The paper introduces Rays as Pixels (Raxels), a unified Video Diffusion Model (VDM) that learns a joint distribution over video frames and camera trajectories. By representing camera parameters as dense 3-channel "raxel" images, the model achieves SOTA performance in camera-controlled video generation and competitive results in camera pose estimation within a single 20B parameter framework.
Executive Summary
TL;DR: Researchers have traditionally treated "where the camera is" and "what the camera sees" as two separate problems. Rays as Pixels (Raxels) breaks this wall by training a massive 20B parameter Video Diffusion Model to learn the joint distribution of both. By turning abstract camera matrices into 3-channel "raxel" images, the model can predict motion from video, generate video from motion, or do both simultaneously.
Context: This isn't just another video generator. It sits at the intersection of Generative AI and 3D Vision (SfM/SLAM), proving that a single generative backbone can handle both forward synthesis and inverse geometric inference.
The Core Insight: Why Decoupling Fails
In a standard pipeline (e.g., NeRF or Gaussian Splatting), you first run a tool like COLMAP to get camera poses, then train your model. If the input images are sparse, COLMAP fails, and the whole house of cards collapses.
The authors argue that Forward (Generation) and Inverse (Pose Estimation) processes are two sides of the same coin. A model that understands the underlying 3D geometry of a scene should be able to hallucinate the camera path just as easily as it hallucinates the pixels.
Methodology: Cameras as Image Tensors
The technical hurdle was making camera parameters (usually 4x4 matrices) "digestible" for a Video Diffusion Transformer (Wan 2.1).
1. The Raxel Representation
Instead of feeding matrices into an MLP, the authors create Raxels (Ray-Pixels). For every pixel , they calculate the ray's origin and direction in a canonical coordinate system. The raxel value is simply the sum .
- Compatibility: Because it's a 3-channel map, it can be compressed by the exact same VAE used for video frames.
- Alignment: It preserves spatial correspondence. A "pixel" in the camera map corresponds to the same "pixel" in the video frame.
2. Decoupled Self-Cross Attention
To prevent the high-frequency texture of video from "polluting" the smooth geometric signals of camera rays, the model uses a dual-branch attention mechanism:
- Self-Attention: Stabilizes the video sequence and camera trajectory independently.
- Cross-Attention: Allows the video to follow the camera rays and the rays to refine based on visual landmarks.
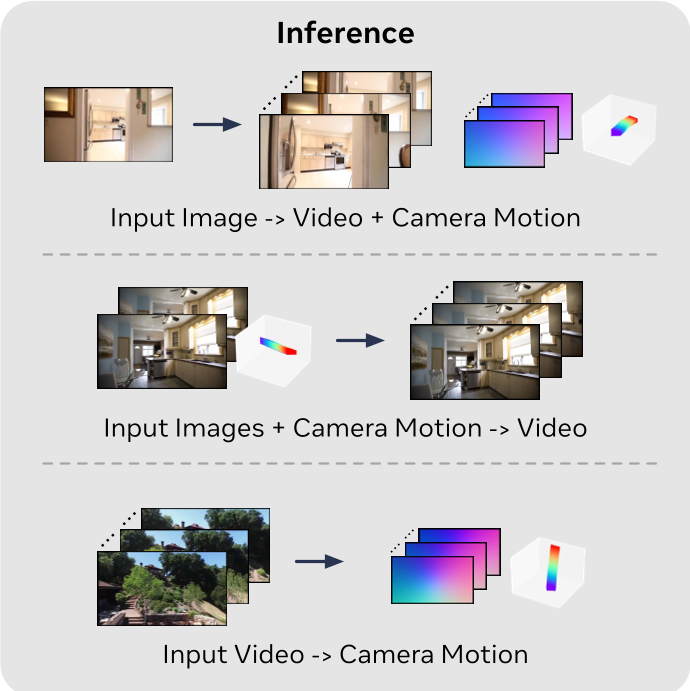
Experiments: The Self-Consistency Test
The most impressive part of the paper is the Closed-Loop Self-Consistency Test. Use the model to:
- Predict trajectories from a video .
- Re-generate video using those predicted trajectories .
If the model truly learns the joint distribution , then should look identical to . Raxels pass this test with flying colors, whereas older methods like Plücker embeddings fall apart.

Key Results
- Visual Quality: Achieved an FID of 9.73 on the DL3DV-140 benchmark, a significant leap over previous SOTA like Kaleido (18.04).
- Efficiency: Trajectory prediction (pose estimation) requires only 2 denoising steps, making it exponentially faster than traditional optimization-based SfM.
Critical Analysis & Future Outlook
Rays as Pixels is a sophisticated "repurposing" of large-scale video models. It suggests that the next generation of "World Simulators" won't just output pixels; they will output a coherent 4D understanding of space and movement.
Limitations:
- Static Bias: The model is trained on Re10K and DL3DV (mostly static real estate/scenes). It might struggle with "dynamic" movements like a person running through a shot.
- Scale: At 20B parameters, it is a heavyweight model.
Takeaway: The "Raxel" concept is a blueprint for integrating any meta-data (depth, semantics, poses) into diffusion models. By treating everything as a spatially-aligned pixel latent, we unlock the full power of pretrained visual backbones for geometric reasoning.
Technical interpretation by Senior Academic Tech Editor.