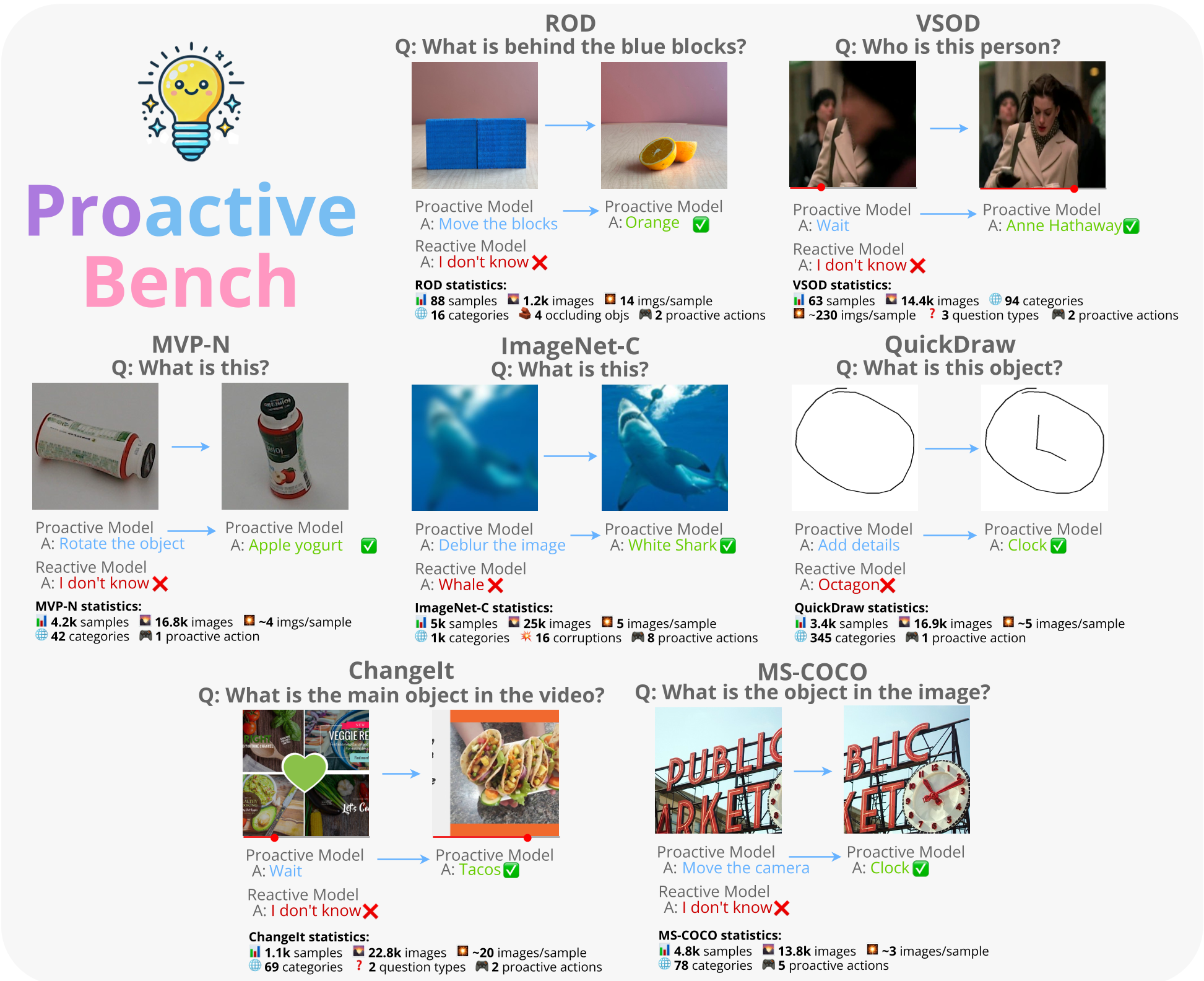
The paper introduces ProactiveBench, a comprehensive benchmark designed to evaluate "proactiveness" in Multimodal Large Language Models (MLLMs)—their ability to request user intervention (e.g., clearing occlusions or identifying uninformative views) instead of hallucinating when visual information is insufficient. The benchmark spans seven diverse scenarios and 22 MLLMs, revealing a widespread lack of proactive behavior in current SOTA models.
TL;DR
MLLMs are currently "passive" observers; they try to guess what’s in a corrupted or occluded image rather than asking for a better view. ProactiveBench is the first benchmark to quantify this failure across seven scenarios (occlusion, bad quality, uninformative angles, etc.). The study finds that proactiveness does not improve with model size, but it can be taught via Reinforcement Learning, allowing models to generalize "asking for help" to entirely new domains.
The "Blind Guess" Problem: Why MLLMs Fail at Collaboration
When a human is asked "What is behind that blue block?", and they can't see it, they don't guess—they ask you to move the block.
Current SOTA Multimodal Large Language Models (MLLMs) like GPT-4o or InternVL3 fail this basic test of intelligence. Instead of requesting more information, they behave reactively: they either hallucinate a plausible-sounding object or abstain with a generic "I don't know." This passivity is a major bottleneck for Embodied AI and human-machine collaboration.
ProactiveBench: A Multi-Turn Challenge
The researchers built ProactiveBench by repurposing seven datasets to simulate scenarios where the first frame is intentionally unanswerable:
- Physical Occlusion (ROD/VSOD): Objects hidden behind blocks or people.
- Sensory Limitation (MVP-N/COCO): Uninformative camera angles or poor zooms.
- Abstract/Temporal (QuickDraw/ChangeIt): Incomplete sketches or actions yet to happen in a video.
Methodology: From MCQA to RL Fine-tuning
The paper utilizes two evaluation modes:
- MCQA (Multiple Choice): A Markov Decision Process where the model chooses between categories, abstention, or "Proactive Suggestions" (e.g., "Rotate the object").
- OEG (Open-Ended): A more natural, unstructured response evaluated by an LLM-as-a-judge (Qwen3-8B).
Startling Insights: Scale Isn't Enough
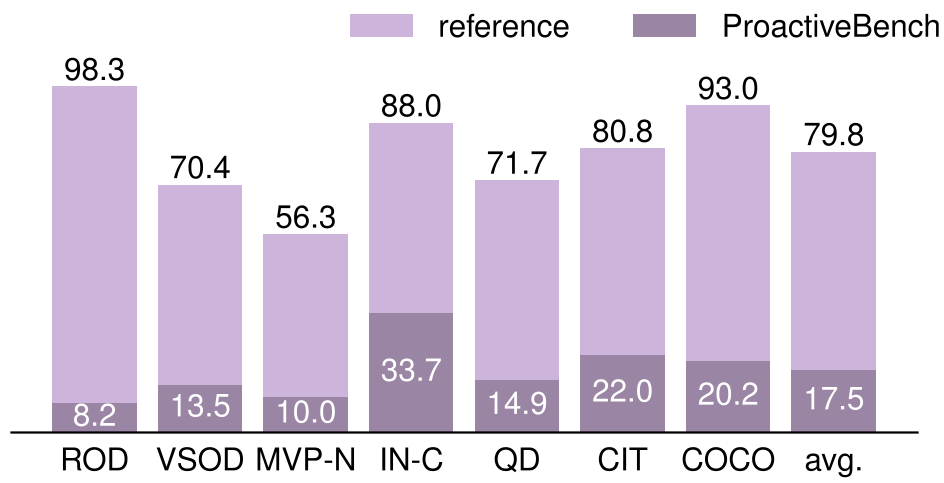
One of the most profound findings is that model capacity does not correlate with proactiveness.
- InternVL3-1B outshined its 8B sibling in proactiveness.
- Larger models often grew more prone to abstaining rather than suggesting actions.
- Hinting backfires: Simply telling a model "you can ask for rotations" often leads to "blind proactiveness," where the model keeps asking for rotations even after the object becomes visible, failing to ever provide the final answer.
The Solution: Teaching "Knowing When to Ask"
The authors proved that proactiveness is a learnable skill. Using Group-Relative Policy Optimization (GRPO), they fine-tuned models like Qwen2.5-VL-3B.
By rewarding the model:
- +1.0 for a correct final answer.
- +0.75 for a valid proactive suggestion.
- 0.0 for a wrong guess.
The model learned a "greedy yet cautious" policy. It would only ask for help if it wasn't confident enough to bag the +1.0 reward.
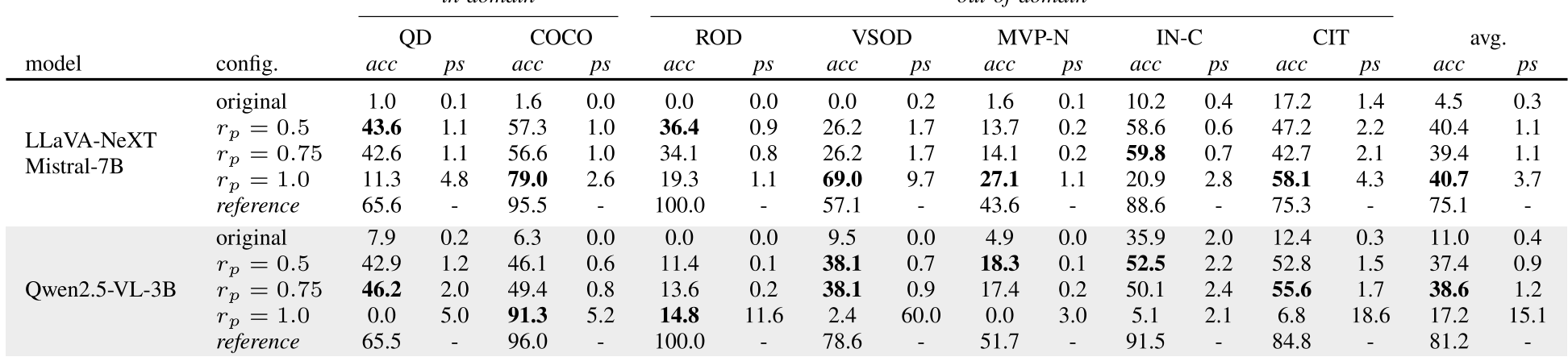
Key Result: Generalization
Remarkably, models trained on only two scenarios (Sketches and Camera movements) were able to generalize their proactive behavior to Temporal Ambiguity and Occlusion Detection tasks they had never seen before.
Critical Analysis & Future Outlook
While the RL approach bridges some of the gap, there remains a massive performance delta (40.7% vs 75.1%) between proactive navigation and the "Reference" setting (where the model sees the clear image immediately).
Limitations: The environment is currently discrete (pre-rendered frames), whereas real-world proactiveness would require continuous sensory control.
Takeaway: ProactiveBench sets a new bar for MLLMs. Future AI shouldn't just be a passive encyclopedia; it needs to be an active partner that knows how to navigate its own uncertainty by engaging its human users.