本文推出了 RealRestorer,这是一个基于大规模图像编辑模型微调的通用型真实世界图像修复框架。通过引入包含九种退化类型的超大规模数据集和两阶段混合训练策略,该模型在保持内容一致性的同时,在多种图像修复任务上达到了开源 SOTA。
TL;DR
在图像修复领域,合成数据与真实场景之间的“领域鸿沟”一直是难以逾越的障碍。RealRestorer 通过微调大规模图像编辑模型,结合精心设计的两阶段数据生成管线,成功实现了一个能处理去噪、去雾、去雨、低光增强等 9 种退化的全能模型。实验证明,RealRestorer 显著缩小了开源模型与闭源商业巨头(如 GPT-Image、Nano Banana Pro)之间的性能差距,成为目前最强的开源真实世界修复模型。
1. 痛点:合成数据是“温室里的花朵”
传统的 Image Restoration 任务通常遵循“合成样本 -> 网络训练 -> 测试集验证”的流程。然而,真实的镜头划痕、复杂的传感器摩尔纹、或是由于光线折射产生的 Flare(光晕),其物理特性远比 Gaussian Noise 或简单的线性掩码复杂。
现有方案的局限性在于:
- 分布偏差:合成退化模型由于过于理想化,导致模型在遇到复杂的真实场景时经常出现伪影或修复不彻底。
- 黑盒门槛:目前最强的修复效果往往由闭源的图像编辑大模型提供,研究社区难以针对其底层机制进行改进。
- 评估失真:传统的 PSNR/SSIM 指标过于关注像素级别的对齐,无法真实反映人眼对“清晰度”和“纹理还原”的主观感受。
2. 核心机理:从“生成”模型到“修复”模型
RealRestorer 的核心直觉在于:强大的图像编辑(Editing)能力本身就蕴含了对图像结构的深刻理解。
2.1 架构与两阶段微调
模型基于 Step1X-Edit (DiT + QwenVL) 架构。作者并没有直接从头训练,而是采用了巧妙的“知识迁移”策略:
- 迁移训练阶段 (Transfer Training):使用 1.5M synthetic 数据,让模型初步掌握从高层语义指令到特定退化修复的映射。
- 有监督微调阶段 (SFT):引入 80K 真实退化对。关键点在于采用了 Progressively-Mixed 策略,即在微调阶段不完全抛弃合成数据,而是维持一定比例混合,有效避免了模型在真实小样本上的过拟合。
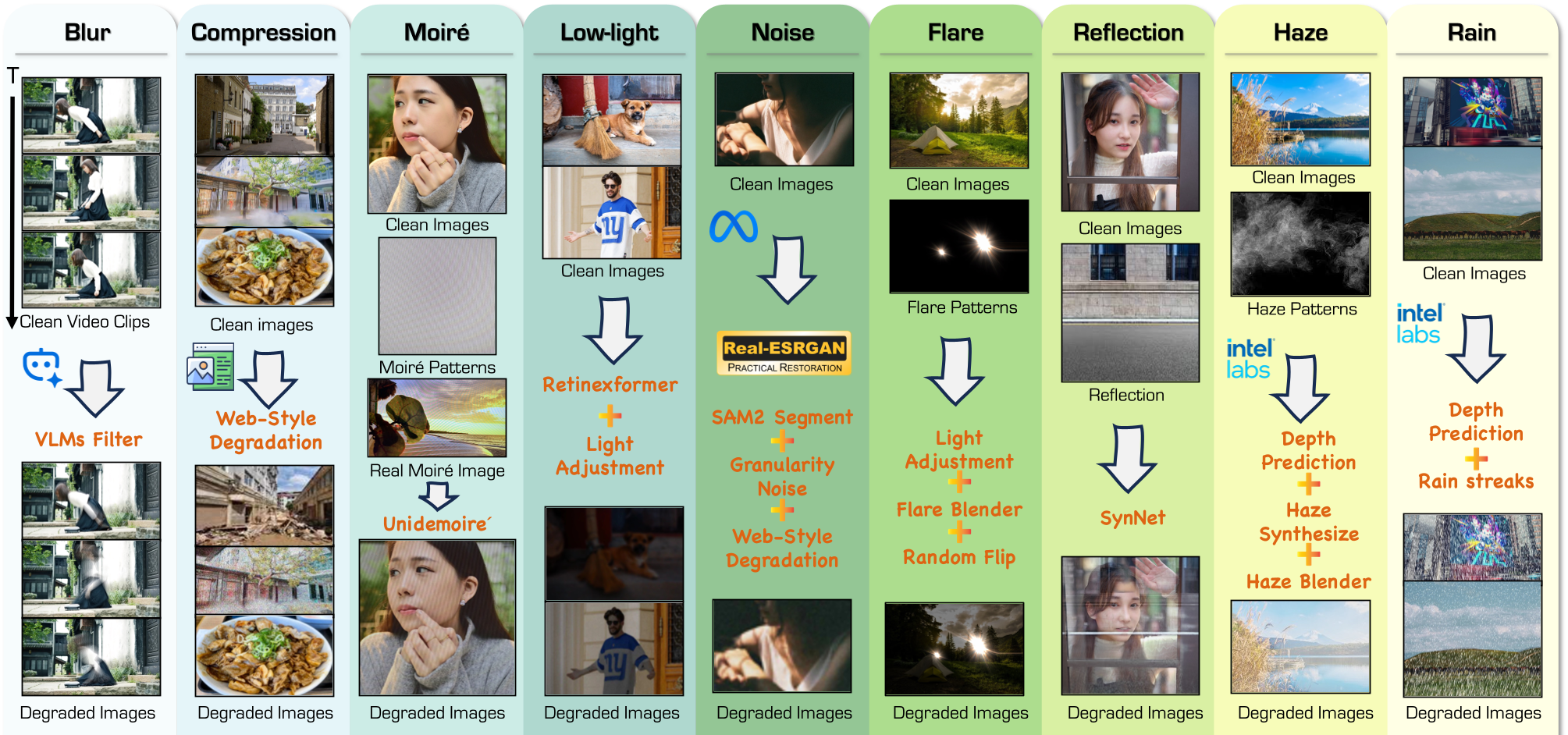 Figure 1: 数据生成管线,通过 SAM-2 和 MiDaS 提取语义/深度信息,生成更高质量的合成数据。
Figure 1: 数据生成管线,通过 SAM-2 和 MiDaS 提取语义/深度信息,生成更高质量的合成数据。
3. 实验战绩:开源界的领跑者
为了客观评价“无法对齐”的真实图像修复效果,作者提出了 RealIR-Bench,并设计了 Final Score (FS) 公式,兼顾了修复强度(RS)与内容一致性权重。
3.1 性能对比
在针对 9 种退化的全方位评测中,RealRestorer 在 去模糊 (Deblurring) 和 低光增强 (Low-light) 任务上表现尤为突出。
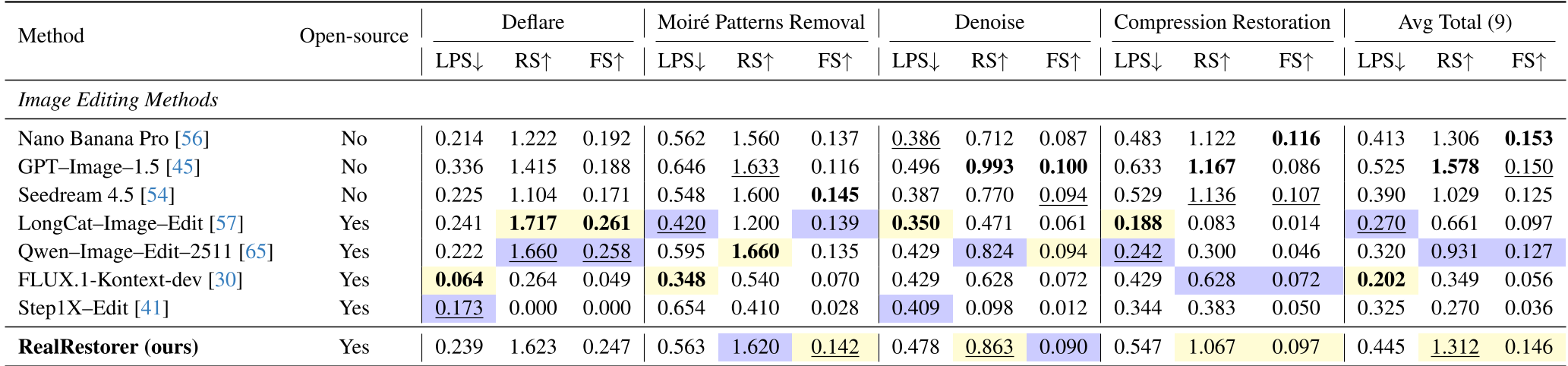 Table 1: 各模型在九大任务上的均分表现。可以看到 RealRestorer 紧追 Nano Banana Pro。
Table 1: 各模型在九大任务上的均分表现。可以看到 RealRestorer 紧追 Nano Banana Pro。
3.2 可视化对比:细腻的细节还原
与其他编辑模型相比,RealRestorer 的优势在于它能精准识别退化区域。例如在处理 Moiré pattern(摩尔纹)时,传统模型容易导致整体色彩失真,而 RealRestorer 能在去除条纹的同时锁定原始织物的纹理。
 Figure 2: 在不同退化类型下的修复对比,RealRestorer 的清晰度和色彩还原最为自然。
Figure 2: 在不同退化类型下的修复对比,RealRestorer 的清晰度和色彩还原最为自然。
4. 深度洞察:为什么它更强?
RealRestorer 的成功并非仅仅依靠更大的数据量,其 Ablation Study 揭示了两个关键洞察:
- 早期停止 (Early Stopping):在 SFT 阶段,模型在 2.5K step 时达到巅峰,随后由于真实数据规模限制会出现过拟合。这说明对于大尺寸 DiT 模型,寻找泛化平衡点比刷训练时长更重要。
- VLM 作为判卷人:文章利用 Qwen3-VL 进行自动评分,这在无参考图像(Non-reference)的评价体系中提供了一种比传统感知指标(如 NIQE)更符合人类逻辑的评估方案。
5. 总结与行业启示
RealRestorer 的开源不仅提供了一个强力的工具,更指明了未来图像修复的路径:不再追求单一任务的小模型优化,而是利用具有 Scaling Law 效应的生成式底座(Foundation Models)进行下游任务的对齐。
尽管在处理超极端退化(如关键像素完全丢失)时仍有挑战,但其 Zero-shot 泛化能力(如从未训练过的旧照片修复)展示了该框架作为底层视觉通用底座的巨大潜力。