Qwen3.5-Omni is a natively omnimodal large language model from Alibaba's Qwen team that unifies processing and generation for text, vision, and audio. It utilizes a Thinker–Talker MoE architecture and achieves SOTA results on 215 multimodal benchmarks, matching or exceeding competitors like Gemini-3.1 Pro in audio-visual reasoning and speech synthesis.
Executive Summary
TL;DR: Qwen3.5-Omni represents a massive leap in the Qwen-Omni family, scaling to hundreds of billions of parameters with a 256k context window. It moves beyond passive perception to become a Native Omni Agent, capable of real-time streaming interaction, zero-shot voice cloning, and a novel emergent capability termed "Audio-Visual Vibe Coding" (generating code directly from audio-visual cues).
Historically, multimodal models have been "franken-models"—pieced together with separate encoders. Qwen3.5-Omni, however, is natively pretrained on over 100 million hours of audio-visual content, positioning it as a top-tier competitor to the likes of Gemini-3.1 Pro and GPT-4o.
The Pain Point: The Synchronization Struggle
Most existing multimodal LLMs face two critical hurdles:
- Temporal Drift: Forgetting the timing of specific events in long videos or audio clips.
- The Tokenization Gap: Speeding through text while lagging on audio tokens (or vice versa) during streaming leads to skipped words, unnatural emotional shifts, and "stuttering" in voice responses.
The Qwen team identifies that prior work (including their own Qwen3-Omni) struggled with the mismatch between text and speech tokenization rates.
Methodology: The Thinker-Talker Architecture & ARIA
Qwen3.5-Omni utilizes an evolved Thinker-Talker architecture. The Thinker handles the cross-modal reasoning, while the Talker focuses on high-fidelity speech synthesis.
1. Hybrid-Attention MoE
Both modules now use a Hybrid-Attention Mixture-of-Experts (MoE) design. This allows the model to be massive in capacity but efficient in inference by only activating a subset of parameters. It specifically employs Gated Delta Net (GDN) to accelerate long-sequence modeling, enabling the processing of 10+ hours of audio or 400 seconds of 720P video.
2. ARIA: Adaptive Rate Interleave Alignment
The "secret sauce" for the Talker is ARIA. Instead of dual-track generation which often drifts apart, ARIA treats text and speech as a unified interleaved stream. It enforces an adaptive rate constraint to ensure the speech-to-text token ratio remains globally aligned, drastically improving prosody and stability.
 Figure 1: The High-level architecture showing the end-to-end flow from multimodal input to streaming response.
Figure 1: The High-level architecture showing the end-to-end flow from multimodal input to streaming response.
Experiments & Results: Dominating Audio and Video
The evaluation of Qwen3.5-Omni was rigorous, spanning 215 subtasks.
- ASR & Translation: Qwen3.5-Omni-Plus hit a 6.6% average WER on FLEURS, beating Gemini-3.1 Pro. Its performance in Cantonese and Japanese was particularly dominant compared to OpenAI's Whisper or Google's models.
- Agentic Capabilities: The model achieved 57.2% on OmniGAIA, a benchmark for tool-use in multimodal settings.
- Voice Cloning: It supports Zero-shot Voice Customization, where a user can provide a short sample and the model clones the timbre and emotional nuance across 10 languages with high fidelity.
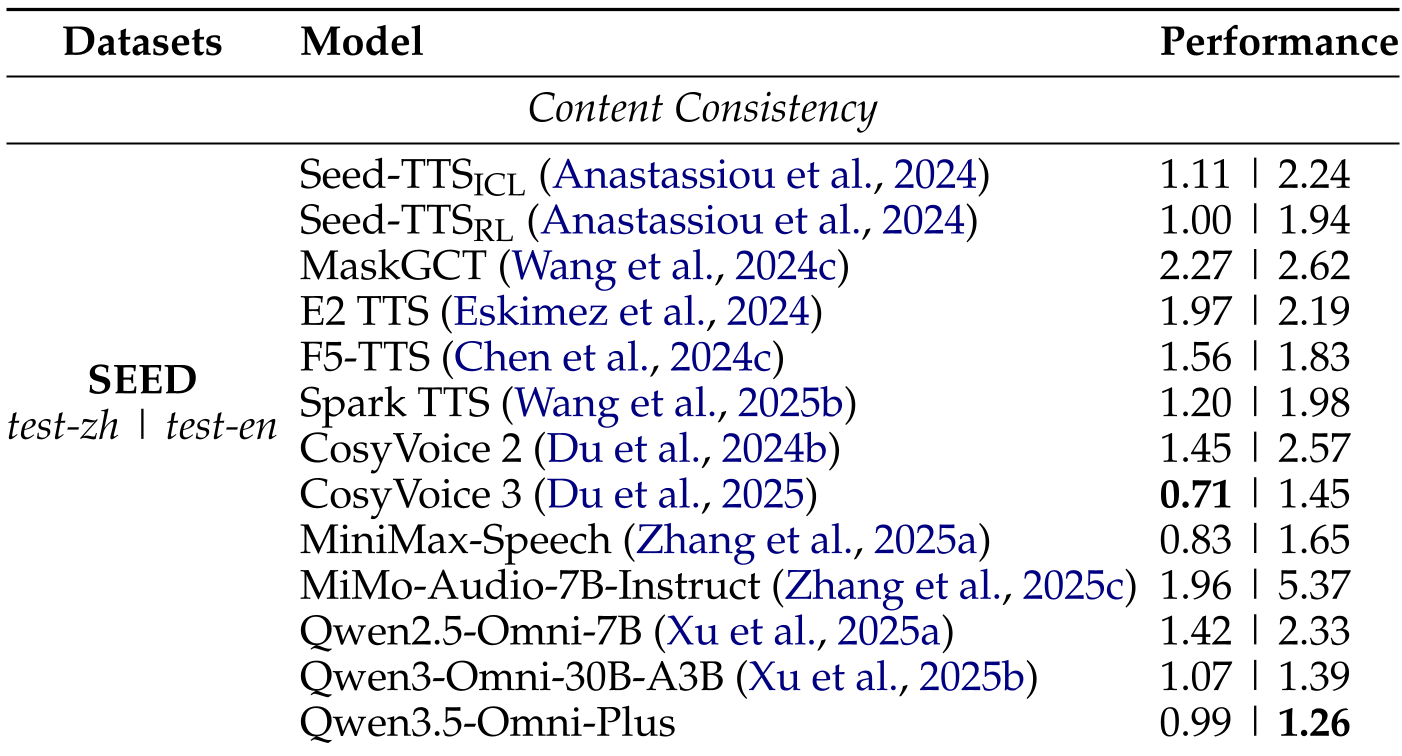 Table 1: Content Consistency evaluation on SEED-TTS; Qwen3.5-Omni-Plus sets or matches SOTA benchmarks.
Table 1: Content Consistency evaluation on SEED-TTS; Qwen3.5-Omni-Plus sets or matches SOTA benchmarks.
The Emergence of "Vibe Coding"
Perhaps the most intriguing part of the report is the mention of Audio-Visual Vibe Coding. Unlike traditional RAG or coding assistants that take text prompts, Qwen3.5-Omni can observe a video of a software bug or listen to a description of a desired UI and generate the executable code directly—no intermediate text descriptions required.
Critical Insight: Why it Matters
Qwen3.5-Omni isn't just a bigger model; it's a more precisely aligned one. By moving from absolute temporal markers (TMRoPE) to explicit text-string timestamps within the sequence, the model avoids "positional sparsity" that plagues other long-context models.
Takeaway for the Industry: Native omnimodal training is moving toward low-latency interaction. The first-packet latency for audio inputs on the Flash variant is a staggering 235ms, making it truly viable for real-time human-AI conversation.
Limitations
Despite the SOTA results, the report notes that high-concurrency environments still face challenges in maintaining the end-to-end "critical path" latency for high-resolution video streams. Future work will likely need to focus on further reducing the computation overhead for the Vision Encoder during video streaming.
For more details on the training pipeline (S1-S3 stages) and technical benchmarks, see the full Technical Report by the Qwen Team.