本文提出了 Multi-Answer RL,这是一种直接训练语言模型在单次前向传递中生成多个候选答案及其置信度的强化学习方法。该方法在医疗诊断(DDXPlus)、多步推理(HotPotQA)和代码生成(MBPP)任务中显著提升了答案的覆盖率和多样性,同时大幅降低了推理成本。
TL;DR
传统的强化学习(RL)正在把大模型变成“死脑筋”——它们只追求那个最高奖励的单一答案,却丢失了探索可能性的能力。MIT 团队提出的 Multi-Answer RL 改变了这一游戏规则。它不再让模型多次采样,而是训练模型在单次生成中直接输出一个包含多个候选答案及其置信度的“概率分布”。结果显示:在代码生成上效率翻倍,在医疗诊断上覆盖度大幅领先。
背景定位:当“标准答案”成为枷锁
在 Open-source RL 蓬勃发展的今天(如 DeepSeek-R1),我们发现大模型在数学和策略任务上突飞猛进。然而,这种基于奖励的优化存在严重的副作用:熵压缩(Entropy Collapse)。模型变得极度过度自信,且输出趋同。
这在以下场景是致命的:
- 医疗诊断:一个症状可能指向多种疾病,模型只给一个结论会造成漏诊。
- 编程开发:解决一个 Bug 通常有多种算法路径,单一模式限制了开发者的选择。
- 模糊问答:当信息不足时,模型应该能够“对冲(Hedge)”风险,给出多种可能性。
核心动机:效率与多样性的双重鸿沟
作者指出,目前的 SOTA 方法(如 Best-of-N)依赖于推理时的大量重复采样。这不仅慢,而且由于模型已经被训练得只会说一种话,采样的样本往往高度重合(n-gram Overlap 极高)。
作者的直觉(Insight):如果多样性和校准度是好模型的标准,那么它们应该被写进 训练目标 里,而不是靠推理技巧去“碰运气”。
方法论:Multi-Answer RL 架构解析
1. 从单一奖励到集合奖励 (Multi-Answer RLVR)
传统的 RLVR 奖励 。而 Multi-Answer RLVR 要求模型在单次 CoT 中输出 。其奖励函数改为: 这意味着模型每多找对一个可能的答案,奖励就会累加。为了防止模型耍赖(重复输出同一个对的答案),作者还加入了 Uniqueness Reward。
2. 校准每一个可能性 (Multi-Answer RLCR)
光有答案不够,AI 必须知道自己有多大把握。作者引入了 Multi-Brier Score,通过惩罚置信度 与实际对错之间的平方差,强制模型输出的每一个概率都有物理意义。
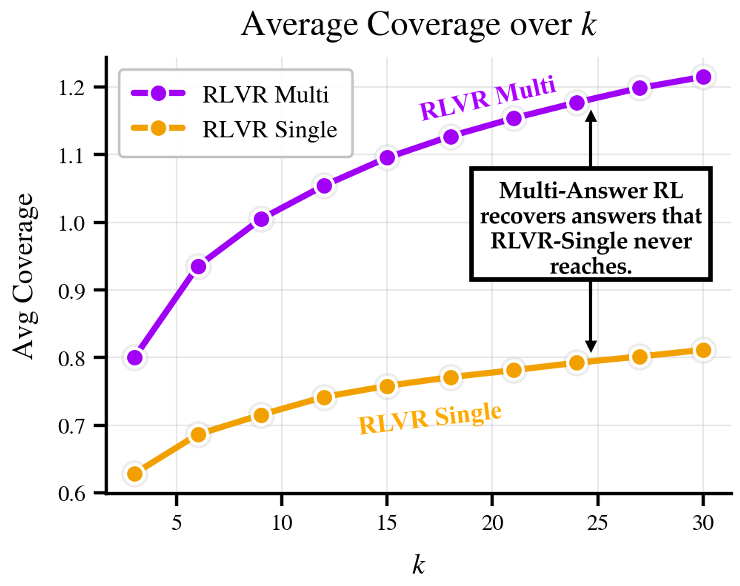 图 1:标准 RL (左) 导致模式收敛,而 Multi-Answer RL (右) 训练模型输出多样化的分布。
图 1:标准 RL (左) 导致模式收敛,而 Multi-Answer RL (右) 训练模型输出多样化的分布。
实验与结果:全方位碾压传统采样
核心战绩:效率与准确率的齐飞
在 MBPP 代码基准测试中,Multi-Answer RL展现了恐怖的实力:
- 准确率:Pass@1 相比传统 RLVR 提升了约 50%。
- 计算效率:生成 3 个独立方案所需的 Token 数量降低了 50% 以上(如图 7 所示)。
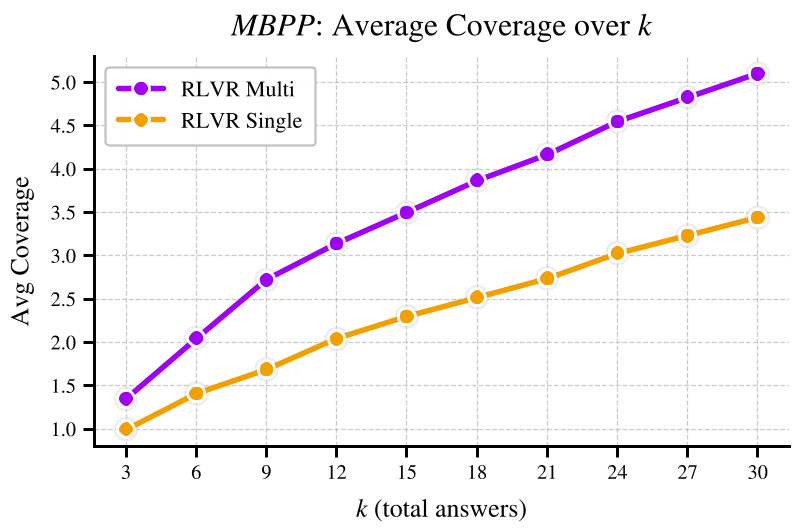 图 2:在 MBPP 和 DDXPlus 任务中,即便采样预算相同,Multi-Answer RL (绿色) 找到的独特正确答案远多于单答案模型 (紫色)。
图 2:在 MBPP 和 DDXPlus 任务中,即便采样预算相同,Multi-Answer RL (绿色) 找到的独特正确答案远多于单答案模型 (紫色)。
深度分析:它为什么更快?
通过视觉化分析发现,传统模型在多次采样时,推理链(CoT)的大量步奏是重复的。而 Multi-Answer 模型在同一个推理流程中通过“分头行动”,共享了前面的背景理解,极大地压缩了冗余 Token。
深度洞察与总结
本质提升在哪里?
Multi-Answer RL 的本质是将“推理时搜索”内化到了“模型生成过程”中。它不再是盲目地掷骰子(采样),而是通过一个更宽的视角在一次思考中权衡多个候选路径。
局限性与挑战
- Top-1 的轻微牺牲:在某些单答案任务中,由于模型需要分心考虑其他路径,其最强答案的绝对精度可能略逊于极度收敛的单模式模型。
- 串行生成的限制:虽然 Token 总数减少了,但目前的 LLM 架构本质上还是串行生成,无法完全发挥并行搜索的潜力。
总结
这项研究为 RL 训练提供了新的范式。未来的 LLM 不应该只是一个“答题机器”,而应该是一个能够量化不确定性、提供全盘方案的“决策智囊”。Multi-Answer RL 迈出了从“寻找唯一真理”到“理解知识分布”的关键一步。