OmniBehavior 是一个创新的用户行为模拟基准测试框架,旨在评估大语言模型(LLMs)对真实世界复杂行为的模拟能力。该基准基于快手平台 200 位真实用户的跨场景(直播、视频、电商等)长周期(三个月)脱敏数据构建,涵盖了 22 种异构行为。
在数字化生存的今天,能否用 AI 创造出逼真的“数字孪生”?这不仅是社会科学研究的理想,也是构建智能推荐系统和交互式 AI 的核心。然而,最近由中科院和快手联合发布的 OmniBehavior 研究指出:即使是目前最强大的 LLMs,距离成为合格的“人类模拟器”仍有很长的路要走。
1. 为什么我们需要更真实的用户模拟?
传统的研究往往将用户行为割裂开来。例如,一个模型可能只研究你在观看视频时的点赞,或者你在购物平台上的点击。但真实的人类行为是全域联动的:你可能因为一周前看到的一个穿搭视频,在今天进入直播间并产生购买行为。
目前的评价基准(Benchmark)大多存在以下通病:
- 场景孤立:仅限于视频、或仅限于电商,缺乏跨场景关联。
- 动作单一:只关注点击/点赞,忽略了评论、搜索、退货、投诉等复杂反馈。
- 数据虚假:使用合成数据,缺失了真实人类性格中的复杂性、负面情绪和长尾特征。
为了打破这些限制,OmniBehavior 应运而生。

2. OmniBehavior:从百万真实轨迹中炼金
OmniBehavior 转为模拟真实世界而生。它直接采用来自快手平台的脱敏真实数据,具备三大核心特征:
- 长周期 (Long-horizon):涵盖了 200 名用户连续三个月的完整行为,单人步数最高超过 10 万。
- 跨场景 (Cross-scenario):打通了短视频、直播、广告、电商、搜索五个核心业务场景。
- 异构行为 (Heterogeneous):支持 22 种动作,包括点赞、转发、购买、咨询、快进甚至“差评/投诉”。
3. 核心洞察:人类决策比想象中更复杂
研究团队通过对数据的统计分析,得出了几个颠覆性的结论:
- “管窥效应” (Tunnel Vision):如果只看单一场景的数据,我们对用户的理解会减少 20%-30% 的兴趣维度。
- 长链因果:超过 80% 的转化(如购买)其因果链条跨越了多个场景,且 60% 以上的决策线索追溯到 3 天之前。
- 真实性不可替代:合成数据在统计特性上与真实轨迹存在巨大差异。
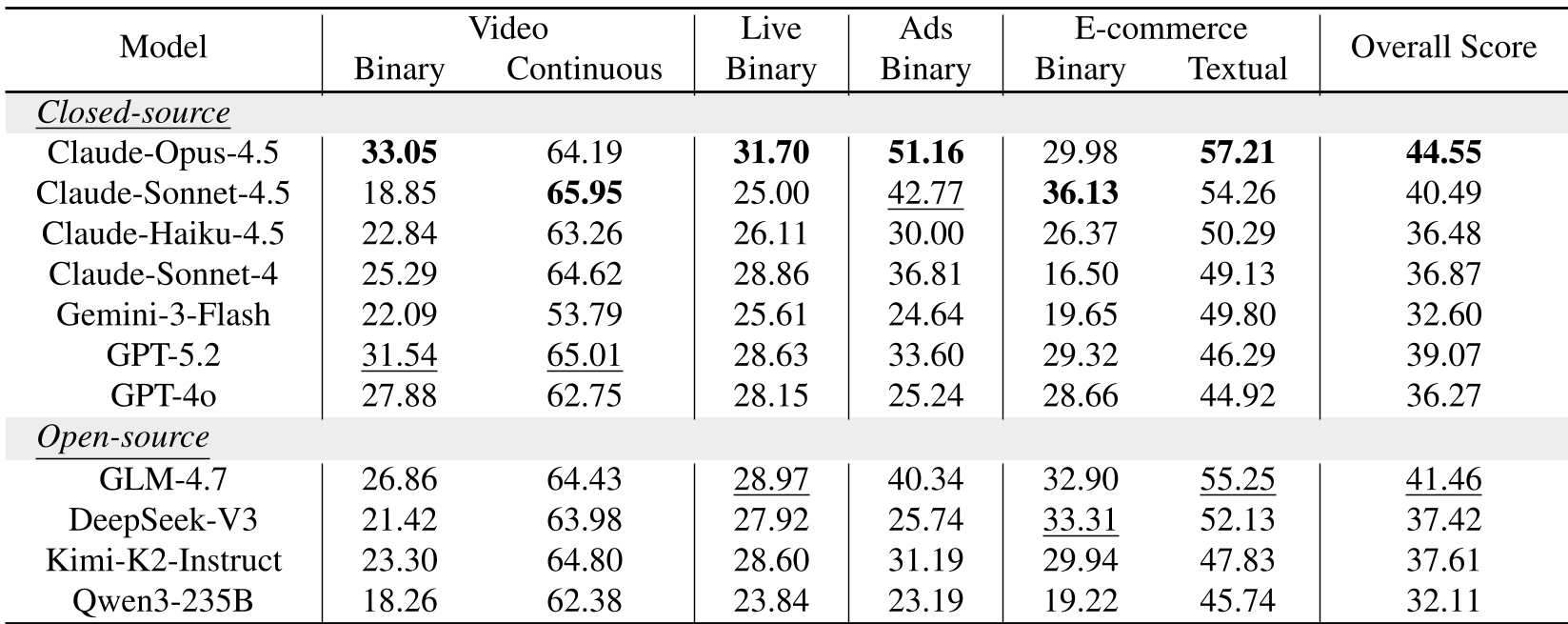
4. 测评结果:顶尖大模型集体的“滑铁卢”
研究者测试了包括 Claude-4.5、GPT-5.2、DeepSeek-V3 在内的国内外十余款顶尖模型。结果令人吃惊:
- 分数普遍偏低:在百分制的测试中,表现最好的 Claude-Opus-4.5 仅得 44.55 分。
- “长上下文”失灵:即使模型支持 128k 的窗口,单纯塞入更多历史记录,其预测准确率并没有像预想中那样线性上升,甚至在某些阶段出现下降。
5. 发现三个致命“结构性偏差”
这是该研究最深刻的部分。研究发现模型不是“算不准”,而是“算不对”——它们具有以下三种人类不具备的通病:
- 多动症 (Hyper-activity):LLMs 总是预测用户会进行更多的点赞和点击。它们倾向于认为用户是“积极参与者”,而忽略了真实用户大部分时间是在沉默或无视。
- 均质化 (Persona Homogenization):通过向量分析发现,不同 AI 模拟出的“用户”行为极度趋同。它们都在扮演一个“平均人”,丢失了真实人类那份独特且珍贵的个性长尾。
- 乌托邦偏见 (Utopian Bias):由于强化学习(RLHF)的对齐,模型变得过于有礼貌和正能量。在模拟电商投诉对话时,AI 用户往往表现得优雅得体,而真实用户可能是愤怒、尖锐且充满负面情绪的。
6. 结语:路长且阻
OmniBehavior 的出现为用户行为建模树立了新的标杆。它告诉我们:真正的人类行为模拟,不仅仅是算法预测,更是对人性“幽暗”与“复杂”面的还原。未来的研究方向应当如何打破模型的“正能量滤镜”,提升模型对长周期因果的推理能力,将是决定“数字人”能否真正替代现实测试的关键。
本文基于论文《Towards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces》整理撰写。