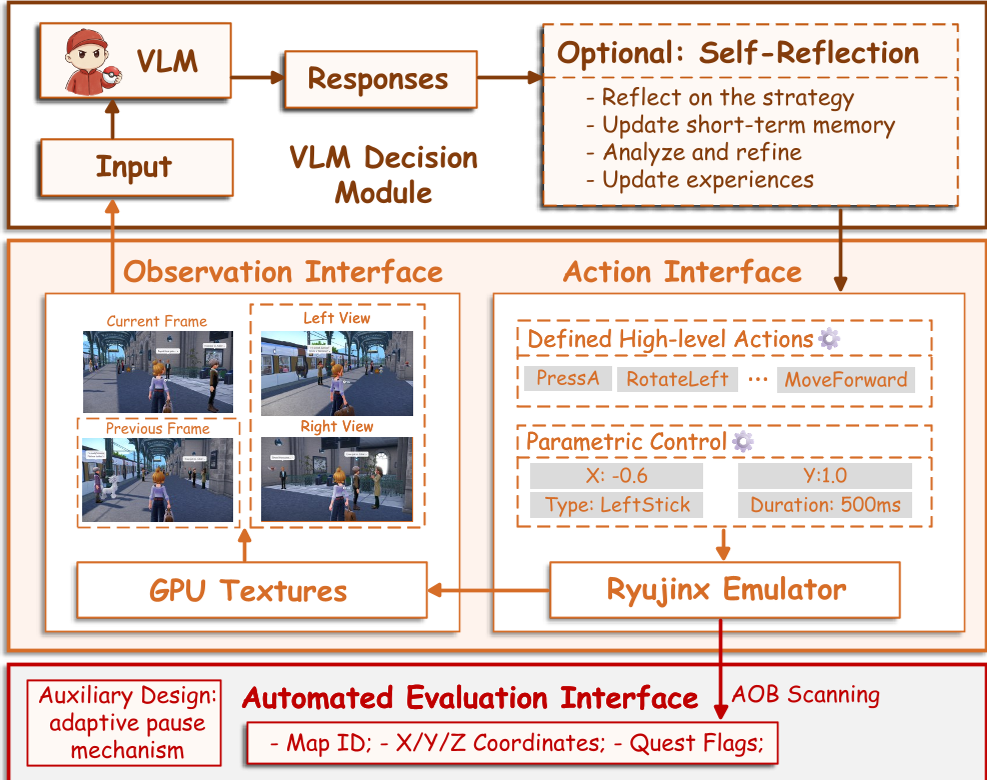
The architecture uses the Ryujinx emulator, extracting frames directly from GPU textures to eliminate lag, while an independent process scans memory bytes (AOB) to check if the agent reached the goal.
Key Insight: The Metadata of Failure
The most profound discovery in the paper is the Metacognitive Divergence in failures. The researchers categorized why models fail when they get stuck (deadlocks):
- Unaware Deadlocks: Weaker models (like earlier Qwen versions) are stuck against a wall but hallucinate that they are making progress. They lack 3D state estimation.
- Aware Deadlocks: Advanced models (like GPT-5.2) know they are stuck. Their internal reasoning says: "I am hitting a wall." However, they lack the spatial intuition to execute a "step back and rotate" maneuver, instead flailing in a high-entropy loop.
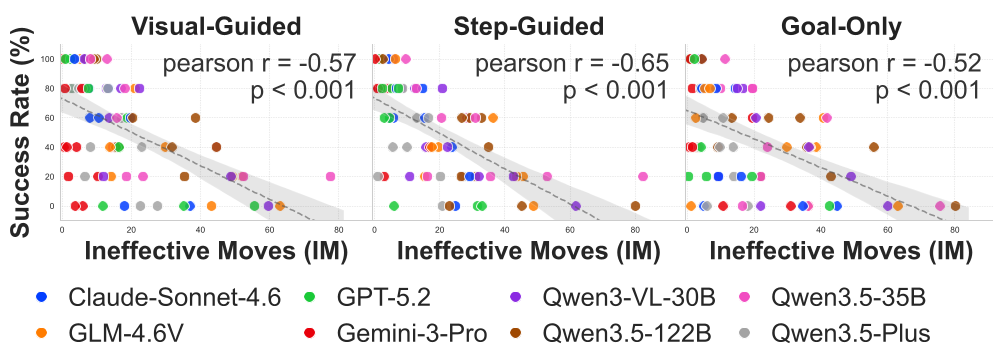
The chart above shows a brutal negative correlation: as "Ineffective Moves" (collisions) increase, the success rate plummets. This proves that low-level physical friction—the "embodied tax"—is a bigger bottleneck than high-level logic.
Experimental Results: The Leaderboard
The results show that proprietary models still dominate, with Gemini-3-Pro and GPT-5.2 sharing the top spot. However, "Mixed" tasks (combining navigation and combat) remain nearly impossible for most, with success rates often dropping below 10% for Goal-Only instructions.
Deep Insight & Conclusion
PokeGym reveals that the current path to "Generalist Agents" cannot rely solely on scaling LLM reasoning. We are seeing a "Physical-Cognitive Gap." A model can be a PhD-level scientist in text, but an infant in a 3D environment.
The Takeaway: To solve PokeGym, we don't need smarter planners; we need models with Spatial Intuition. We need architectures that understand depth, occlusion, and collision as primary concepts, not just as pixels to be captioned. The future of robotics and embodied AI likely lies in bridging this gap between high-level language and low-level geometry.