本文提出了 Reason and Restore (R&R) 框架,一种将结构化思维链(Chain-of-Thought, CoT)推理引入通用图像修复(UIR)的新方法。该框架通过微调 Qwen3-VL 实现显式降质诊断,并结合强化学习(RL)优化,在 OTS 和 RESIDE 基準测试中达到了 SOTA 性能。
TL;DR
传统的图像修复(Image Restoration)往往是“直觉式”的:给一张破损图片,模型直接生成清晰图片。而本文提出的 Reason and Restore (R&R) 框架模仿人类,引入了思维链(Chain-of-Thought):先“诊断”图片里有什么(雾气多浓?模糊角度是多少?场景里是街道还是森林?),再根据诊断书进行精准“手术”。这一转变让修复效果在处理混合降质时达到了 SOTA 水平。
1. 痛点:为什么“直接修复”在真实世界会失效?
在实验室环境下,我们习惯于处理单一降质(如只去噪或只去雾)。但在真实的自动驾驶或户外监控中,降质往往是组合拳:
- 下雨天通常伴随着雾气(雨雾耦合)。
- 夜晚行车会出现运动模糊和高感光度噪声。
现有的方法(如 Prompt-based IR 或传统的 CNN 方案)大多缺乏对这些混合因素的本质理解。它们要么需要用户手动指定降质类型,要么在全自动处理时因为分不清“什么是降质、什么是物体纹理”而导致画面崩坏。
2. 核心直觉:先思考,再行动 (Reason-before-Restore)
作者认为,修复模型需要一个显式的诊断书。R&R 框架将修复过程拆解为两个阶段:
第一阶段:结构化诊断 (Reason Phase)
通过微调 Qwen3-VL,模型不再是简单地写一段话描述图片,而是输出一份四维度的“体检报告”:
- 成分识别:是否有雾、模糊、雨滴、噪声?
- 严重程度评分:0-100 分量化降质强度。
- 物理参数预测:大气光值、透射率、模糊核参数(对应物理模型)。
- 语义描述:还原被降质遮挡的物体(如:这是一条有建筑的城市街道)。
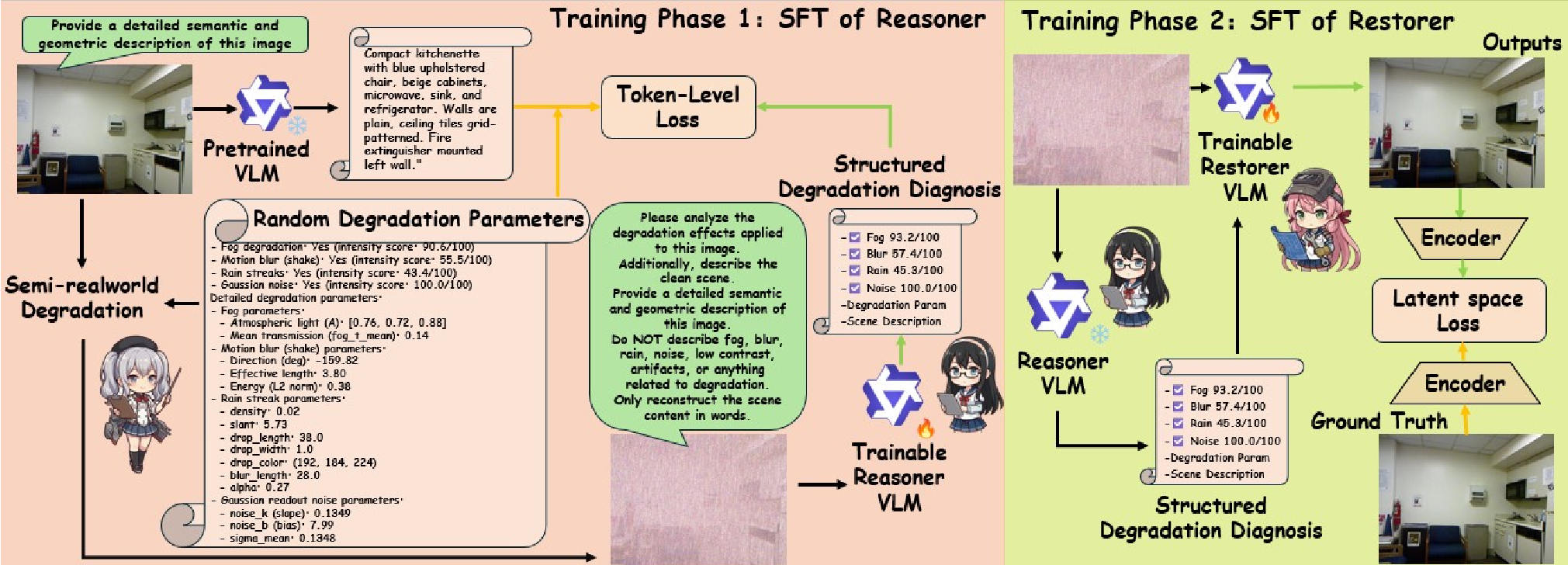 图 1:R&R 框架流程。先通过思考阶段生成诊断先验,再引导修复阶段。
图 1:R&R 框架流程。先通过思考阶段生成诊断先验,再引导修复阶段。
第二阶段:引导式修复 (Restore Phase)
修复模型(基于 Qwen-Image-Edit)接收原始图片和上述“诊断书”。有了这些细粒度的先验,模型就能在“手术”中做到有的放矢:在雾浓的地方加强去雾,在噪声大的地方保留结构平滑细节。
3. 技术突破:用强化学习 (RL) 锚定诊断结果
如何保证修复模型真的听从了诊断建议?作者引入了 GRPO(组相对策略优化)。
其核心逻辑非常巧妙:
- 奖励(Reward)设计:如果修复后的图片再次交给诊断模型,诊断出的“降质严重程度”大幅下降,则给予模型正向奖励。
- 闭环学习:这使得模型不仅要在像素级逼近 Ground-Truth(通过 MSE 损失),还要在逻辑级符合诊断书的预期(通过 RL 奖励)。
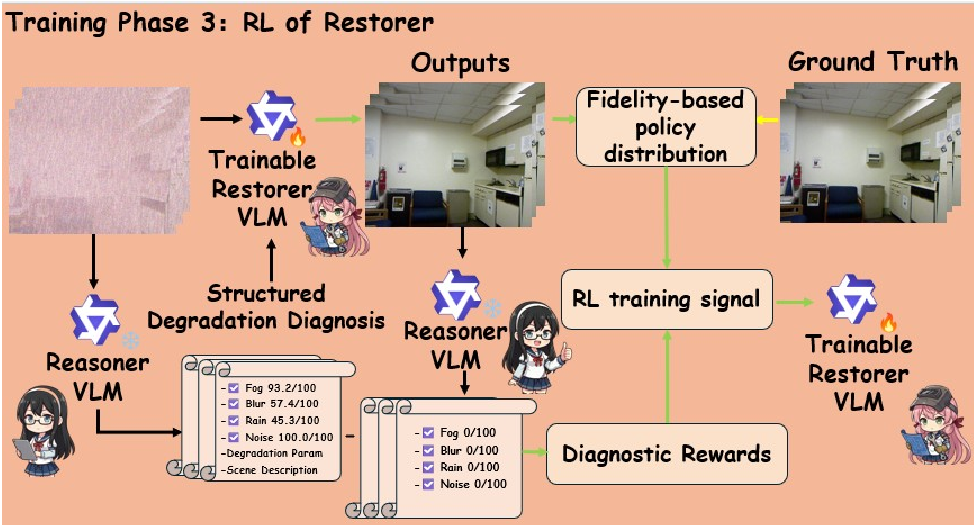 图 2:基于严重程度降低(Severity Reduction)的强化学习优化。
图 2:基于严重程度降低(Severity Reduction)的强化学习优化。
4. 实验战绩:多场景完美通关
实验在合成数据集(OTS, RESIDE)和 700 多张真实的户外图像上进行。
| 方法 | OTS (PSNR) | RESIDE (PSNR) | | :--- | :--- | :--- | | 传统三阶段 (3D) | 13.07 | 13.93 | | Stable Diffusion 3 | 18.85 | 15.49 | | R&R (Ours) | 19.56 | 17.00 |
从指标上看,R&R 在各项数据上保持领先。更惊艳的是在真实场景的可视化表现:即使是在极端雾天和复杂噪声干扰下,R&R 修复后的图像依然能保持物体的边缘轮廓和自然色彩,没有出现扩散模型常见的“幻觉”现象(即生成一些原图中不存在的物体)。
 图 3:真实世界测试集对比,R&R 在结构稳定性上表现优异。
图 3:真实世界测试集对比,R&R 在结构稳定性上表现优异。
5. 深度洞察与总结
R&R 框架的成功,实际上标志着通用底层视觉(Low-level Vision)正在告别单纯的黑盒拟合。
- 可解释性:当修复失败时,我们可以检查“诊断书”,看是模型分错了降质类型还是低估了严峻性。
- 耦合架构:不同于以往将 VLM 仅作为工具调度的“外挂式”方案,R&R 实现了语义推理与像素生成的高效内生耦合。
尽管目前该框架可能在推理延迟上(由于引入了 VLM 思维链)比传统轻量级网络稍高,但对于安全敏感型任务(如自动驾驶)而言,这种“三思而后行”带来的鲁棒性提升无疑是巨大的。