The paper introduces Principia, a comprehensive suite including a new benchmark (PrincipiaBench) and a 248K synthetic dataset (Principia Collection) specifically designed to evaluate and improve LLM reasoning over complex mathematical objects (matrices, piecewise functions, etc.). It achieves state-of-the-art results by employing on-policy reward modeling (RLLM) and a novel test-time aggregation framework (ParaGator).
TL;DR
The AI community has a "multiple-choice" problem. Most benchmarks (like GPQA) allow models to cheat by reverse-engineering answers from given options. Principia changes the game by forcing LLMs to derive complex mathematical objects—matrices, sets, and piecewise functions—from scratch. By combining a massive new synthetic dataset with RLLM (Language Models as on-policy Reward Models) and ParaGator (an end-to-end aggregation trainer), the authors demonstrate that mastering hard symbolic derivation significantly boosts general reasoning across all formats.
The "Options" Trap: Why Current Benchmarks Overestimate Intelligence
Current frontier models like o3 and Qwen3-235B show a performance drop of 10–20% when multiple-choice options are removed. The "backward chaining" effect is real: models use provided answers as anchors rather than actually "reasoning" through the physical or mathematical phenomenon.
Furthermore, standard rule-based verifiers (e.g., Python's Sympy) are notoriously brittle. They fail to recognize that and are the same object simply due to LaTeX formatting or constant placement. This creates a ceiling for Reinforcement Learning (RL) progress.
Methodology: The Principia Solution
1. The Principia Collection
To solve the data scarcity for graduate-level STEM, the authors used a multi-step pipeline:
- Topic Mining: Extracting entities from MSC 2020 and Physics Subject Headings.
- Capability Sketching: Defining specific expert-level techniques (e.g., "Applying Chebotarev’s density theorem").
- Iterative Refinement: Turning simple knowledge-probing questions into deep, reasoning-intensive problems.
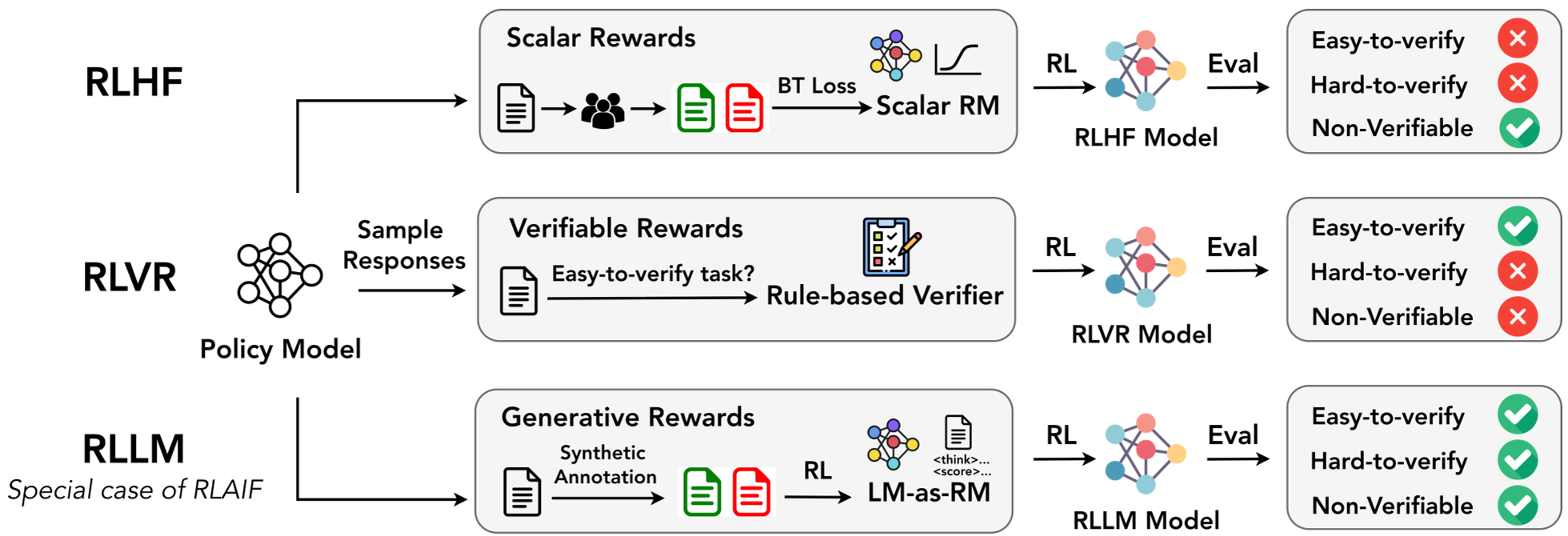
2. RLLM: The Thinking Reward Model
Traditional RLHF uses "dumb" scalar reward models that just output a number. RLLM utilizes a "thinking" LLM as the reward model.
- On-Policy Training: The reward model (RM) is trained specifically on the policy model's own mistakes.
- Generative Rewards: The RM generates a thinking trace before assigning a score, making it much harder to "hack" the reward signal.
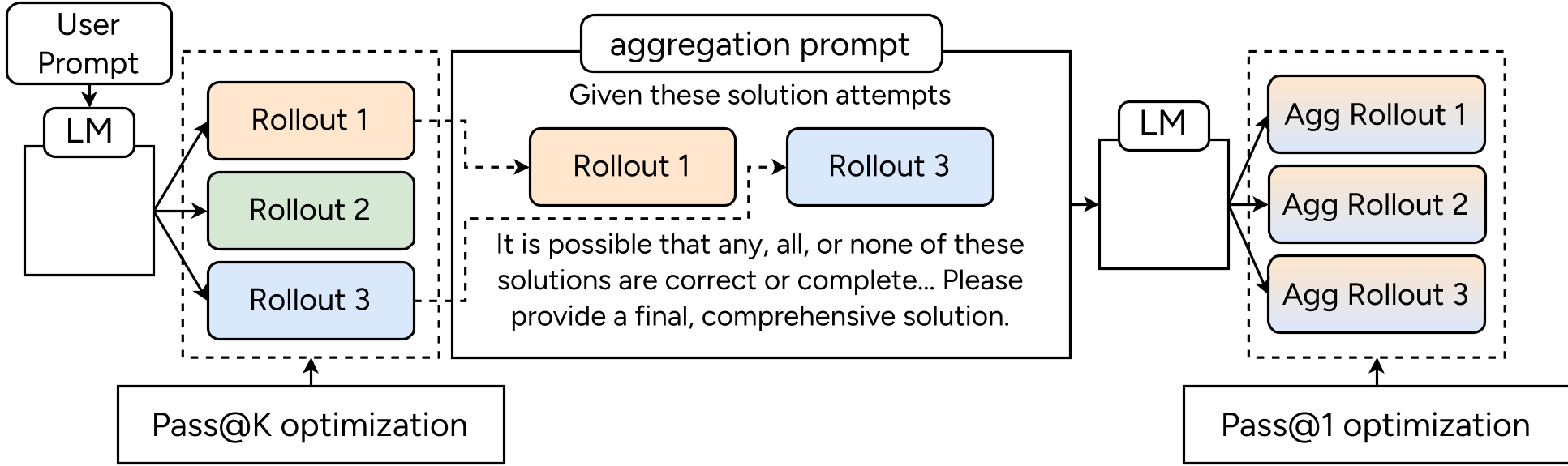
3. ParaGator: Learning to Aggregate
Most "parallel thinking" models generate multiple paths and use majority voting. ParaGator actually trains the model to be a better aggregator.
- The Synergy: The generator is optimized for pass@k (encouraging a diverse portfolio of solution attempts), while the aggregator is optimized for pass@1 (the ability to pick/synthesize the truth from the noise).
Experimental Evidence: Success Beyond Symbols
The most striking result is the Cross-Format Generalization. By training on complex symbolic objects (the hardest format), models didn't just get better at math—they got better at everything.
- Principia-4B-Zero outperformed competitive baselines like Polaris-4B and Qwen3-4B-Instruct.
- AIME Performance: Even though the training was purely symbolic, AIME scores (numerical) jumped by up to 17.5%, proving that deep derivation is a "super-set" skill that improves basic arithmetic.

Deep Insights: The Generator-Verifier Gap
A critical takeaway from the paper is the Capability Gap. An LLM cannot effectively "self-improve" if the Reward Model is the same size as the Policy Model. The authors found that a 32B RM provided a significant boost to a 1.7B Policy, whereas a 1.7B RM training a 1.7B Policy led to stagnation. Reward quality requires a "smarter" judge that can generate correct thinking traces to identify subtle logical fallacies.
Conclusion and Future Outlook
Principia demonstrates that if we want LLMs to function as autonomous scientists, we must move away from "answer-matching" and toward "derivation-verification." The release of PrincipiaBench and the 248K Principia Collection provides a new north star for reasoning models. The future of AI in STEM depends on the model's ability to manipulate the underlying language of the universe—mathematics—in its most complex, structured forms.
Blog written by Senior Academic Tech Editor. Evaluation source: Principia: Reasoning over mathematical objects.