This paper introduces SIDReasoner, a two-stage generative recommendation framework that enables Large Language Models (LLMs) to perform explicit reasoning over Semantic IDs (SIDs). By leveraging multi-task alignment and outcome-driven reinforcement learning (GRPO), it achieves a new SOTA in generative recommendation on datasets like Amazon Games and Office Products.
TL;DR
Generative recommendation is shifting from "predicting the next ID" to "reasoning why the next item fits." SIDReasoner bridges the gap between discrete item identifiers (Semantic IDs) and LLM reasoning capabilities. By aligning SIDs with natural language through synthetic corpora and refining the decision process via Outcome-driven Reinforcement Learning (GRPO), it enables LLMs to "think" in natural language before recommending in SIDs, achieving superior accuracy and interpretability.
1. The Core Paradox: Efficiency vs. Intelligence
In the world of Generative Recommendation, we face a trade-off:
- Text-based Models: Describe items in words. They are smart and use LLM knowledge but are painfully slow for large-scale retrieval.
- ID-based Models: Use Semantic IDs (SIDs). They are efficient but "dumb," as the LLM sees SID tokens as random noise without semantic grounding.
The Insight: If we can teach an LLM that token <a_1><b_25> actually represents a "Nintendo Strategy RPG," we can unlock the LLM's latent reasoning to explain why a user who likes Fire Emblem would want a specific Amiibo.
2. Methodology: From Alignment to Reinforcement
SIDReasoner operates in two critical stages: Enriched Alignment and Reinforced Optimization.
2.1 Enriched SID-Language Alignment
To give meaning to SID tokens, the authors use a Teacher Model (GPT-4o) to synthesize an "interleaved" corpus. Instead of just "User bought A, then B," the training data looks like a professional narrative: "The user enjoyed [SID_A], reflecting a preference for strategy... thus they might like [SID_B]."
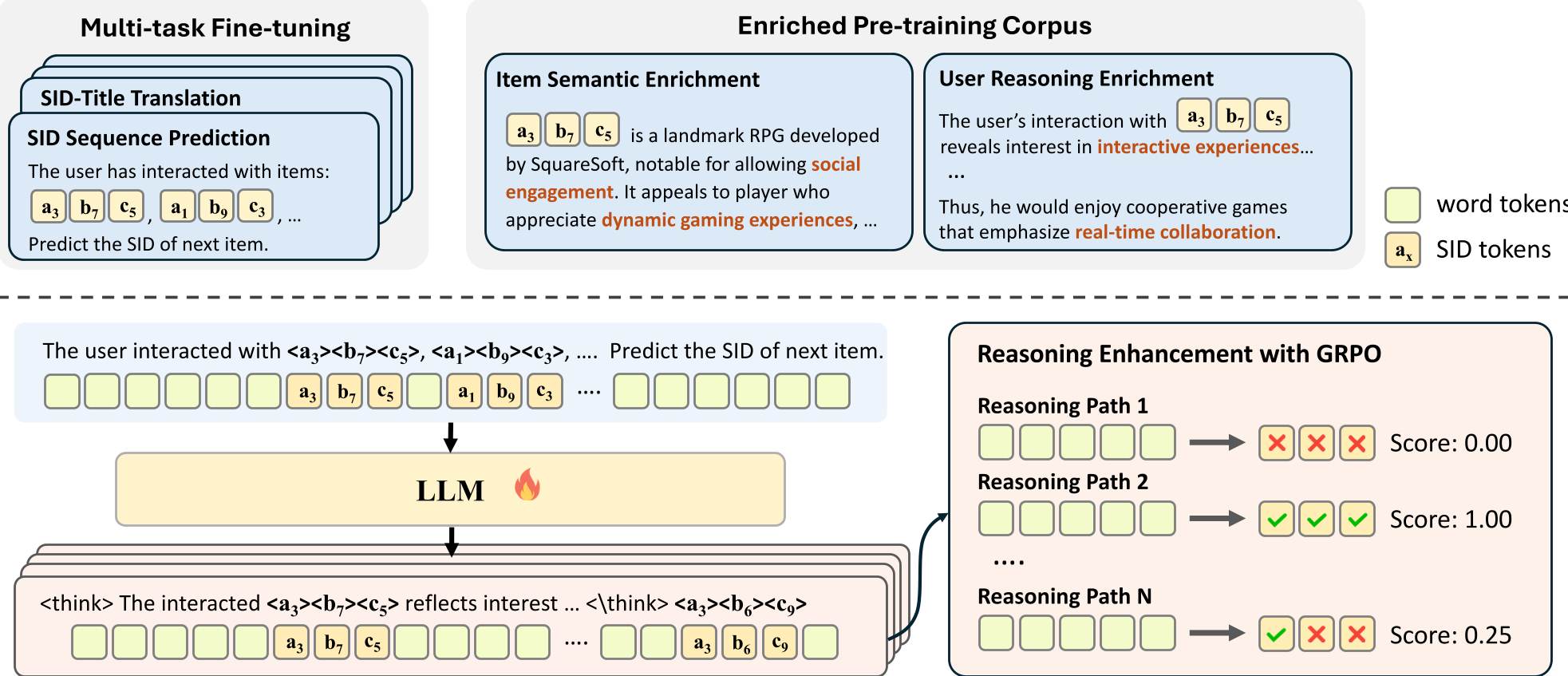 Figure 1: The two-stage architecture of SIDReasoner: (1) Alignment via multi-task training and (2) Reasoning enhancement via RL.
Figure 1: The two-stage architecture of SIDReasoner: (1) Alignment via multi-task training and (2) Reasoning enhancement via RL.
2.2 Outcome-Driven RL (GRPO)
How do you evaluate if a "reasoning trace" is good? You don't. Instead, you look at the outcome. Using Group Relative Policy Optimization (GRPO), the model generates multiple reasoning paths + SID predictions. If Path A leads to the correct item and Path B doesn't, Path A's reasoning style is reinforced.
3. Experimental Breakdown: Does Reasoning Actually Help?
The authors evaluated SIDReasoner on Amazon Games, Office, and Industrial datasets.
3.1 Performance Gains
As shown in the table below, SIDReasoner dominates both traditional discriminative models (SASRec) and modern generative ones (TIGER).
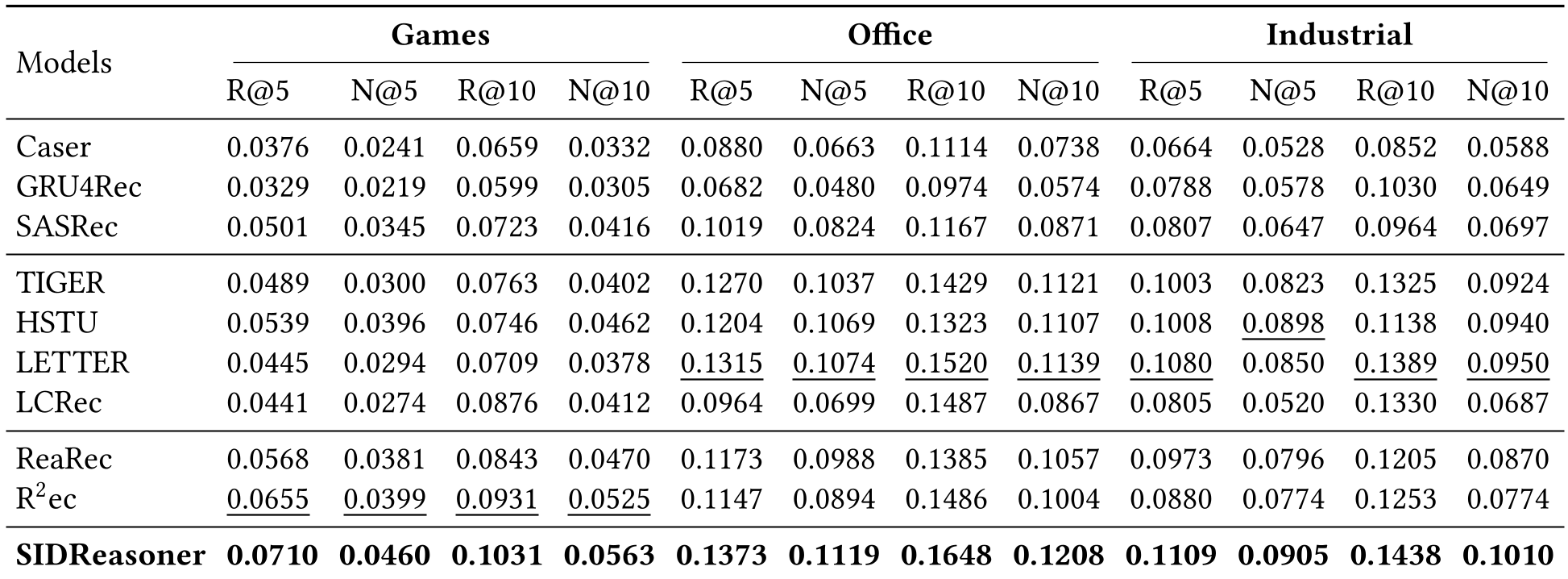 Table 1: Competitive results across three real-world datasets.
Table 1: Competitive results across three real-world datasets.
Key Discovery: Reasoning helps most where world knowledge matters. In "Games," where themes and genres are rich, the boost is massive. In "Industrial" (nuts, bolts, valves), the benefit is smaller because there's less "logic" for the LLM to latch onto.
3.2 The "Compression" of Reasoning
An interesting finding during RL training is that reasoning length actually decreases while accuracy increases. The model learns to stop "yapping" and focus on the decision-critical intent.
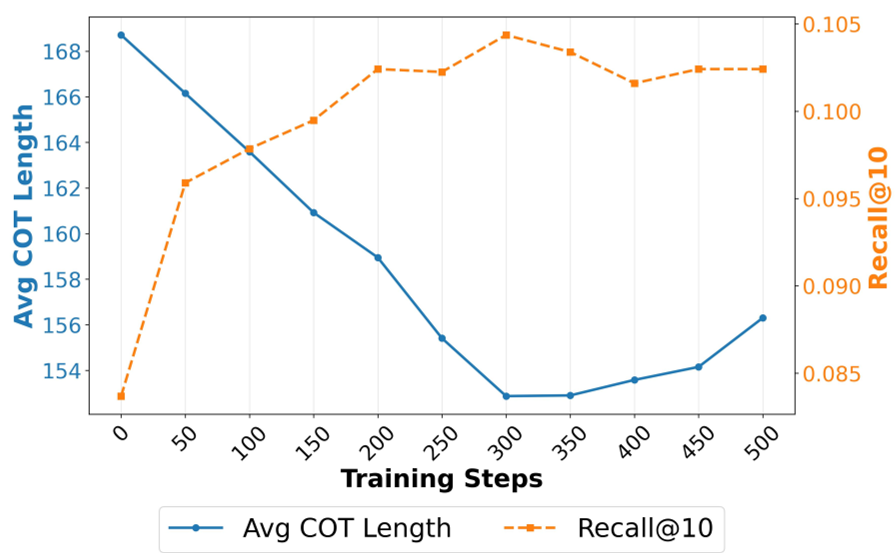 Figure 2: During RL, reasoning becomes shorter but more targeted.
Figure 2: During RL, reasoning becomes shorter but more targeted.
4. Why This Matters: Interpretability and Generalization
Beyond the numbers, SIDReasoner provides a "Post-hoc" look into the black box.
- Interpretability: You can read the model's "thought" process—e.g., "User likes Fire Emblem, and Amiibos enhance gameplay, so let's recommend the Reflet Amiibo."
- Cross-domain Transfer: Reasoning learned in one category (e.g., Games) actually helps the model perform better in another (e.g., Office) because the logic of recommendation is universal.
5. Conclusion & Future Outlook
SIDReasoner proves that you don't need million-dollar manual annotations to build a "Thinking Recommender." By aligning structured IDs with natural language and using RL to reward correct predictions, we can build systems that are both highly efficient and deeply intelligent.
Future Work: The next frontier is scaling this to 70B+ parameter models and testing if "longer thinking" (Inference Scaling) translates to even better "shopping" decisions.