本文提出了 RefAlign,一种用于参考图像生成视频 (R2V) 的表征对齐框架。该方法通过引入参考对齐 (RA) 损失,将 DiT 的参考分支特征显式对齐到视觉基础模型 (VFM) 的语义空间,在 OpenS2V-Eval 基准测试中取得了 SOTA 性能。
TL;DR
在参考图像生成视频 (Reference-to-Video, R2V) 领域,如何让模型既能“长得像”参考图,又能听懂指令动起来,一直是个难题。百度、南开大学等机构的研究者提出了 RefAlign,通过在训练中将 DiT 的特征对齐到视觉基础模型(如 DINOv3),成功消除了常见的视频“复制粘贴”感和多主体混乱。最重要的是:推理速度完全不减!
背景定位:R2V 的“既要又要”难题
目前的视频生成模型(如 Sora, Wan2.1)虽然文字转视频(T2V)很强,但在精细控制(如特定身份、特定服装)上仍显乏力。R2V 任务应运而生,但它面临两个顽疾:
- 复制粘贴伪影 (Copy-paste Artifacts):模型直接从参考图里搬像素,导致生成的视频像是一张静态图在扭动,背景和动作极不自然。
- 主体混淆 (Multi-subject Confusion):当参考图里有两个人时,模型往往会把他们的特征“杂交”,分不清谁是谁。
核心洞察:从隐式引导到显式对齐
作者观察到,传统的 VAE 编码特征在潜空间中非常“混乱”(Entangled),不同物体的边界模糊,而像 DINOv3 这样的视觉基础模型(VFM)天生具有极强的物体鉴别力。
 图 1:RefAlign 生成效果展示,精准保持身份的同时实现了大幅度动作。
图 1:RefAlign 生成效果展示,精准保持身份的同时实现了大幅度动作。
方法论:RA 损失函数的降维打击
RefAlign 的核心是 RA Loss (Reference Alignment Loss)。它不改变现有的 DiT 架构,而是在训练时给 DiT 的中间层额外加了一个“教练”(外挂的 VFM 编码器):
- 正向拉近 (Positive Alignment):要求 DiT 生成的参考特征必须靠近 VFM 提取的同主体语义特征,确保“神似”。
- 负向推开 (Negative Alignment):专门设计了一个带 Margin 的损失项,强制推开不同主体的特征,解决多主体干扰。
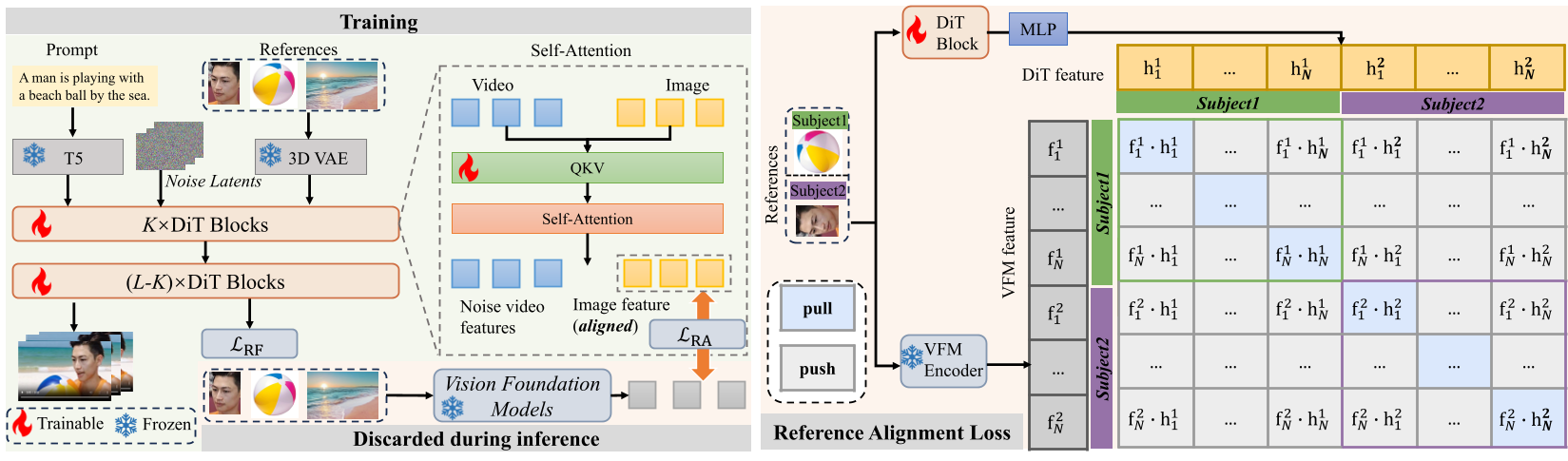 图 2:训练阶段引入 VFM 指导,推理阶段将其移除,实现“训练中学习,推理中零开销”。
图 2:训练阶段引入 VFM 指导,推理阶段将其移除,实现“训练中学习,推理中零开销”。
实验战绩:登顶 SOTA 分数线
在 OpenS2V-Eval 这一严苛的基准测试中,RefAlign 展现了统治级的表现。
| 模型 | 总分 (TotalScore) | 身份相似度 (FaceSim) | 文本一致性 (Gme) | | :--- | :--- | :--- | :--- | | RefAlign-14B | 60.42% | 55.23% | 68.32% | | Kling1.6 | 56.23% | 40.10% | 66.20% | | VINO | 57.85% | 52.00% | 69.69% |
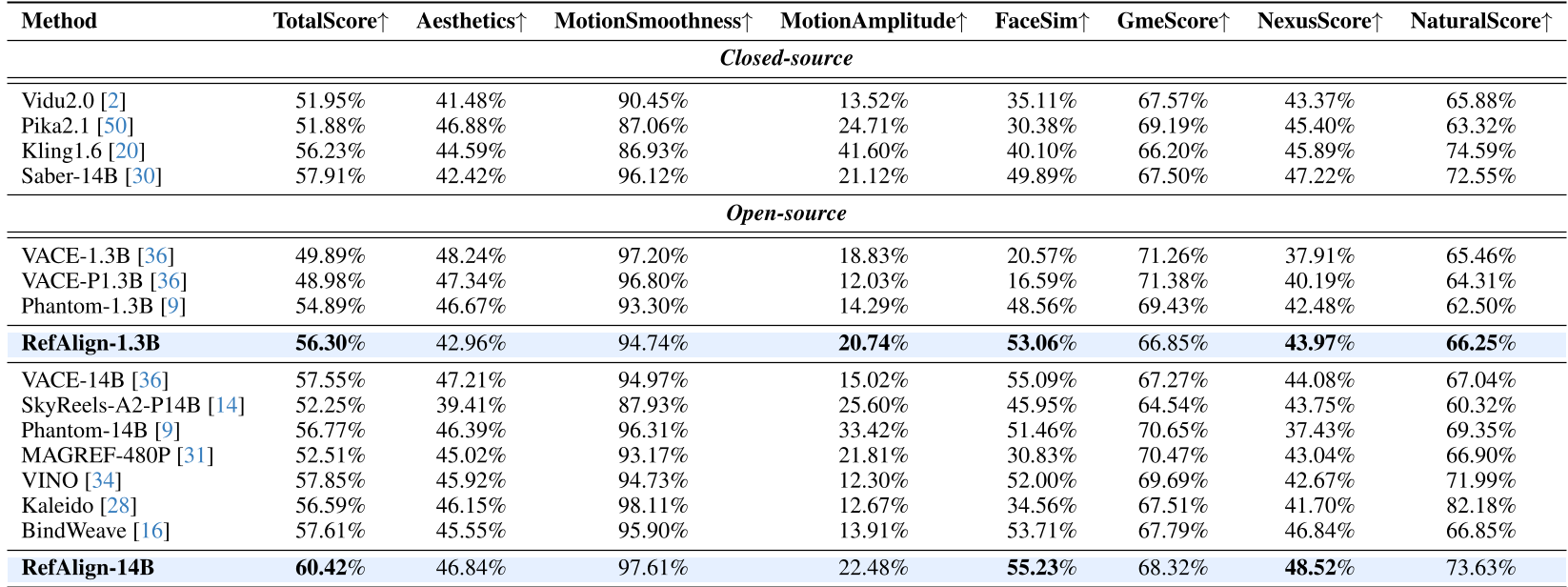 表 1:RefAlign 在各项指标上均处于行业领先地位,尤其在 NexusScore(主体一致性)上表现突出。
表 1:RefAlign 在各项指标上均处于行业领先地位,尤其在 NexusScore(主体一致性)上表现突出。
消融实验的关键发现
- 不加对齐损失 (w/o LRA):面部相似度虽高,但视频极易出现“静止”或“指令不服从”。
- 深度的影响:实验发现,对齐到第 9 层(中间层)效果最好。太浅了学不到语义,太深了反而会损失细节。
总结与限制
RefAlign 为视频生成的控制逻辑提供了一个全新的视角:借用成熟视觉模型的“眼睛”来训练生成模型的“手”。
它的优势:
- 有效平衡了参考图保真度与文本指令的遵循度。
- 解决了多角色场景下的身份错乱问题。
- 推理时无需额外计算资源。
局限性: 尽管能够处理 81 帧视频,但在极长序列生成上仍受限于底座模型(Wan2.1)。此外,如何利用多个 VFM(如结合 DINOv3 的结构与 SigLIP2 的语义)构建更完美的对齐信号,是未来值得探索的方向。
如果你对 R2V 感兴趣,RefAlign 提供的“训练期特征对齐”思路绝对是今年最值得关注的技术路线之一。