The paper introduces Summary-Driven Reinforcement Learning (SDRL), a single-stage RL framework for Video Multi-modal Large Language Models (MLLMs). It utilizes a Structured Chain-of-Thought (Summarize → Think → Answer) to ground reasoning in temporal facts, achieving state-of-the-art performance across seven VideoQA benchmarks including NExT-GQA and VideoMME.
TL;DR
Video-based Multi-modal Large Language Models (MLLMs) often "hallucinate" logic even when they see the right frames—a phenomenon known as thinking drift. Summary-Driven Reinforcement Learning (SDRL) fixes this by forcing the model to follow a rigid Summarize → Think → Answer pipeline. By using a single-stage RL approach with self-supervised consistency checks, it hits SOTA across 7 benchmarks while being more efficient and concise than traditional SFT+RL methods.
The Problem: When Models Forget What They Saw
Despite the power of Chain-of-Thought (CoT), video understanding models struggle with two main issues:
- Thinking Drift: Without constraints, a model's intermediate reasoning can wander away from the actual video content, leading to a "right answer for the wrong reasons" or total failure.
- Temporal Blindness: Standard MLLMs often treat videos as a bag of frames, missing the crucial "what happened before what" logic.
Previous attempts to fix this required Supervised Fine-Tuning (SFT) on thousands of human-annotated reasoning paths. This is not only expensive but also creates "lazy" models that only mimic specific paths rather than exploring the best way to solve a problem.
Methodology: Summarize, Then Think
SDRL replaces the complex SFT+RL pipeline with a streamlined, single-stage RL process. The core intuition is that if a model can first produce a factually accurate Summary of actions, its subsequent Thinking will be naturally grounded.
1. Structured CoT
The model is prompted to follow a specific format:
- Summarize: A chronological list of key events.
- Think: Logical deduction based on that summary.
- Answer: The final output.
2. Consistency of Vision Knowledge (CVK)
How do we ensure the summary is correct without human labels? SDRL assumes that if you ask a model the same question multiple times (sampling a group), the "correct" paths should all have very similar summaries. CVK penalizes summaries that diverge from the group's "consensus" anchor, effectively rewarding factual stability.
3. Dynamic Variety of Reasoning (DVR)
While we want summaries to be consistent, we want the reasoning (the "Think" part) to be diverse to explore different logical paths. SDRL uses an entropy-based reward that encourages diversity when the model is uncertain but stabilizes once the model finds a successful path.
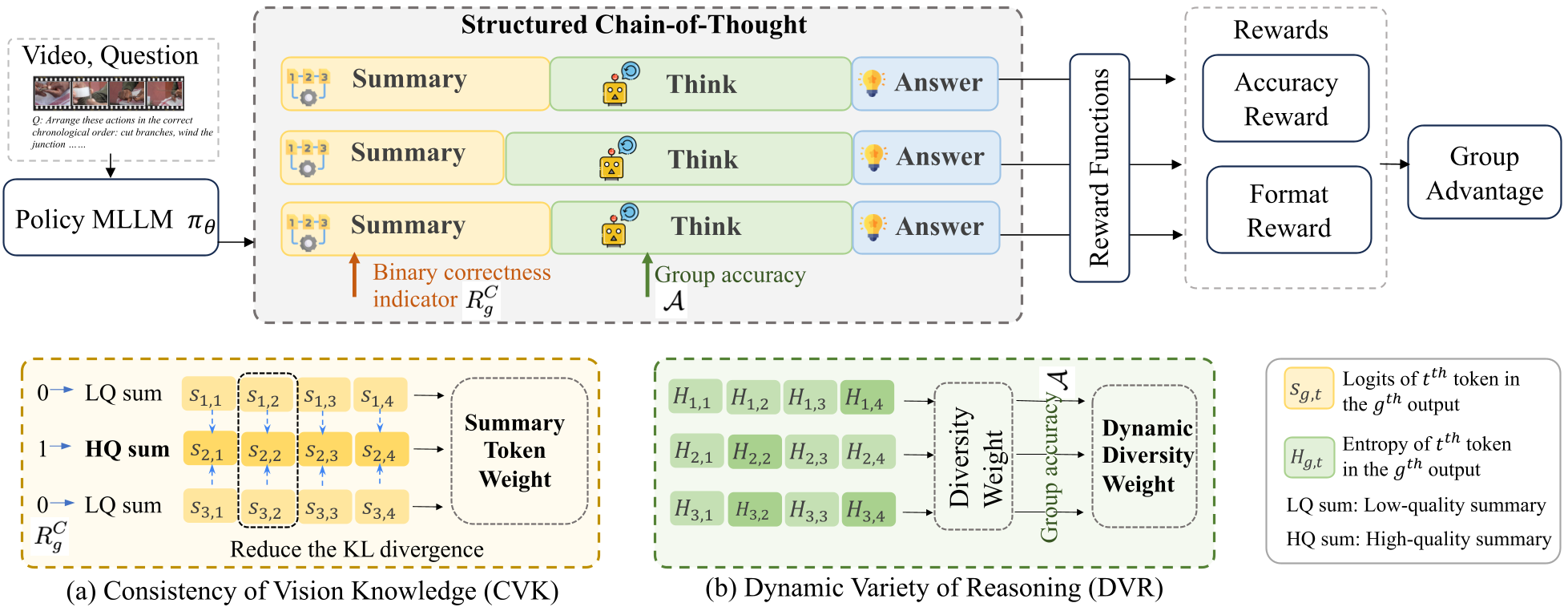 Figure 1: The SDRL Framework. Note how CVK and DVR act as "weights" on the tokens during the RL update to balance grounding and exploration.
Figure 1: The SDRL Framework. Note how CVK and DVR act as "weights" on the tokens during the RL update to balance grounding and exploration.
Experimental Triumphs
The researchers tested SDRL against heavyweights like Video-R1 and Qwen2.5-VL. The results were telling:
- Higher Accuracy: On the NExT-GQA reasoning benchmark, SDRL scored 79.3%, a +5.7% jump over the base model.
- Efficiency: Unlike other RL models that become "chatty" (generating long, redundant reasoning), SDRL's outputs are significantly more concise.
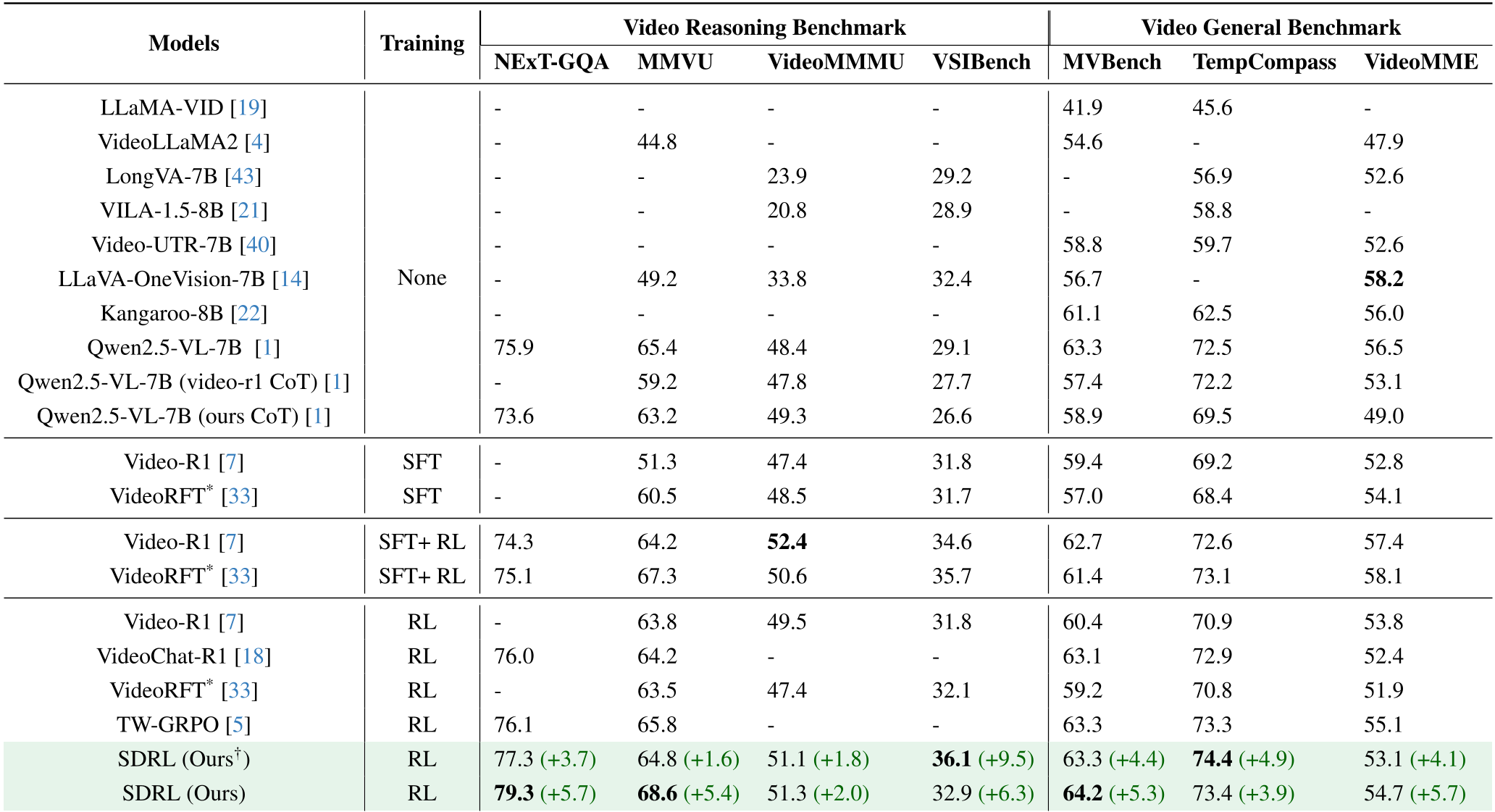 Table 1: State-of-the-art results across various benchmarks. SDRL consistently outperforms SFT+RL hybrids.
Table 1: State-of-the-art results across various benchmarks. SDRL consistently outperforms SFT+RL hybrids.
Why Self-Supervision Wins
One of the most interesting findings was that for larger models (7B), self-supervision performed better than ground-truth human labels. This suggests that forcing a large model to match a specific human summary can actually "over-constrain" it, whereas self-consistency allows the model to leverage its internal pre-trained knowledge more effectively.
Visual Evidence: Grounding in Action
In qualitative tests, SDRL demonstrated a much higher BLEU and sBERT score for its summaries compared to previous RL methods.
 Figure 2: Notice how SDRL (bottom) provides a structured chronological summary that leads directly to the correct answer, whereas other models struggle with temporal order.
Figure 2: Notice how SDRL (bottom) provides a structured chronological summary that leads directly to the correct answer, whereas other models struggle with temporal order.
Limitations & Future Outlook
While SDRL is a leap forward, it isn't perfect. For extremely fast, "micro-action" videos (like a magic trick or fast shuffling), the model tends to provide a "coarse" summary that might miss the split-second frames needed for a correct answer. Future iterations may need even denser temporal rewards to capture these atomic movements.
Conclusion
SDRL proves that we don't need million-dollar datasets of "expert reasoning" to make MLLMs smarter. By simply enforcing a Structured CoT and rewarding self-consistency, we can create models that are not only more accurate but also more stable and efficient. This work sets a new standard for training high-performance video agents with minimal supervision.