RC-GRPO-Editing is a region-constrained reinforcement learning (RL) post-training framework designed for flow-based image editing models like FLUX.1. It achieves State-of-the-Art (SOTA) performance on CompBench by optimizing instruction adherence and non-target preservation through localized credit assignment.
TL;DR
Instruction-guided image editing is a balancing act: you want to change the "cat" to a "tiger" without shifting a single pixel of the "sofa" it sits on. While flow-based models (like FLUX) provide high fidelity, fine-tuning them via Reinforcement Learning often "breaks" the background because exploration is too global. RC-GRPO-Editing solves this by constraining RL exploration to the target region and using cross-attention maps to keep the model's "focus" where it belongs.
The "Noisy Credit" Problem
Existing RL methods for image editing, such as Neighbor GRPO, treat the entire image as a playground for exploration. When the algorithm perturbs the initial noise to see which version gets a higher reward, it perturbs the background too.
From a signal processing perspective, this is nuisance variance. If the background reward fluctuates randomly because of global noise, the "signal" (the reward gain from a better edit) gets drowned out. The result? A model that either ignores the instruction or hallucinates artifacts in the background.
Methodology: RDP and ACD
The authors propose a two-pronged surgical approach to stabilize the GRPO (Group Relative Policy Optimization) process.
1. Region-Decoupled Perturbation (RDP)
Instead of adding noise to the whole latent space, RDP uses the editing mask to apply an anisotropic perturbation. It explores heavily in the target area but keeps the background almost frozen . This ensures that every candidate in the GRPO group has an almost identical background, effectively cancelling out background noise during reward standardization.
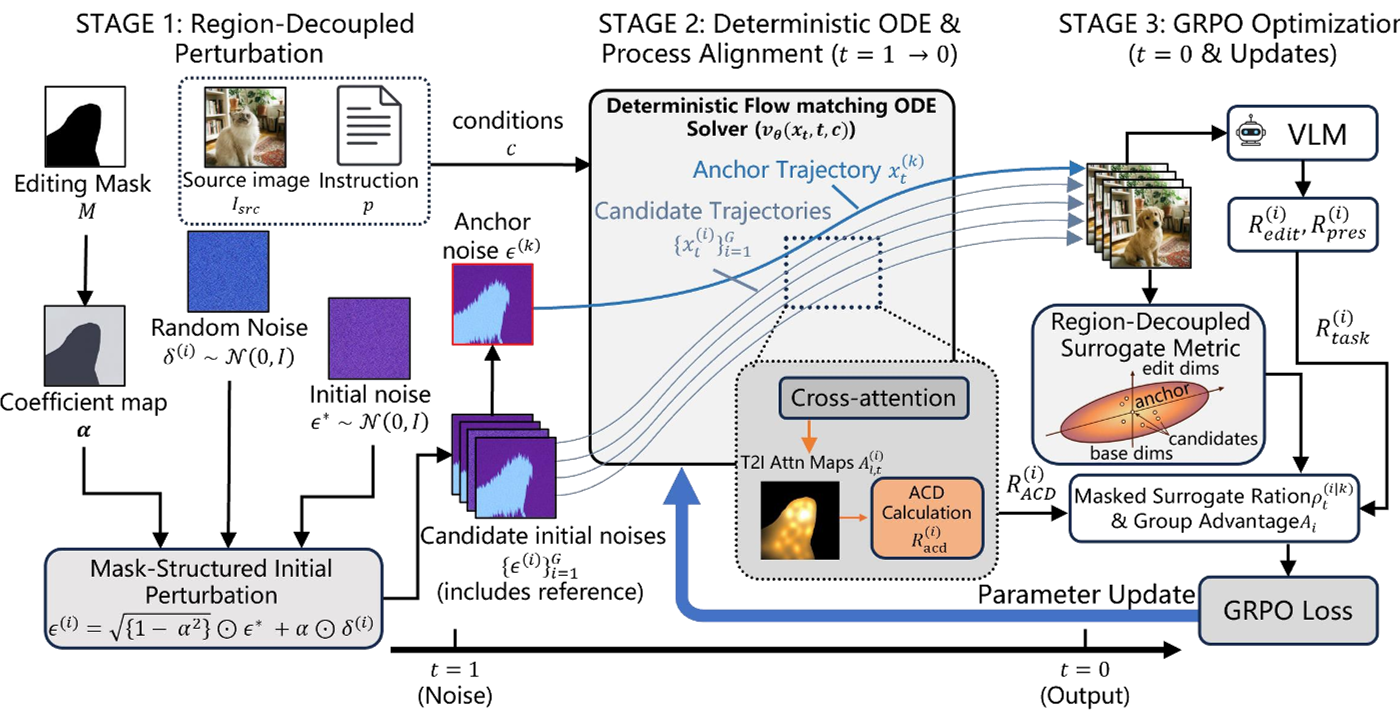 Figure 1: The RC-GRPO-Editing framework, showing how RDP and ACD work together during the ODE rollout.
Figure 1: The RC-GRPO-Editing framework, showing how RDP and ACD work together during the ODE rollout.
2. Attention Concentration Density (ACD)
Even if you only start with local noise, the Transformer's self-attention can spread that information everywhere during the rollout. To counter this, the authors introduce ACD as an intrinsic reward. It measures the ratio of attention mass inside the mask versus the global average. By rewarding high ACD, the model learns to keep its cross-attention "eyes" strictly on the target object.
Experimental Performance
The framework was tested on CompBench, a rigorous benchmark for complex edits (Add, Remove, Replace).
Quantitative Edge
RC-GRPO-Editing consistently beat the base FLUX model and other specialized editors like GoT and Step1X-Edit. Notably, it improved both the edit quality (LC-T) and the background preservation (PSNR) simultaneously—a rare "win-win" in editing.
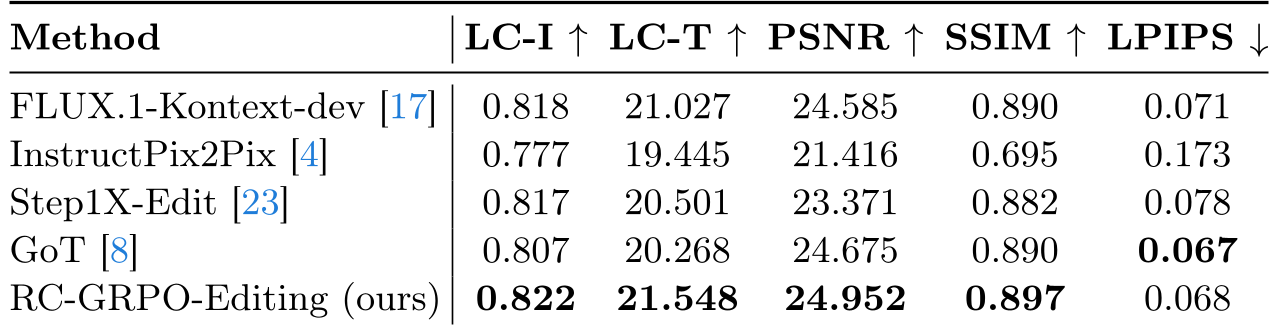 Table 1: Comparison on CompBench. RC-GRPO-Editing achieves the top scores in almost every category.
Table 1: Comparison on CompBench. RC-GRPO-Editing achieves the top scores in almost every category.
Visual Fidelity
Qualitative results show that competing models often leave "ghosts" of deleted objects or change the texture of the background. RC-GRPO-Editing maintains structural stability while executing the text command with higher semantic density.
 Figure 2: Visual comparison showing superior localization compared to baseline editors.
Figure 2: Visual comparison showing superior localization compared to baseline editors.
Critical Insight: The Power of Constraints
The brilliance of RC-GRPO-Editing lies in its realization that Reinforcement Learning doesn't need to be "blind." By baking the spatial constraints of the task into the exploration mechanism (RDP) and the reward (ACD), the authors transformed a high-variance optimization problem into a stable, localized one.
Limitations: The reliance on masks during training means you need a good segmentation tool or user-provided mask. Additionally, capturing global effects like "reflections" (where an edit should change the background slightly) remains a challenge for future work.
Conclusion
RC-GRPO-Editing sets a new standard for reward-driven post-training in the image domain. It proves that by aligning the exploration manifold with the task's spatial structure, we can fine-tune massive flow-based models to be both more imaginative and more disciplined.