本文推出了 PokeGym,这是一个基于《宝可梦传说:Z-A》3D 开放世界游戏构建的视觉驱动长程任务基准测试。该基准包含 30 个复杂任务,强制智能体仅依靠原始 RGB 像素进行决策,并利用 AOB 内存扫描技术实现了 SOTA 级别的自动化合规评估。
TL;DR
在静态图像理解上已经“封神”的视觉语言模型(VLMs),一旦被丢进复杂的 3D 开放世界游戏会发生什么?来自最新研究的 PokeGym 基准测试给出了扎心的答案:即使是最强的 GPT-5.2 或 Gemini-3-Pro,在《宝可梦传说:Z-A》的世界里也经常陷入“死锁”无法自拔。PokeGym 证明了:当前 AI 指挥官(高层规划)很强,但基层士兵(物理控制)往往是折损在“看不见的空气墙”面前。
背景定位:从“纸上谈兵”到“荒野求生”
目前的 VLM 评估大多停留在 VQA(视觉问答)或简单的 2D 网格环境中。这就像是在考驾照时只考理论题,而不上路。PokeGym 的意义在于它提供了一个纯像素输入、长路径(30-220步)、高度复杂拓扑的 3D RPG 测试场,且通过内存扫描技术解决了长期困扰学术界的人工评价不可扩展的难题。
痛点深挖:不仅仅是感知,更是交互
作者指出,现有的具身智能(Embodied AI)测试存在“作弊”嫌疑。许多框架直接把智能体的坐标或目标物体的 ID 喂给模型,这相当于给 AI 开了“全图挂”。而在 PokeGym 中,AI 只能看到 RGB 图像。它必须自己判断:
- 眼前的草丛是真的路还是碰撞体积?
- NPC 的背后是不是死胡同?
- 摄像头转动的视角如何影响空间记忆?
核心方法论:解耦认知的“手术刀”
PokeGym 设计了三种不同难度的指令输入(如图 2 所示),试图拆解 AI 的各项能力:
- Visual-Guided (视觉引导):给 AI 详细的视觉地标提示。
- Step-Guided (步骤引导):只给操作指令,不给视觉线索(考察语义常识)。
- Goal-Only (仅目标):只告诉 AI“去跟旅店老板说话”(考察自主探索与规划)。
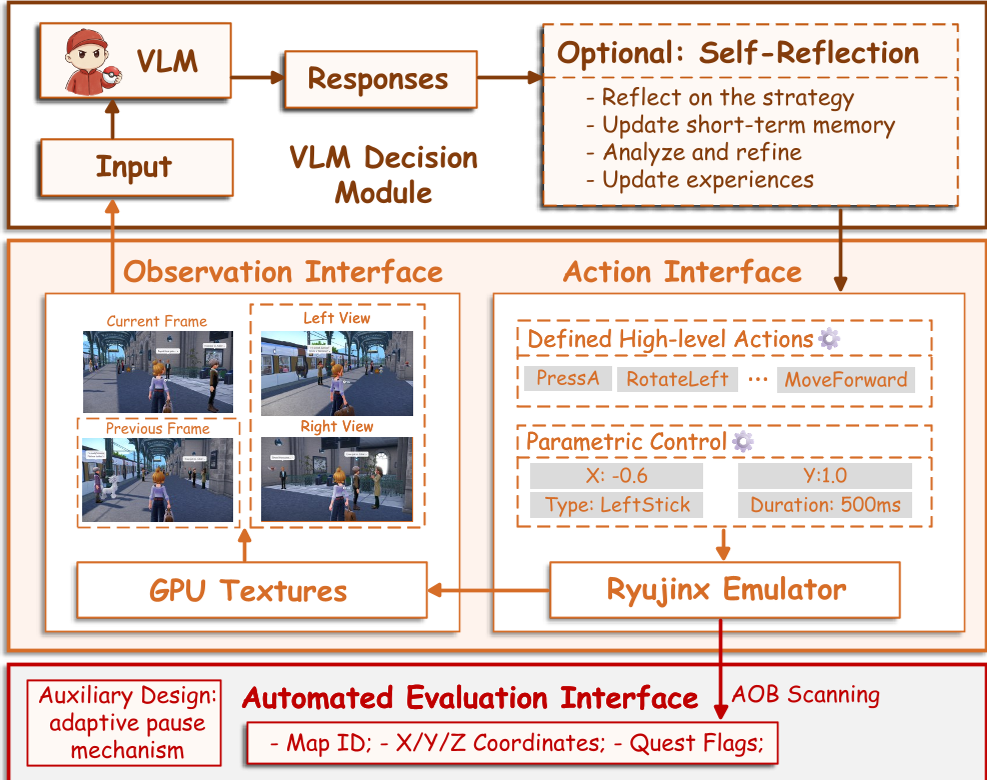 PokeGym 系统架构:由 Ryujinx 模拟器驱动,强制纯像素输入,后端通过内存扫描进行评测。
PokeGym 系统架构:由 Ryujinx 模拟器驱动,强制纯像素输入,后端通过内存扫描进行评测。
实验发现:有趣的“元认知分歧”
在对 GPT-5.2、Qwen3.5 等模型进行大规模压测后,研究者发现了一个极具启发性的现象——死锁诊断:
- 弱模型的“ Hallucinated Progress ”:像 Qwen3.5 这种模型,经常被卡在柱子后面。有趣的是,它的推理日志显示它觉得自己正在顺利前进。这被称为 Unaware Deadlock。
- 强模型的“无力回天”:GPT-5.2 能够敏锐地意识到“我被卡住了,前面的柱子挡住了路”,但它给出的下一步行动方案往往还是无效的碰撞行为。这被称为 Aware Deadlock。
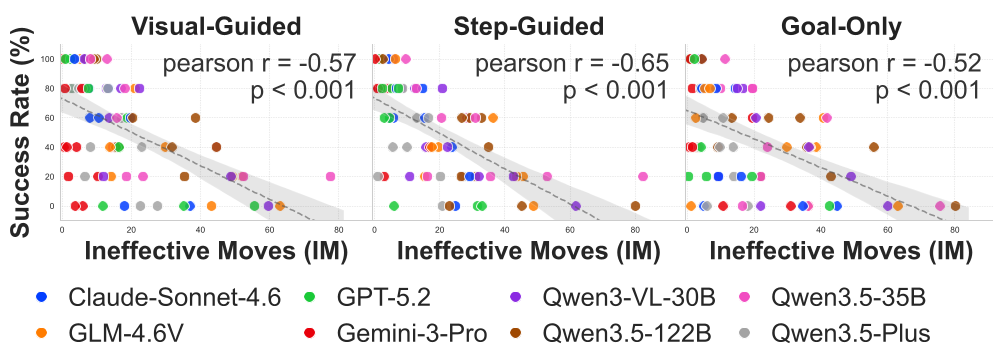 实验数据显示:失败的任务中,无效移动(Ineffective Moves)比例极高。成功率与死锁次数呈强负相关。
实验数据显示:失败的任务中,无效移动(Ineffective Moves)比例极高。成功率与死锁次数呈强负相关。
深度洞察:为什么 AI 会“撞墙”?
通过对失败案例的消融分析,研究者总结了 3 类物理陷阱:
- 视觉渗透障碍 (Visually Permeable Barriers):如栅栏或柱子。AI 能看到栅栏后面的草地,于是先验知识告诉它“那里可以走”,却忽略了物理上的碰撞约束。
- 不规则微几何 (Irregular Micro-geometries):AI 能避开大墙,却容易被路边的盆栽或 NPC 的侧边勾住。
- 误导性交互元素:AI 可能会对着一个装饰性的门重复点击“交互”,而陷入逻辑死循环。
总结与未来启示
PokeGym 的出现为 VLM 迈向真正的具身智能敲响了警钟。目前的模型更多是“视觉翻译官”,而非“空间工程师”。
- 价值:提供了一个完全自动化的 3D 任务评测流水线,不泄露任何特权状态。
- 启示:仅仅给模型喂更多的图像是不够的,未来的架构需要引入显式的 3D 几何直觉,或者通过像“强制后退+旋转”这种简单的启发式策略来增强模型的容错能力。
正如作者所言,解决“死锁恢复”可能比优化“高层规划”更是当前具身智能的燃眉之急。