本文提出了 RC-GRPO-Editing,一种针对 Flow-based 图像编辑模型的区域约束强化学习微调框架。通过引入区域解耦扰动(RDP)和注意力集中奖励(ACD),在保持确定性 ODE 采样的同时,显著提升了指令遵循准确度并降低了对非目标区域的破坏。
TL;DR
在图像编辑领域,如何“只改该改的地方”一直是核心痛点。本文提出了 RC-GRPO-Editing,通过将 GRPO (Group Relative Policy Optimization) 这一强大的 RL 算法适配到 Flow-based 模型上,并施加区域约束扰动 (RDP) 与注意力集中奖励 (ACD)。它成功在不增加推理成本的前提下,实现了编辑一致性与背景完整性的平衡。
痛点深挖:全局探索带来的“灾难性遗忘”
传统的 RL 训练(如 PPO, GRPO)在进行策略搜索时,通常会对输入进行全局扰动。在图像编辑任务中,这意味着模型为了尝试更好的编辑效果,会对整张图的噪声进行随机化。
这种做法存在两个致命缺陷:
- 信噪比极低:背景区域的随机变化产生的大量无效方差掩盖了编辑区域的真实奖励信号,导致模型不知道究竟是哪一步操作优化了结果(即 Credit Assignment 问题)。
- 背景破坏:即便指令只要求改“领带颜色”,全局扰动也会让模型学会改动“背景天空”,违背了编辑任务的初衷。
核心方法论:分而治之的 Credit Assignment
1. 区域解耦扰动 (Region-Decoupled Perturbation, RDP)
作者的直觉非常直接:既然只有编辑区域受控于指令,那么探索也应该只发生在该区域。RDP 利用编辑掩码 ,在初始噪声 注入时,赋予编辑区域更高的扰动系数 ,而背景区域则使用极小的系数 保持像素级的一致。
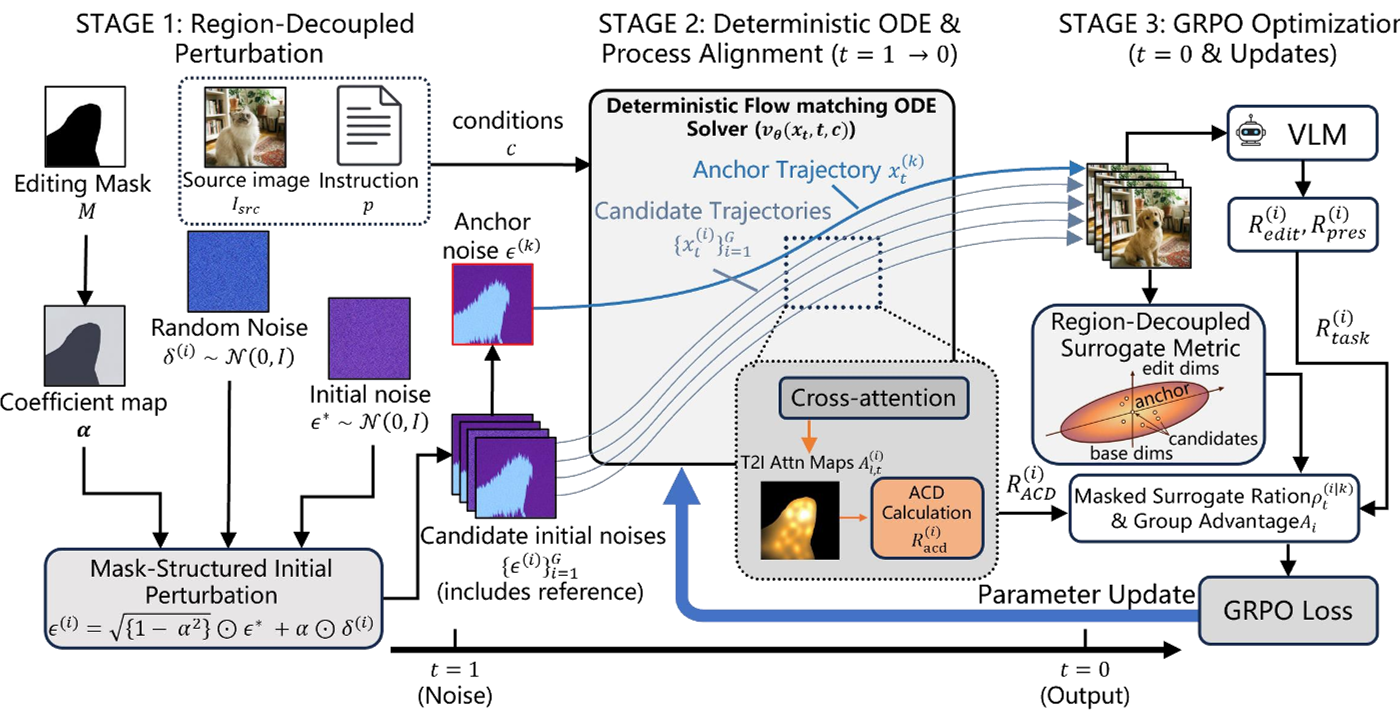
2. 注意力集中密度 (Attention Concentration Density, ACD)
仅在噪声阶段限制是不够的,Transformer 的全局注意力机制会导致信号泄露。为此,作者提出了 ACD 作为一种内在奖励 (Intrinsic Reward)。
- 原理:监测 Cross-Attention 图,计算编辑区域内的注意力质量与全局平均质量的比值。
- 效果:模型在训练中被强制要求“关注”掩码内。如果模型试图通过修改非目标区域来获取更高得分,ACD 奖励将显著下降。
实验与结果:全方位的 SOTA
在 CompBench 这一针对复杂编辑指令的测试集上,RC-GRPO-Editing 展现了统治级的表现。
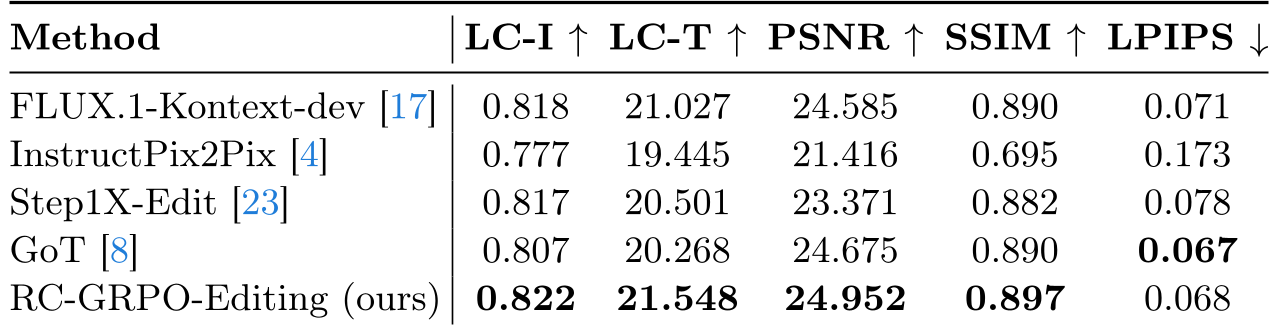
- 性能飞跃:在 LC-T(语义一致性)和 PSNR(背景保存)上均超越了如 InstructPix2Pix 和 GoT 等强基线。
- 消融实验:图 5 显示,使用 RDP 后背景漂移(Background Drift)的累积分布函数趋向于极小值,验证了其在减少方差方面的卓越能力。

深度洞察:为何这篇论文很重要?
RC-GRPO-Editing 的意义在于它为 Deterministic ODE(确定性微分方程)采样模型 找到了一种稳健的 RL 训练方案。以往的 RL 往往需要 SDE(随机过程)来提供探索性,而本文基于 Neighbor GRPO 的思路,通过巧妙的掩码结构化距离度量,在保持推理效率(一步推理或高效求解器)的同时,压榨出了基础模型(FLUX.1-Kontext)的极限。
总结与未来
RC-GRPO-Editing 成功解决了编辑任务中“性能提升”与“背景崩坏”的零和博弈。
- 优势:训练高效、不增加推理负担、局部性极强。
- 局限:目前高度依赖准确的编辑掩码。如果输入的 Mask 本身不准,ACD 可能会产生错误的引导。
未来,该路径可能扩展到无掩码自适应编辑,即让模型自动判别哪些 Cross-Attention 区域是关键的,并在该子空间内进行策略优化。