The paper introduces PowerFlow, a principled unsupervised fine-tuning framework that reformulates LLM capability elicitation as a distribution matching problem targeting the -power (escort) distribution. It achieves SOTA reasoning performance (matching supervised GRPO) and shifts the Pareto frontier in creative writing tasks by modulating a single controllable parameter .
TL;DR
PowerFlow moves beyond the "black box" of heuristic rewards in unsupervised LLM training. By treating fine-tuning as a distribution matching task and introducing a Length-Aware Trajectory-Balance objective, the authors provide a "tuning knob" () to either sharpen the model for rigorous logical reasoning or flatten it for creative expression. It achieves the performance of supervised methods (like GRPO) without needing a single label or external verifier.
Problem & Motivation: The Trap of Heuristic Rewards
Reinforcement Learning from Internal Feedback (RLIF) is the frontier of making LLMs "self-evolve." However, current methods are brittle. If you reward "confidence," the model becomes overconfident; if you reward "majority voting," the model might find "shortcuts" to consistent but wrong answers.
The fundamental issue is Structural Length Bias. In autoregressive models, the probability of a sequence decays exponentially with length. Standard RL objectives accidentally reward shorter sequences (length collapse) during sharpening or repetitive long ones during flattening. The authors argue we need a method that respects the semantic density of the model rather than just its sequence-level probability.
Methodology: GFlowNets Meets the Alpha-Power Distribution
The researchers from Tsinghua University propose PowerFlow, which targets the -power distribution:
The "Dual Nature" Knob:
- Reasoning Elicitation (): Sharpening the distribution helps the model "concentrate" on high-probability reasoning paths that are latent in the base model.
- Creativity Release (): Flattening the distribution (mostly for aligned/RLHF models) recovers the "long-tail" creative outputs that are usually suppressed by the typicality bias of standard alignment.
Technical Innovation: LA-TB Objective
To solve the length bias, they derive the Length-Aware Trajectory-Balance (LA-TB) objective. Instead of a scalar partition function , they use a length-normalized term that ensures the gradient is scale-invariant. This keeps the response length stable even during aggressive sharpening.
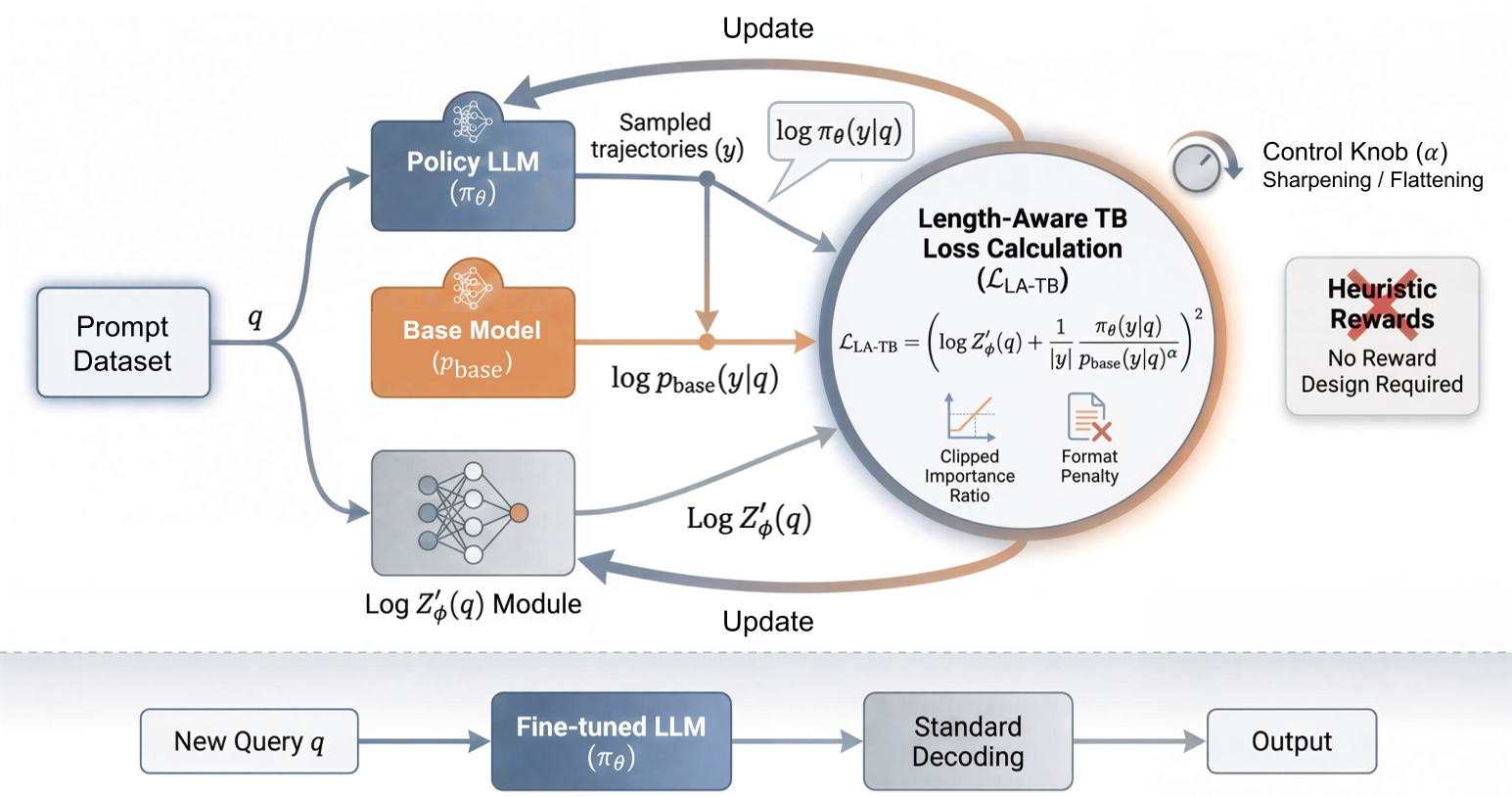 Figure: The PowerFlow framework showing the training pipeline (matching the energy surface) and inference.
Figure: The PowerFlow framework showing the training pipeline (matching the energy surface) and inference.
Experiments & Results: Rivaling Supervised GRPO
The results are striking across mathematical reasoning benchmarks (MATH500, AIME, GPQA).
- SOTA Performance: On Qwen2.5-Math-1.5B, PowerFlow reached 34.3% average accuracy, actually beating the supervised GRPO (32.75%) which requires verifiable rewards.
- Stability: Unlike standard RL-traj or TB-traj objectives which see immediate length collapse, PowerFlow maintains stable response lengths throughout training.
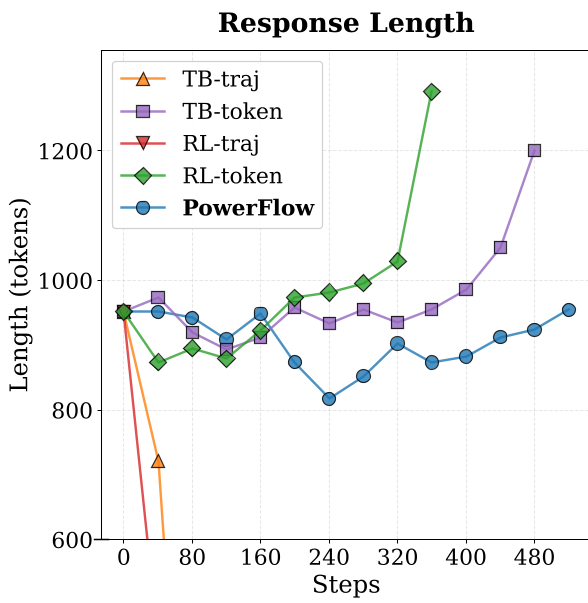 Figure: Comparison of optimization stability. PowerFlow (yellow) maintains accuracy and length where others collapse.
Figure: Comparison of optimization stability. PowerFlow (yellow) maintains accuracy and length where others collapse.
Unlocking Creativity
For creative writing, PowerFlow () achieved a Pareto-dominant shift. Most methods (like increasing temperature) trade off quality for diversity. PowerFlow is the only one that increased both semantic diversity and the quality score judged by Qwen3-Max.
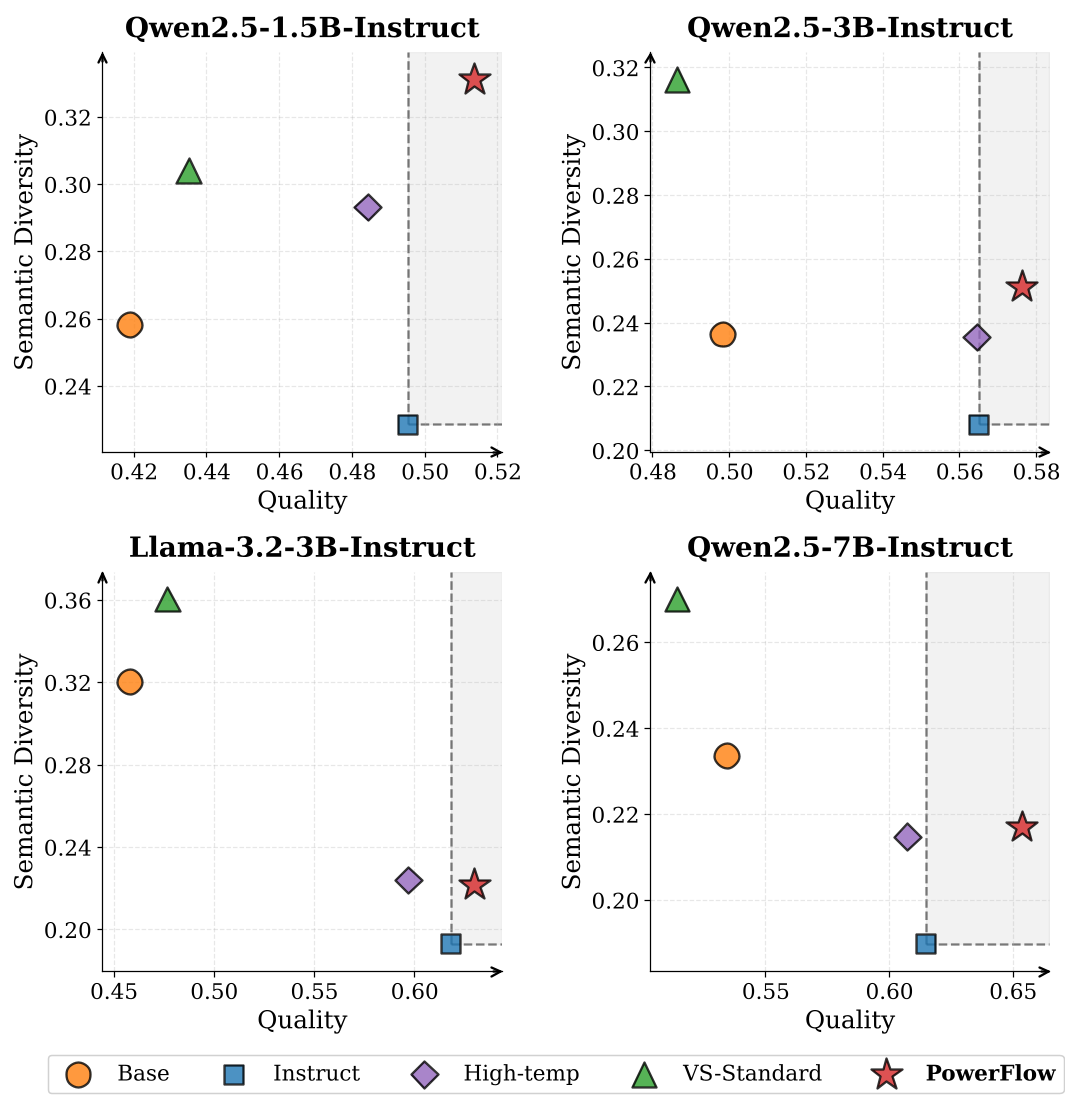 Figure: Quality vs. Semantic Diversity. PowerFlow shifts the frontier outward, providing the "best of both worlds."
Figure: Quality vs. Semantic Diversity. PowerFlow shifts the frontier outward, providing the "best of both worlds."
Critical Analysis & Conclusion
Takeaway: PowerFlow proves that the "intelligence" is already there in the pre-trained weights. Post-training is less about "teaching new tricks" and more about reshaping the probability landscape to make those tricks easier to sample.
Limitations: The parameter still requires some manual tuning (though seems a robust default for reasoning). The "Length-Aware" reparameterization is a pragmatic geometric mean approach; a more mathematically "complete" length-invariance theory for GFlowNets remains an open research question.
Future Outlook: This work sets a new standard for Unsupervised Alignment. We may soon see AI agents that can dynamically adjust their own "temperature" based on whether they are solving a calculus problem or writing a surrealist poem.