本文提出了 PowerFlow 框架,一种将大型语言模型(LLM)的无监督微调重新表述为“分布匹配”问题的理论方案。通过 GFlowNet 训练模型拟合基座模型的 $\alpha$-幂分布,PowerFlow 实现了推理能力增强($\alpha > 1$)与创造力释放($\alpha < 1$)的双向调控,在数学推理任务上超越了有监督的 GRPO 算法。
TL;DR
来自清华大学的研究团队提出了 PowerFlow,这是一种跳出“奖励工程”陷阱的无监督微调框架。它通过 GFlowNet 匹配基座模型的 $\alpha$-幂分布($\alpha$-power distribution),通过调节一个简单的控制杆 $\alpha$,既能让模型变身“理性机器”横扫数学竞赛,也能让其化身“创意大师”写出灵动诗篇。
背景定位:该工作是无监督强化学习(RLIF)领域的理论突破。它不仅在性能上硬刚有监督的 GRPO 算法,更从统计物理的视角揭示了 LLM 自我进化的本质:分布锐化(Sharpening)。
痛点深挖:消失的奖励与致命的长度偏见
目前的无监督学习方法(如 RLIF)大多在玩“猜谜游戏”:通过自洽性或熵值来手动设计奖励函数。然而,由于这些奖励往往是启发式的,模型在微调后期经常“走歪”:
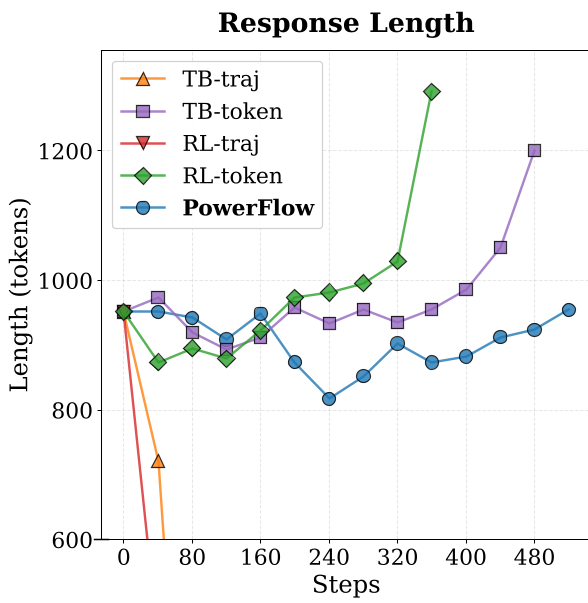
- 长度塌陷 (Length Collapse):模型发现短句子更容易获得高单位概率,于是回复变得极其敷衍。
- 模式崩溃 (Mode Collapse):为了降低熵值,模型反复输出完全相同的废话。
作者认为,问题的根源在于我们没有给模型一个原则性的优化目标。
方法论详解:LA-TB 与 $\alpha$-幂分布的直觉
1. 将微调视为分布匹配
与其去凑奖励值,不如直接让微调后的策略 $\pi_ heta$ 去拟合一个理想的目标分布。作者选择了统计力学中的 $\alpha$-阶陪同分布($\alpha$-order escort distribution): $$p_{\alpha}(y|q) \propto p_{base}(y|q)^{\alpha}$$
- 当 $\alpha > 1$ 时:分布变尖锐,模型会将概率质量集中在那些高质量的推理路径上。
- 当 $\alpha < 1$ 时:分布变平滑,模型会探索那些被“对齐”算法压抑的长尾创意区域。
2. LA-TB:应对自回归的“毒性”
在自回归模型中,路径概率随长度呈指数衰减。为了解决这个问题,作者提出了**长度感知轨迹平衡(Length-aware Trajectory-Balance, LA-TB)**目标函数:
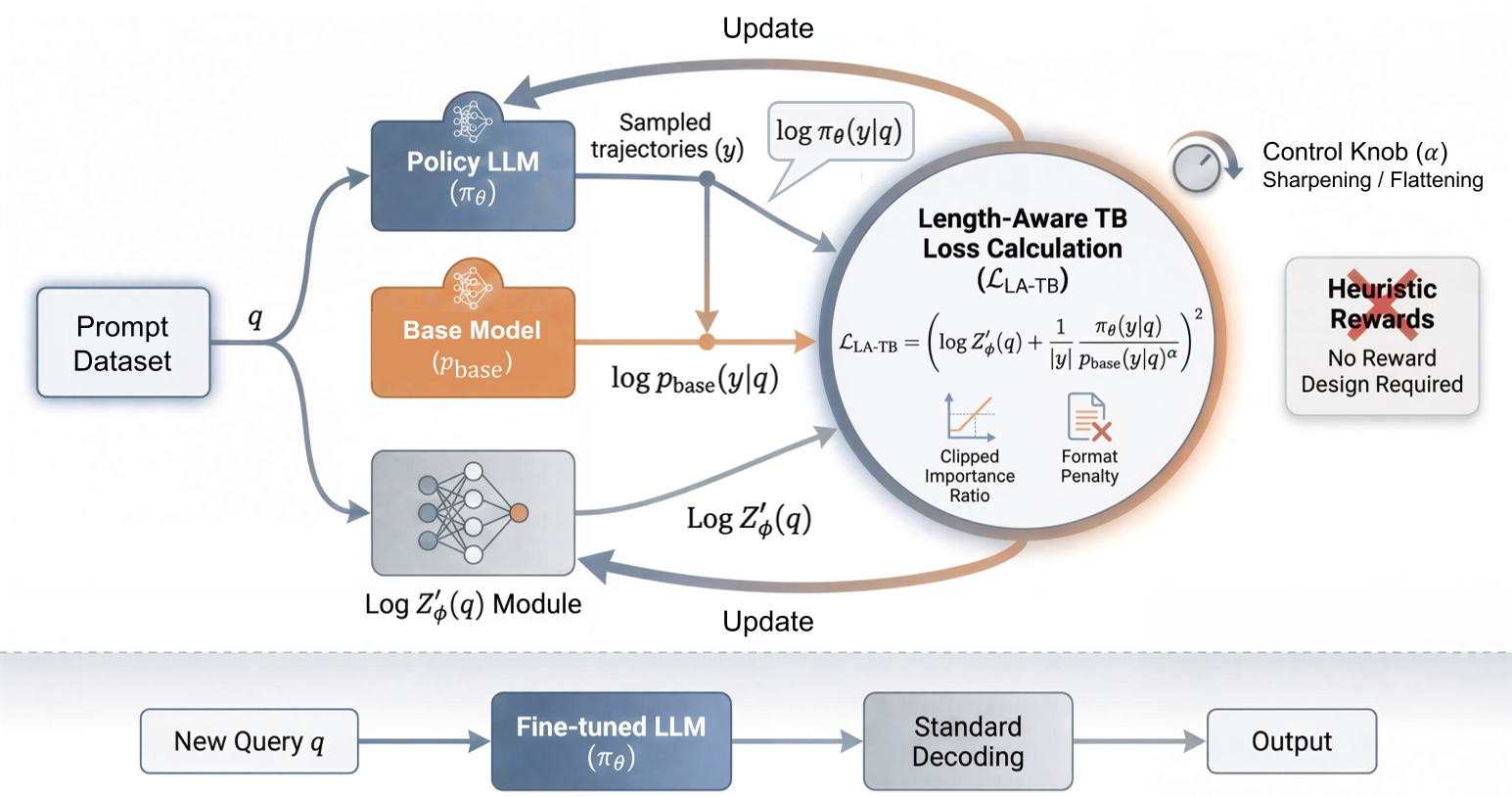
该公式巧妙地将配分函数 $Z$ 参数化为长度相关的能级,使得梯度在不同长度的序列间保持尺度不变性(Scale-invariant)。
实验结果:无监督也能赢过有监督?
逻辑推理:不仅更准,而且更博
在 MATH500 和 AIME 等硬核数学榜单上,PowerFlow ($\alpha=4$) 展现出了惊人的增长:
- 在 Qwen2.5-1.5B 上,准确率从 5.88 飙升至 19.85,甚至超过了使用真值验证(Verifiable Rewards)的 GRPO。
- 多样性实验证明,PowerFlow 不会像传统方法那样只死磕一条解题路径,它能保持极高的策略多样性。
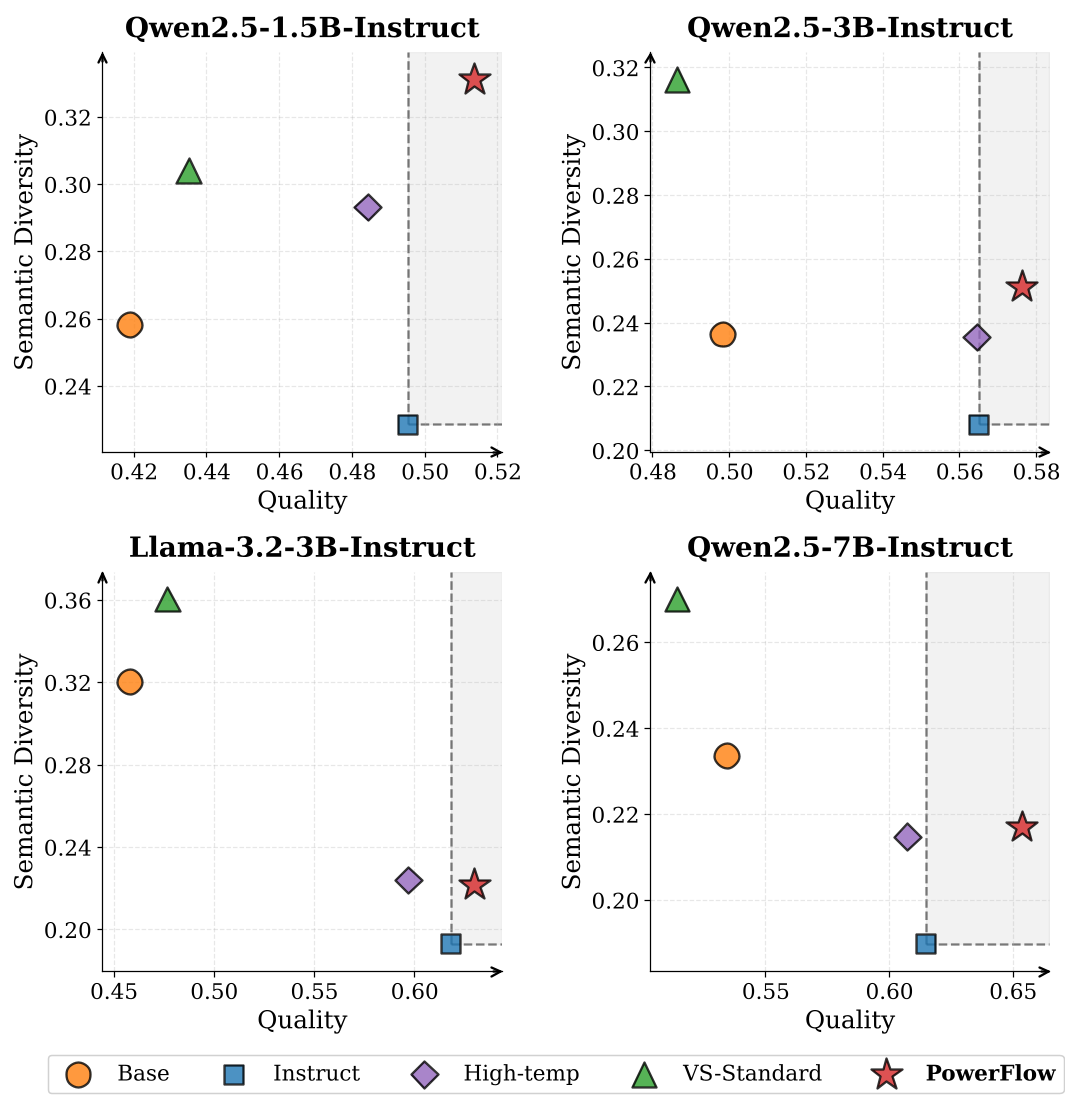
创造力:打破“平庸之恶”
对齐后的模型(Instruct 版)往往为了安全而变得平庸。PowerFlow 通过 $\alpha=0.5$ 的平滑化,成功地将模型的创意多样性推向了新的帕累托前沿。
深度洞察:分布的几何学
PowerFlow 的成功向我们传递了一个深刻的启示:LLM 其实什么都知道,只是它“没想好”该说哪个答案。
- 推理不是因为学会了新知识,而是通过锐化把概率从搅混水中拨开,让正确的思维链浮现。
- 创意不是因为模型变聪明了,而是通过平滑把那些被强行压扁的创意芽胞重新释放出来。
局限性与挑战
尽管 PowerFlow 表现优异,但其 $\alpha$ 参数目前仍需根据模型规模(Scale)手动调节。未来,如何根据生成内容的实时反馈动态调整“冷热程度”($\alpha$ 调度器),将是通往全自动自我进化模型的关键一步。
总结:PowerFlow 为 LLM 的后训练提供了一个透明、稳定且充满数学美感的框架。它告诉我们,对齐不仅是约束,更是一种对模型内在几何结构的精准重塑。