The paper introduces a hybrid hierarchical control framework for reactive dexterous grasping using a 7-DoF arm and a 20-DoF anthropomorphic hand. It combines a Multi-Agent Reinforcement Learning (MARL) high-level planner for task-space commands with a GPU-parallelized Quadratic Programming (QP) low-level controller for joint-space execution, achieving robust zero-shot sim-to-real transfer.
TL;DR
Grasping a diverse set of objects with a 20-DoF anthropomorphic hand is notoriously difficult for standard Reinforcement Learning (RL) due to the "curse of dimensionality." This paper introduces a hybrid hierarchical framework that splits the job: a Multi-Agent RL planner decides "where to go" in task space, while a GPU-parallelized QP controller handles the "how to get there" by ensuring kinematic safety and collision avoidance. The result? A system that can recover from being shoved mid-grasp and can be adjusted for speed and safety on the fly without any retraining.
Problem & Motivation: The Learning Burden
In most end-to-end RL grasping research, a single neural network is expected to master three distinct, often conflicting objectives:
- Strategic Reasoning: Figuring out the best approach angle and finger placement.
- Kinematic Coordination: Mapping high-dimensional joint movements to spatial goals.
- Safety & Constraints: Avoiding self-collision and staying within joint limits.
When these are crammed into one reward function, the agent struggles with "reward interference." The authors argue that we should "let physics handle what is tractable by design, and use RL only where modeling is difficult."
Methodology: The Hybrid Hierarchy
The framework consists of two distinct layers:
1. High-Level MARL Planner (The Mind)
Inspired by human motor control, the researchers split the "mind" into two specialized agents:
- Arm Agent: Focuses on palm transport (Reach).
- Hand Agent: Focuses on fingertip manipulation (Grasp). By using Centralized Training with Decentralized Execution (CTDE), these agents learn to collaborate in task-space (velocity commands) rather than joint-space, which drastically reduces the exploration space.
2. Low-Level QP Controller (The Muscle)
Instead of letting the RL guess the kinematics, a Quadratic Programming (QP) controller takes the task-space velocities and computes the optimal joint velocities.
- Safety First: It strictly enforces joint limits and collision avoidance.
- GPU Integration: To keep training fast, they developed a custom GPU-parallelized solver, allowing thousands of robots to solve optimization problems simultaneously during RL training.
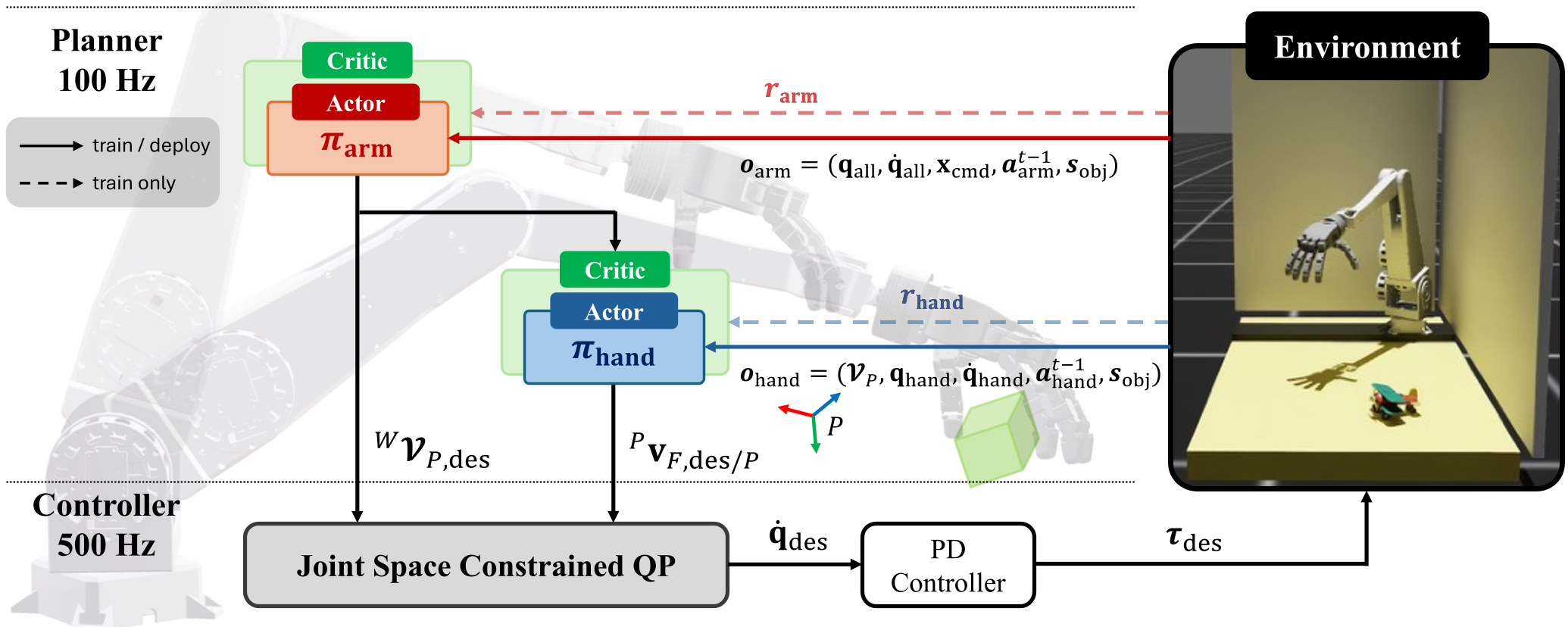 Figure 1: The hierarchical pipeline from high-level task planning to joint-level execution.
Figure 1: The hierarchical pipeline from high-level task planning to joint-level execution.
Experiments & Results: Robustness in Action
The architecture was tested on a 7-DoF arm and a 20-DoF Robotis hand.
Sim-to-Real Success
The policy was trained entirely in the IsaacLab simulator using the YCB object dataset. Using a Minimum Volume Bounding Box (MVBB) representation for objects allowed the policy to generalize to unseen shapes.
- Success Rate: 81.4% (Multi-Agent) vs. 13.2% (End-to-End Baseline).
- Zero-Shot Transfer: Successfully grasped 22/26 real-world items, including slippery and deformable objects.
Reactivity to Disturbances
One of the most impressive results was the system's ability to handle physical disturbances. In hardware tests, when the robot arm was pushed away mid-grasp, the RL policy (observing the new spatial relationship) immediately generated corrective velocities, and the QP controller translated them into safe joint motions to recover and complete the task.
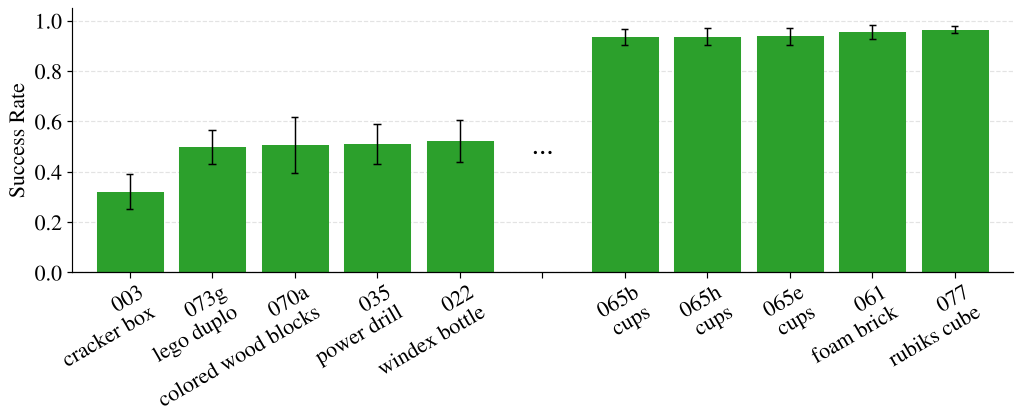 Figure 2: Performance breakdown across various object types. Geometrically uniform objects (right) saw the highest success rates.
Figure 2: Performance breakdown across various object types. Geometrically uniform objects (right) saw the highest success rates.
Deep Insight: Steerability & Safety
A standout feature of this research is Steerability. Because the QP layer is deterministic and modular, system operators can change the robot's behavior without retraining the AI:
- Speed Control: By scaling the joint velocity limits in the QP, you can slow down the robot for safety or speed it up for efficiency.
- Obstacle Avoidance: By superimposing "Artificial Potential Fields" (repulsive forces) onto the RL velocity output, the robot can dodge new, unseen obstacles zero-shot.
Conclusion & Future Work
This work proves that a "pure learning" approach isn't always best for robotics. By reintroducing model-based priors (QP) for the low-level execution, we gain safety, efficiency, and interpretability.
The authors plan to extend this to Continuous Contact scenarios, such as in-hand manipulation, where the fingers don't just grasp but actively reorient the object. This hybrid approach might be the key to moving dexterous robots out of controlled labs and into unstructured human environments.
Key Takeaway: Don't make RL learn the laws of physics or robot kinematics from scratch. Use RL for the "intuition" and optimization-based control for the "execution."