This paper introduces an information-theoretic framework to explain LLM "Aha moments" by decomposing reasoning into two axes: procedural information and epistemic verbalization. It demonstrates that as procedural reasoning hits local traps, the externalization of uncertainty via "thinking tokens" (e.g., "Wait") is the critical mechanism for acquiring the information sufficiency needed to self-correct.
TL;DR
Why do models like DeepSeek-R1 and O1 suddenly say "Wait..." and fix their own mistakes? This paper argues it isn't magic or a specific "thinking token" at work. Instead, it’s Epistemic Verbalization: the act of turning hidden internal doubt into visible text. By externalizing uncertainty, LLMs allow their next-token prediction to sample a "correction" path that was previously invisible to their procedural logic.
The Core Crisis: Procedural Stagnation
Most current theories view Chain-of-Thought (CoT) as a procedural execution. You have a task, you break it into step , then step . The problem? If step is wrong but "sounds" logical, the model enters Procedural Divergence.
 Figure 1: Common failure modes: Recursive expansion, Problem injection, and Degenerate loops.
Figure 1: Common failure modes: Recursive expansion, Problem injection, and Degenerate loops.
As shown in Figure 1, once a model diverges, it gets stuck in a loop. Purely procedural information gain vanishes. The model is confident in its local steps but globally lost.
The Solution: Strategic Information Allocation
The authors propose that reasoning is actually a balance between two types of information:
- Procedural Information: The "How-to" steps (math, logic, facts).
- Epistemic Verbalization: The externalization of internal uncertainty.
The key insight is that an LLM's internal state may know it is confused, but that confusion is informationally inert until it is written down. Once the model writes "Wait, let me check," that token becomes part of the prefix, fundamentally changing the probability distribution for the next tokens and enabling a "control action" (self-correction).
Mathematical Intuition: Information Sufficiency
The paper defines reasoning as a process aiming for Information Sufficiency (). While procedural steps eventually hit a ceiling (Assumption 3.3), the authors prove in Proposition 3.6 that sporadic epistemic updates (verbalizing doubt) can overcome stagnation and ensure continued information acquisition.
Evidence: It's Not the "Wait" Token, It's the Doubt
Is it just about the word "Wait"? The authors tested this by performing a "Mutual Information (MI) Peak" analysis. They found that MI peaks (moments where the model actually "gets" the answer) don't necessarily happen at the token "Wait," but during the evaluative phrases that follow.
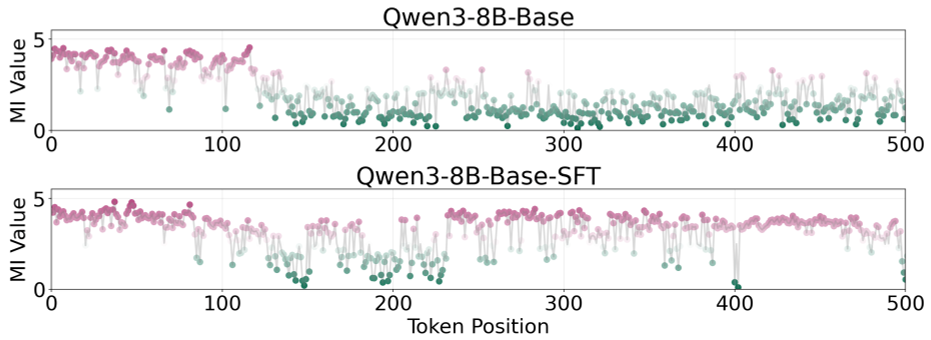 Figure 2: Information gain (MI) is sustained in SFT models that use epistemic verbalization to self-correct.
Figure 2: Information gain (MI) is sustained in SFT models that use epistemic verbalization to self-correct.
The Distillation Trap
A shocking result from the paper is the LIMO (Less Is More) Distillation experiment.
- If you train a model on "perfect" reasoning traces where all the "Wait" and "Hmm" are removed (Hindsight Distillation), the model’s performance collapses.
- Without the ability to "talk through" its uncertainty, the model loses its mechanism for control.
Critical Analysis: The "Warm-up" Effect
The paper explains why small models often fail to learn from large "reasoning" models. If a base model's internal support doesn't already "understand" uncertainty (low log-probability for epistemic tokens), no amount of RL or distillation will make it an effective reasoner. It must be "warmed up" to recognize its own internal doubt.
Conclusion: Stop Truncating the "Thoughts"
In the race for efficiency, researchers often try to shorten CoT length. This paper warns that indiscriminate truncation is dangerous. If you cut the "epistemic verbalizations," you are cutting the steering wheel off the car.
Future Outlook: We need models that are not just accurate, but "epistemically honest"—models that know when they are guessing and have the linguistic tools to navigate back to the truth.