The paper introduces Reason and Restore (R&R), a universal image restoration framework that integrates a Chain-of-Thought (CoT) reasoning stage before pixel-level reconstruction. By fine-tuning Qwen3-VL, the model achieves state-of-the-art (SOTA) performance on UIR benchmarks, reaching 19.564 dB PSNR on the OTS dataset.
TL;DR
The "Reason and Restore" (R&R) framework transforms universal image restoration into a two-stage cognitive process. Instead of blindly attempting to "clean" an image, R&R first performs a structured diagnosis of the degradation (fog intensity, blur kernels, noise levels) and then uses these insights as a "map" to guide a high-fidelity restorer. By integrating Chain-of-Thought (CoT) reasoning and Reinforcement Learning (RL), it sets a new SOTA for handling messy, real-world mixtures of rain, fog, and noise.
Problem & Motivation: The "Look-and-Restore" Deadlock
Most existing restoration models follow a "Look-and-Restore" paradigm. They see pixels and try to output clean pixels. This works for single, synthetic degradations like Gaussian noise. However, real-world images are a "cocktail" of degradations: a car driving in the rain (rain streaks) on a misty morning (fog) with a vibrating camera (motion blur).
Current "Agentic" systems like RestoreAgent attempt to solve this by using an LLM to call specific tools. But this has a ceiling: the restorer can only be as good as the pre-trained tool it selects. If the LLM doesn't "talk" to the pixel-level model throughout the process, subtle scene context (like the fact that a blurry region is actually a building edge) is lost.
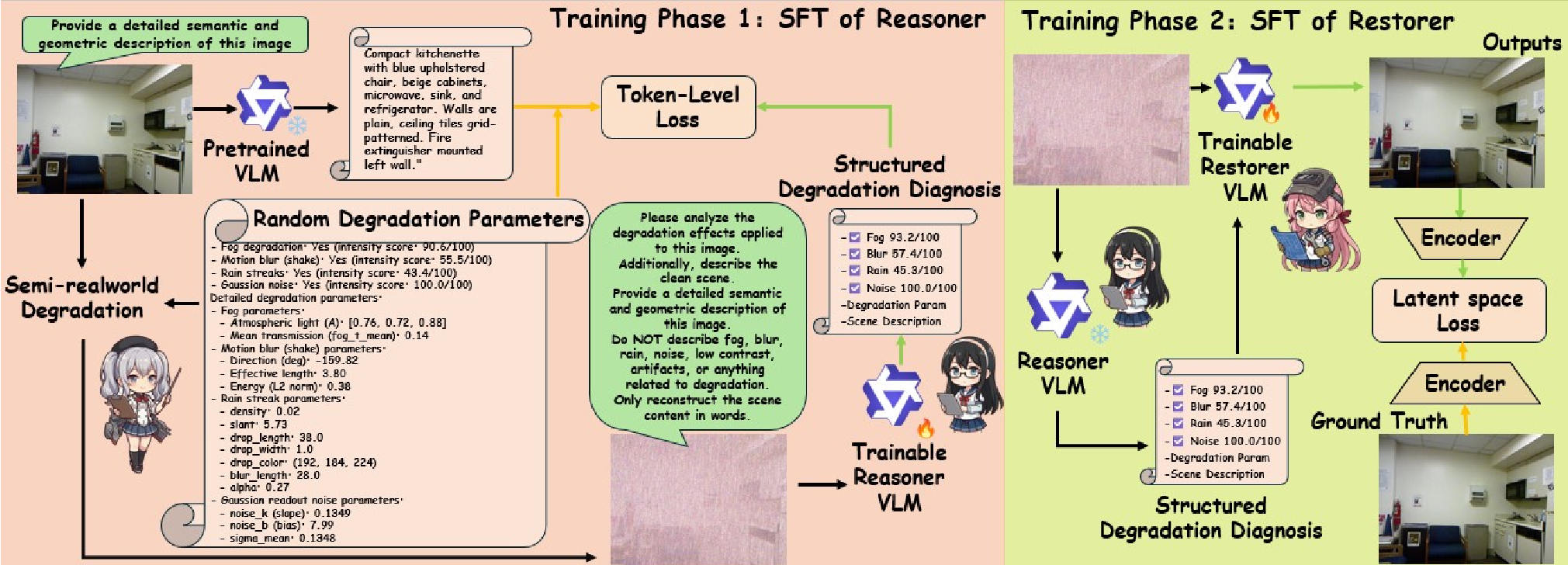
Methodology: Thinking Before Acting
R&R introduces a two-stage architecture that mimics human expert analysis.
1. The Reason Phase (The Diagnostic Brain)
Using a fine-tuned Qwen3-VL, the model generates a structured CoT output. It doesn't just say "it's foggy"; it provides:
- Presence Flags: Binary detection of 4 degradation types.
- Severity Scores: Continuous 1-100 scales for precise intensity mapping.
- Physical Parameters: Estimates of atmospheric light, transmission, and noise statistics.
- Semantic Descriptors: Textual descriptions of the underlying scene (e.g., "urban street with sharp building edges") without mentioning the degradation.
2. The Restore Phase (The Skilled Artist)
The restorer, based on Qwen-Image-Edit, receives both the degraded image and the Diagnostic Prior. This allows the model to prioritize which degradation to tackle first and use semantic priors to "hallucinate" missing textures realistically.
3. RL Alignment with GRPO
To ensure the restorer actually follows the diagnostic plan, the authors use Group Relative Policy Optimization (GRPO). The "Reasoner" acts as a judge, awarding rewards based on how much the "Severity Score" was reduced in the restored image. This closed-loop system forces the model to align its pixel generation with its initial reasoning.
Experiments: Superiority in the Wild
The authors tested R&R against heavyweights like Stable Diffusion 3 and Img2Img-Turbo.
- Quantitative Performance: R&R achieved 19.564 dB PSNR on the OTS (Outdoor) benchmark, significantly higher than SD3's 18.859 dB.
- Qualitative Fidelity: In real-world tests featuring extreme smoke and noise, R&R maintained structural integrity where other models suffered from "structure drift" or excessive smoothing (loss of fine branches/edges).

Critical Analysis & Conclusion
Takeaway
The core value of R&R lies in the explicit coupling of semantic reasoning and pixel reconstruction. By forcing the model to "explain" the degradation before fixing it, the framework gains an inductive bias that is much more robust than standard black-box CNNs or Transformers.
Limitations & Future Work
While the results are impressive, the framework relies on a VLM backbone (Qwen3-VL), which is computationally more expensive than lightweight UNet-based restorers. Future research could explore knowledge distillation, transferring this "reasoning ability" into smaller, edge-deployable models for real-time applications like autonomous driving.
R&R proves that for AI to truly "see" through the fog, it must first learn to think about what it is looking at.