本文提出了 Prune-OPD,一种针对长程推理任务的在线策略蒸馏(On-Policy Distillation)优化框架。通过实时监测学生与教师模型在当前前缀下的局部兼容性,动态调整训练权重并截断不可靠的生成路径,显著提升了蒸馏效率。
TL;DR
在大型语言模型(LLM)的后训练阶段,在线策略蒸馏(On-Policy Distillation, OPD) 因能提供密集的 Token 级反馈而备受青睐。然而,长程推理任务中的“前缀漂移”常导致教师奖励变得不可靠。本文提出的 Prune-OPD 通过实时监控学生与教师的“局部兼容性”,实现了奖励权重的动态衰减与自动 Rollout 截断。在不损失精度的前提下,它成功砍掉了 68% 的冗余训练时间。
1. 动机:当教师不再理解学生的“胡言乱语”
传统的 OPD 假设教师模型在学生访问的任何状态下都能给出有意义的指引。但在数学推理等长序列任务中,这通常是一个伪命题:
- 前缀漂移 (Prefix Drift):随着推理步骤变长,学生模型生成的中间步骤(前缀)难免会偏离教师的逻辑。
- 奖励失效:一旦逻辑脱轨,教师模型强制施加的分布反馈就变得“食之无味”,甚至会因为过度拟合教师在错误前缀下的分布而导致性能受损。
- 算力浪费:在已经漂移的轨迹上继续采样数千个 Token 并计算教师对齐损失,是极其昂贵的。
2. 核心机制:Prune-OPD 的“外科手术”
Prune-OPD 引入了一个关键的在线监控指标:局部兼容性(Local Compatibility)。
A. top-k 重叠率 (Overlap Ratio)
作者通过计算学生 和教师 在同一位置 top-k 候选 Token 集合的重叠比例 来量化一致性。 当重叠率低于门槛(如 0.7)时,判定为一次“漂移事件”。
B. 权重衰减与动态截断
不同于简单粗暴的直接过滤,Prune-OPD 采用了单调非增权重策略:
- 累积漂移:统计当前轨迹中发生漂移事件的总数 。
- 奖励缩放:根据 动态衰减后续位置的 OPD 奖励权重。
- 动态预算控制:由一个控制器实时监测 Batch 中的有效可靠长度(Effective Length),当大多数样本已经失去监督价值时,自动缩短下一个 Step 的生成长度限制。
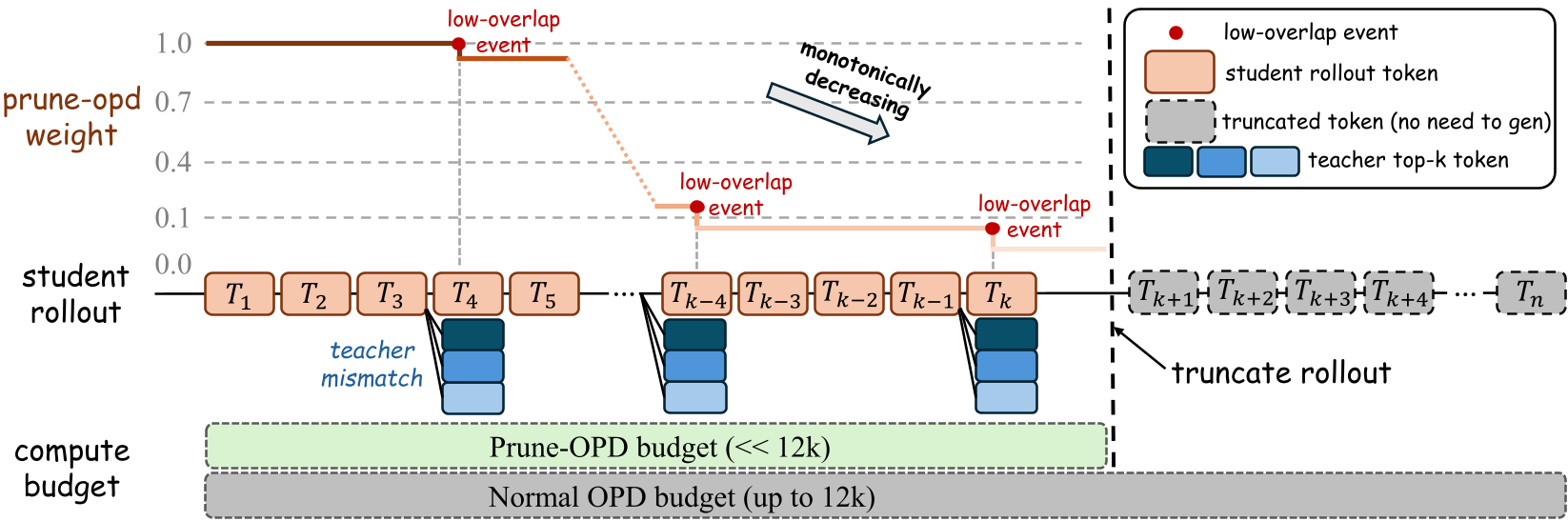 图 1:Prune-OPD 概念概览:监控兼容性 -> 衰减权重 -> 截断无效生成。
图 1:Prune-OPD 概念概览:监控兼容性 -> 衰减权重 -> 截断无效生成。
3. 实验结果:用更少的钱办更多的活
研究者在多个教师-学生配对(包括 DeepSeek-R1 蒸馏系列和 Qwen3)上进行了验证,结果令人印象深刻。
训练效率的飞跃
在 Qwen3 内部蒸馏实验中,Prune-OPD 在保持推理准确率的同时,将训练耗时降低了 37.6%–52.6%;在 DeepSeek 系列中,甚至达到了 68% 的时间缩减。
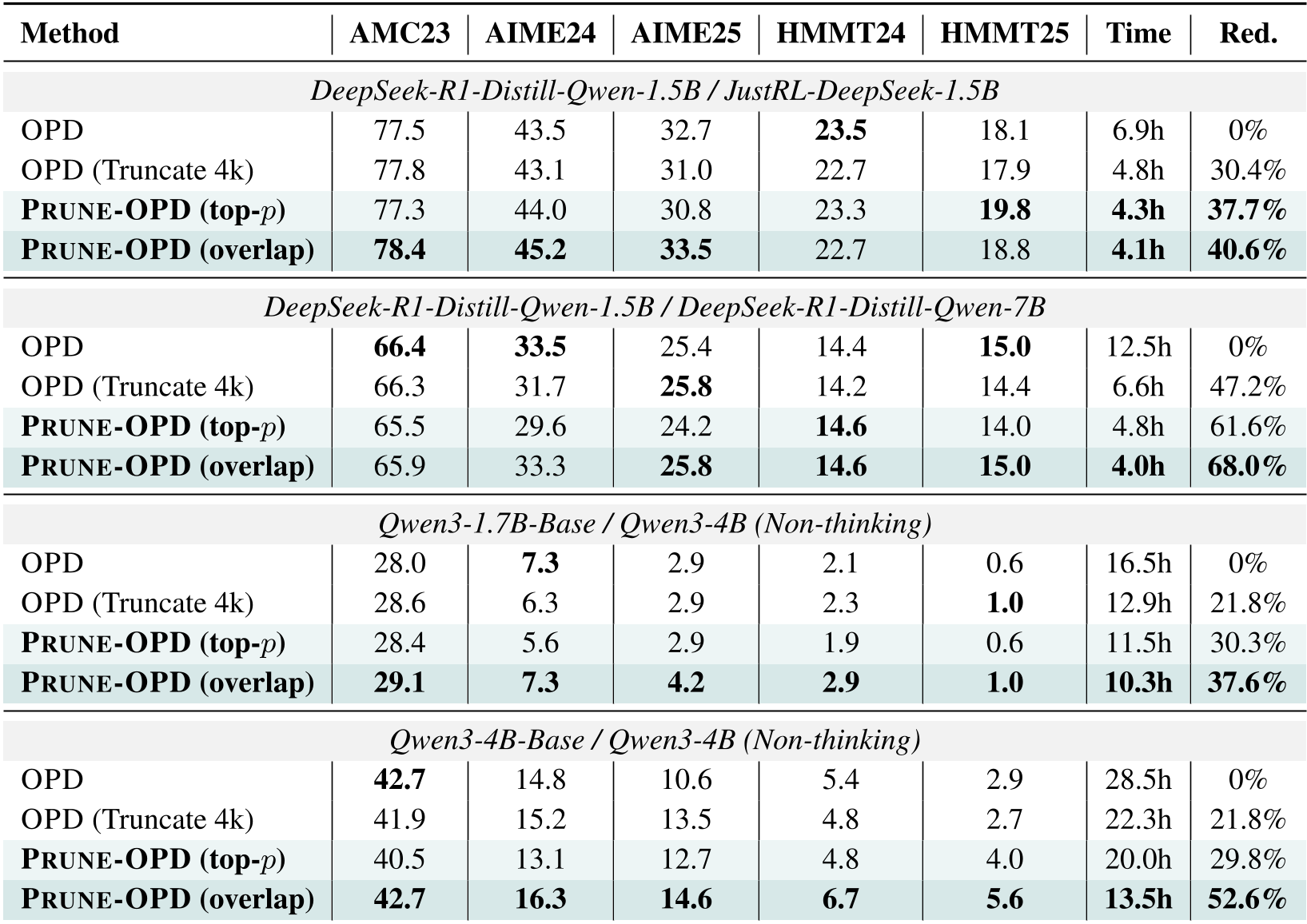 表 1:不同模型组合下的性能与时间缩减对比,可见其在减负方面的卓越表现。
表 1:不同模型组合下的性能与时间缩减对比,可见其在减负方面的卓越表现。
自适应行为
Prune-OPD 最精妙之处在于它的非盲目性。如果学生和教师非常默契(高兼容性),系统会自动保持或延长 Rollout 窗口(见下图左、中),以捕捉长程的长尾价值;只有当信号变质时,它才会开启“加速模式”。
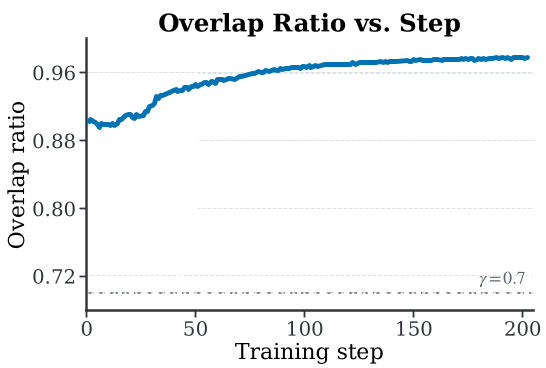 图 2:在高兼容性场景下,Prune-OPD 自动维持长上下文监督。
图 2:在高兼容性场景下,Prune-OPD 自动维持长上下文监督。
4. 深度洞察:为什么它能比 OPD 效果更好?
在 Qwen3 的一些实验中,Prune-OPD 甚至超过了原始 OPD 的准确率。这并非巧合,而是源于梯度去噪(Gradient Denoising): 在长程推理末端,无效梯度往往多于有效梯度。通过切除不可靠的后缀,模型能将优化注意力集中在教师真正“理解”的前缀部分。
5. 总结与未来展望
Prune-OPD 证明了:在 LLM 的长程推理学习中,对监督质量的动态感知比盲目堆砌算力更重要。
- 局限性:目前主要依赖 Top-k 统计,可能在语义相同但词汇不同的路径上误判。
- 未来方向:一个令人兴奋的方向是将 Prune-OPD 与 GRPO 结合——在教师可靠时进行蒸馏,在漂移后自动通过强化学习进行自我探索。
这项工作不仅为 LLM 训练节省了碳排放,更为我们理解“教师-学生”模型在长链思考中的对齐动态提供了珍贵的实证数据。