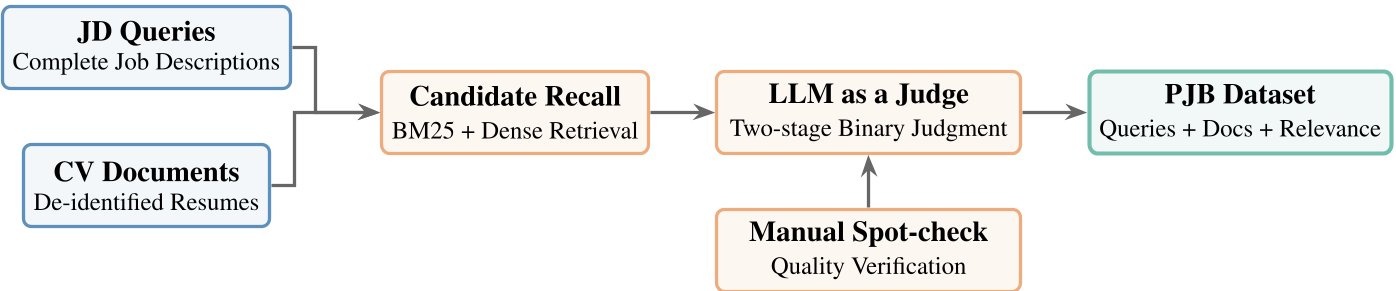
本文推出了 PJB (Person-Job Benchmark) v1.0,这是一个专门针对招聘场景的推理感知型检索评测基准。它包含近 300 个查询(职位描述)、20 万份简历及 2000 多个专家标注的胜任力判定标签,通过领域族(Domain-family)和推理类型(Reasoning-type)标签实现了从单一分数到多维诊断的评测演进。
TL;DR
在 AI 检索模型性能逐渐趋同的今天,我们不仅要问“谁的分数更高”,更要问“系统在什么时候会失效”。本文提出的 PJB (Person-Job Benchmark) 是首个面向招聘场景、具备诊断能力的推理感知型检索基准。它证明了:在招聘领域,领域适配的 Base Retriever > 通用重排序模块 > 盲目的查询理解。
1. 痛点:为什么人岗匹配比通用搜索难?
传统检索任务(如搜电影、搜百科)往往基于浅层语义匹配。但在垂直的招聘领域,系统面临的是一种“复合推理”挑战:
- 并行推理 (Parallel Reasoning):独立验证多个显式约束(地点、学历、薪资、关键词)。
- 串行推理 (Serial Reasoning):需要进行多跳语义抽象(例如:将“具备跨境电商经验”映射到隐式的“英语能力”和“平台运营技能”)。
现有的 MTEB 等榜单无法体现这些深层能力的缺失。
2. PJB 架构:从单一评分到“能力地图”
PJB v1.0 并不是另一个只看平均分的 Leaderboard,它通过两套标签体系对系统进行“全检”:
- 领域族标签 (Domain Taxonomy):将岗位划分为技术研发、产品运营、职能办公等 6 大族类,揭示不同领域的匹配逻辑差异。
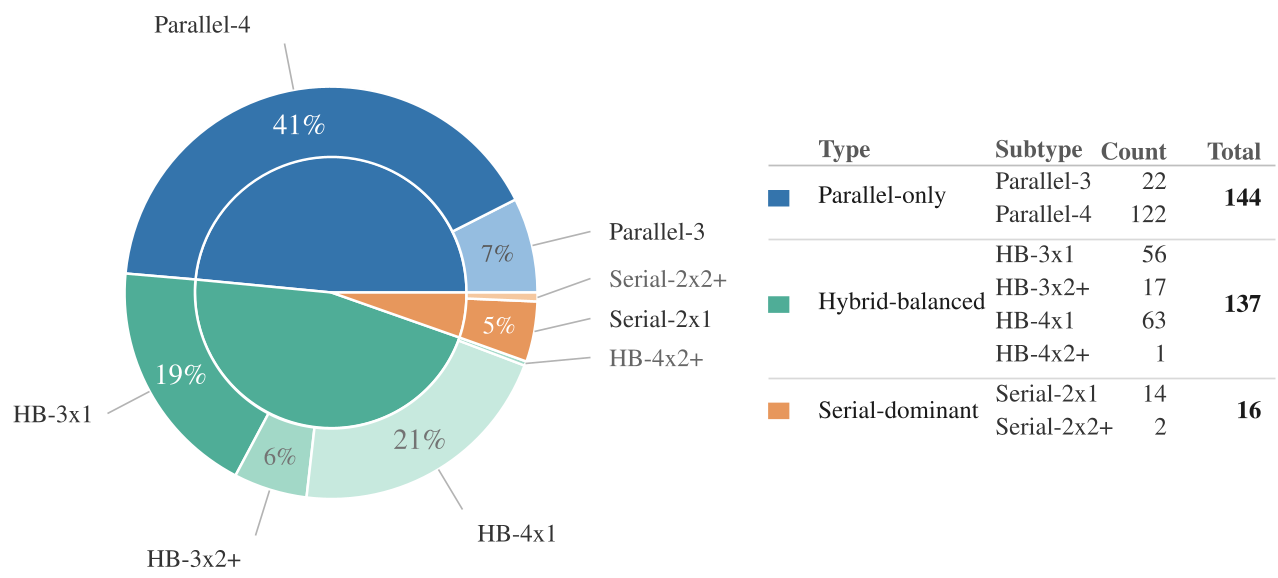
- 推理类型标签 (Reasoning Taxonomy):利用“并行宽度”和“串行深度”两个维度,将查询分为 Parallel-only(侧重硬性过滤)、Hybrid-balanced(混合型)和 Serial-dominant(侧重深度推断)三类。
3. 核心发现:模块堆叠并不总是有效
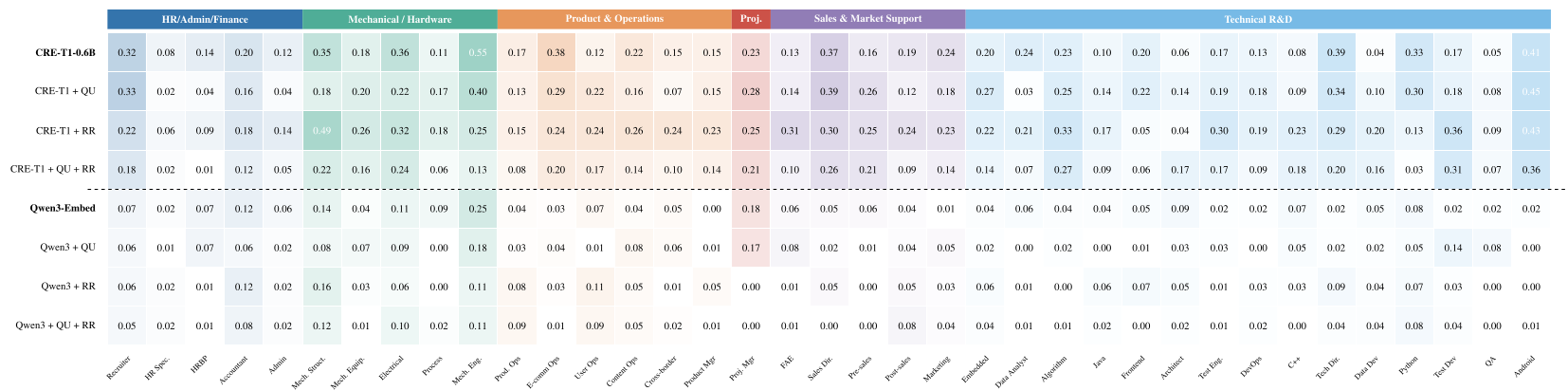
作者通过 2x4 的消融矩阵(使用自研模型 CRE-T1 和通用模型 Qwen3)得出了令人惊讶的结论:
3.1 领域适配是“入场券”
专用模型 CRE-T1 的 nDCG@10 基准分为 0.2070,而同规模的通用模型 Qwen3 仅为 0.0592。这意味着如果没有行业数据的微调,模型在招聘搜索中几乎处于“致盲”状态。
3.2 模块收益是非单调的
实验发现,Rerank(重排序)是唯一能稳定带来正向收益(+8.9%)的模块,且收益主要集中在需要深度推理的 Serial-dominant 任务上。
有趣的是,QU(查询理解)模块在两个模型上均表现为负向收益。分析认为,当前的查询重写策略可能会破坏原始 Job Description (JD) 中严谨的结构化约束信息。
4. 实验结果与诊断
通过 PJB 的诊断切片,我们能清晰看到系统的脆弱点:
- 异质性表现:性能在不同行业间的波动远大于模型升级带来的增益。
- 失效模式:当 Base Retriever 性能太差时,后置的 Rerank 和 QU 模块不仅无法弥补缺陷,反而会引入更多噪声,导致 Bad Case 比例从 72% 飙升至 81%。
5. 总结与行业启示
PJB 的出现标志着招聘检索正从“黑盒评分”转向“透明诊断”。对于从业者的启示是:
- Base 决定上限:优先进行垂直领域的领域适配训练,而非迷信通用 Embedding。
- 理性对待 QU:在处理长文档、多约束的 JD 时,简单的 NLP 改写可能会丢失关键信息。
- 分层优化:针对 Parallel-only(硬性约束多)和 Serial-dominant(软技能推理多)的查询,应采用不同的策略或 Reranker 权重。
PJB v1.0 不仅填补了 HR 领域学术评测的空白,更为构建工业级、可解释的招聘检索系统指明了方向。