本文提出了 Prefill-as-a-Service (PrfaaS),一种跨数据中心的 LLM 推理架构。该架构利用新型混合注意力机制(Hybrid-attention)极低的 KVCache 占用,配合选择性卸载(Selective Offloading)策略,实现了在普通以太网带宽下跨集群、跨数据中心的预填充(Prefill)与解码(Decode)解耦。
TL;DR
Moonshot AI 与清华大学的研究团队提出了 Prefill-as-a-Service (PrfaaS)。其核心逻辑是:既然下一代大模型(如 Kimi Linear)通过混合注意力机制能将 KVCache 缩小一个数量级,那么我们就不再需要把昂贵的 GPU 锁死在昂贵的 RDMA 网络里。通过 PrfaaS,你可以把 Prefill 任务丢到千里之外的计算集群,生成的 KVCache 跑在最廉价的标准以太网上。
1. 痛点:被 RDMA “锁死”的 LLM 推理
在目前的 LLM 服务中,Prefill-Decode (PD) 分离已是标配。但在实际部署时,人们发现一个尴尬的现实:Prefill 生成的 KVCache 太大了(尤其是 Dense 模型),这导致 Prefill 节点和 Decode 节点必须像连体婴儿一样,被绑在同一个高性能 RDMA 织网内。
这种“强耦合”带来了三大问题:
- 成本瓶颈:你必须在同一个机房堆满昂贵的网络设备。
- 资源僵化:无法利用其他机房闲置的计算密集型算力。
- 扩展困难:Prefill 需要主频和算力,Decode 需要显存带宽,但两者配比在不同流量下是动态变化的,单集群很难实时调整。
2. 破局:混合架构与“空间换时间”的终结
作者敏锐地观察到,模型架构正在发生质变。以 Kimi Linear、Qwen3.5 等为代表的混合注意力模型,通过引入线性注意力(Linear Attention)或滑动窗口(SWA),让 KVCache 的增长不再失控。
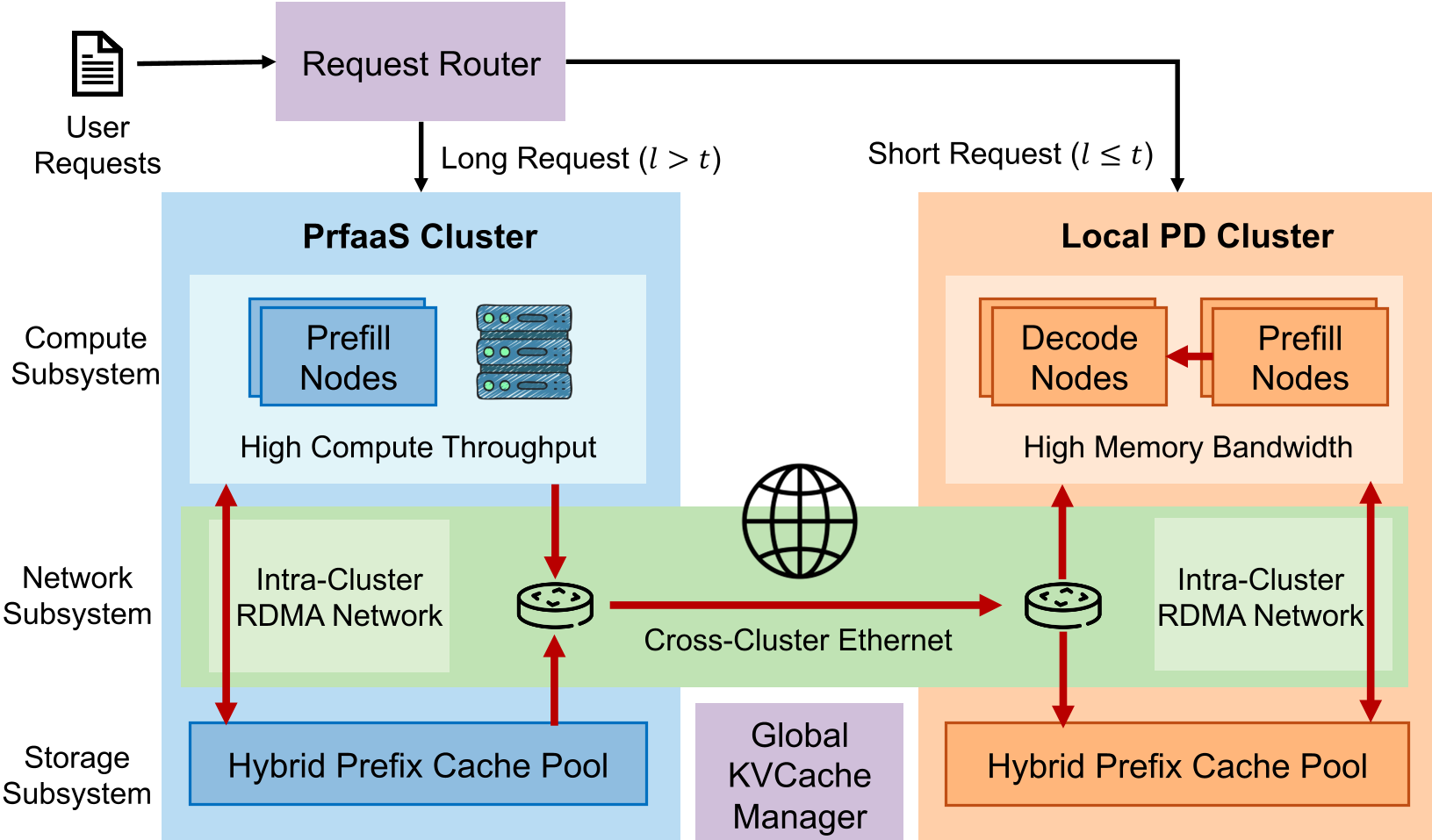 PrfaaS-PD 架构:长上下文 Prefill 被卸载到独立的 PrfaaS 集群,结果通过普通以太网传输。
PrfaaS-PD 架构:长上下文 Prefill 被卸载到独立的 PrfaaS 集群,结果通过普通以太网传输。
在 32K Token 长度下,混合模型的 KV 吞吐需求仅为 4.66 Gbps,而传统 Dense 模型高达 60 Gbps。这意味着,KVCache 的远程搬运从“不可能”变成了“极具性价比”。
3. 核心机制:PrfaaS 如何工作?
仅仅模型 KVCache 变小还不够,PrfaaS 在系统层面做了三件事:
选择性卸载 (Selective Offloading)
并非所有请求都去跑长途。PrfaaS 设定了一个长度阈值 :
- 短请求:留在本地路由,减少往返延迟。
- 长请求:送往算力更强的 PrfaaS 集群。 这种策略确保了异构加速器(如擅长计算的 H200 与擅长带宽的 H20)能各司其职。
混合前缀缓存池 (Hybrid Prefix Cache Pool)
混合模型存在两种状态:线性注意力层的“请求级状态”和全注意力层的“块级 KVCache”。PrfaaS 重新设计了缓存管理器,支持这两种异构状态的统一存储与跨集群同步,最大化缓存命中率。
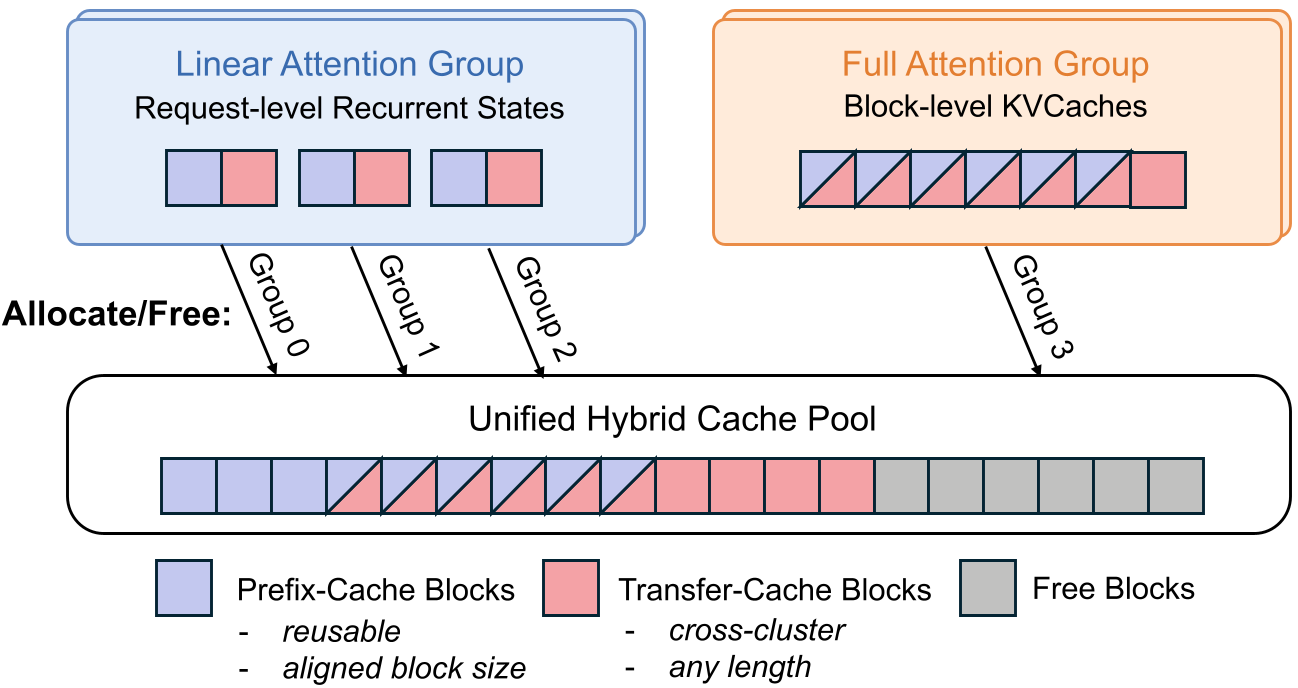
带宽感知调度
互联网带宽是波动的。PrfaaS 的调度器会实时监控出口链路利用率。如果网络拥堵,它会动态调高阈值 ,让更多任务回流本地,优先保证 SLO(服务等级目标)。
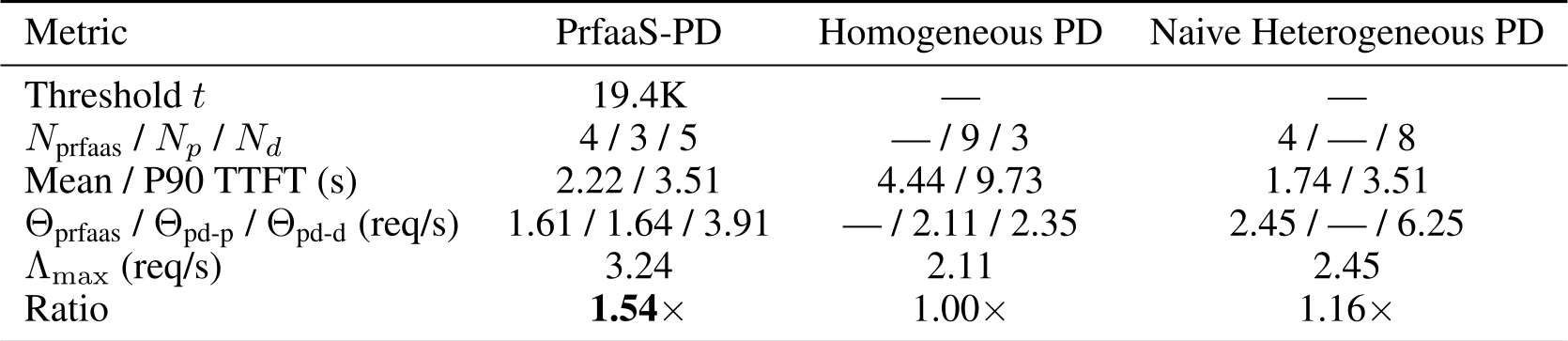
4. 实验战绩:性能与带宽的“双赢”
研究团队通过 1T 参数的混合模型验证了该架构。结果令人振奋:
- 吞吐量翻倍:相比传统的同构部署,PrfaaS 提升了 54% 的总吞吐。
- 延迟骤减:长上下文请求的 P90 首字延迟(TTFT)降低了 64%。
- 带宽极省:核心实验中,跨数据中心传输仅消耗了 13 Gbps 的带宽,这对现代数据中心互联来说只是“洒洒水”。
5. 深度洞察:推理的未来是“云化”
PrfaaS 的成功实际上标志着 LLM 推理从“单机/单集群”模式走向了“服务化/全球化”模式。
局限性谈及:当然,该方案高度依赖模型层面的 KVCache 极致压缩。如果未来模型重新回归全量 Dense 注意力,PrfaaS 的优势将受限。此外,跨地域传输带来的物理光速延迟(RTT)依然是短文本请求的“天敌”。
总结:PrfaaS 证明了,只要模型设计足够聪明(KV-efficient),系统调度足够精细(Bandwidth-aware),我们就能打破机房的物理边界。未来的算力中心可以像发电厂一样,Prefill 在西部廉价能源区“发电”,Decode 在东部消费区“送电”。