本文提出了一个混合分层控制框架,用于实现灵巧手的反应式抓取。该框架通过多智能体强化学习(MARL)在任务空间生成速度指令,并结合 GPU 加速的二次规划(QP)控制器在关节空间执行,在 5 指 20 自由度人形手上实现了 SOTA 级别的 Zero-shot 迁移性能。
TL;DR
针对 20 自由度(DoF)人形灵巧手抓取的难题,本文提出了一种混合分层控制框架。它将复杂的空间路径规划交给多智能体强化学习(MARL),而将关节限位、避障等“硬约束”交给高效的 GPU 并行 QP 求解器。该方法不仅在收敛速度上远超端到端 RL,更实现了强大的硬件安全性与Zero-shot迁移能力。
痛点深挖:为什么灵巧抓取这么难?
灵巧抓取(Dexterous Grasping)一直是机器人领域的“硬骨头”。相比简单的二指夹爪,多指人形手面临着极其复杂的接触动力学和高维状态空间。
- 学习负担过重:端到端 RL 试图让一个神经网络同时学会“该去哪”、“怎么动手指”以及“如何不弄坏电机”,这导致奖励函数设计极其痛苦且难以收敛。
- 安全性真空:神经网络本质上是概率性的,难以百分之百保证不超出关节极限或发生碰撞。
- 架构 rigidity:一旦完成训练,很难在不重新训练的情况下让机器人变得更“谨慎”或绕开新出现的障碍物。
方法论:让 RL 的归 RL,物理的归 QP
作者的核心 Insight 是:让物理规律去处理可以建模的部分,只让 RL 去学那些难以建模的直觉。
1. 任务空间与关节空间的解耦
框架分为两层:
- 高层 RL 规划器 (100 Hz):生成掌心的 6D 速度指令和各指尖的 3D 线速度。它只需要关注“如何接近物体”和“形成什么样的抓取形态”。
- 底层 QP 控制器 (500 Hz):接收高层速度指令,通过求解一个带约束的二次规划问题,将其转化为安全的关节速度。
2. 多智能体多路并行
为了进一步降低维度灾难,作者模仿人类神经系统,将策略拆分为:
- Arm Agent:负责全局运输(运输任务)。
- Hand Agent:负责精细操纵(抓取任务)。 两者共享奖励函数(如 Form Closure 形式闭合),通过协同进化提高效率。
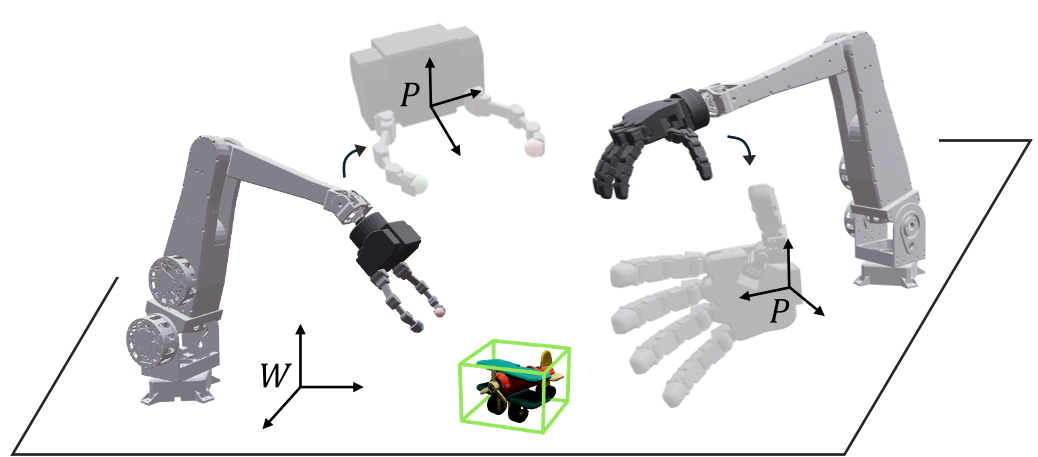 图 1:混合分层架构示意图。左侧为基于多智能体 PPO 的高层规划,右侧为 GPU 加速的 QP 底层控制。
图 1:混合分层架构示意图。左侧为基于多智能体 PPO 的高层规划,右侧为 GPU 加速的 QP 底层控制。
实验与结果:从仿真到现实的丝滑迁移
训练效率的跨越
对比实验表明,在 20 自由度的 5 指手任务中,传统的**端到端(End-to-End)**方法几乎无法收敛(成功率仅 13%),而本文的 Multi-Agent 混合架构 迅速达到了 81% 以上的成功率。
强大的 Steerability(可操纵性)
这是该框架最惊艳的地方:由于底层是物理控制器,用户可以在不重训模型的情况下,通过修改 QP 约束来实时调整机器人的动作风格。
- 动态避障:通过在任务空间叠加人工势场(APF),机器人能零样本避开突发障碍。
- 安全调优:通过缩放 QP 中的关节速度限位,可以实时控制机器人的快慢。
 表 1:不同架构在 5 指手和 2 指夹爪上的性能对比。可以看到 Multi-Agent 架构在位置和姿态误差上均表现最优。
表 1:不同架构在 5 指手和 2 指夹爪上的性能对比。可以看到 Multi-Agent 架构在位置和姿态误差上均表现最优。
硬件实测
在真实硬件(7-DoF 臂 + 20-DoF 手)上,系统对 26 种未见过的物体进行了测试。即使用户在抓取过程中猛推机械臂,由于 RL 策略是在任务空间(相对物体)定义的,系统能迅速产生修正速度指令,展现出极强的**反应式补偿(Reactive Recovery)**能力。
深度洞察与总结
本文的成功在于对“解耦”的深刻理解。它并没有迷信全能的神经网络,而是利用数学优化的严谨性为强化学习的灵活性筑起了安全围栏。
局限性: 目前系统仍依赖外部视觉系统(Point2pose)提供物体的 6D 位姿。对于极薄(如盘子)或极其光滑的物体,缺乏触觉反馈(Tactile Feedback)仍是导致失败的主因。
未来启示: 这种“学习+优化”的混合范式正在成为复杂机器人控制的主流。随着开源 GPU 并行 QP 求解器(如 CusADi)的成熟,我们有望在更复杂的全身动态操纵任务中看到这种架构的身影。