本文提出了 Relax Forcing,一种用于自回归(AR)视频扩散模型长视频生成的结构化稀疏 KV 内存机制。该方法通过将时间上下文分解为固定的 Sink(锚点)、最近的 Tail(连续性)和动态选择的 History(运动引导),在不增加训练成本的情况下显著提升了长视频生成的动态程度和时间一致性。
TL;DR
在视频生成领域,单纯增加模型“记忆力”(Memory Capacity)并不总能带来更好的结果。由伦敦玛丽女王大学等机构提出的 Relax Forcing 揭示了一个反直觉的现象:在自回归视频生成中,密集的历史缓存反而会“锁死”运动活力。通过将 KV 内存拆解为 Sink (锚点)、Tail (尾部) 和 History (动态历史) 三种职能角色,该方法在不需重新训练的前提下,让长视频的运动动态度(Dynamic Degree)惊人地提升了 66.8%,同时推理速度更快。
痛点深挖:为什么内存越多,动作越僵?
当前的自回归 (AR) 视频扩散模型(如 Llama-Gen, Self-Forcing 等)在生成长视频时,通常采用滑动窗口(Sliding Window)策略。传统观念认为,只要缓存(KV Cache)中保留的历史帧越多,生成就越稳定。
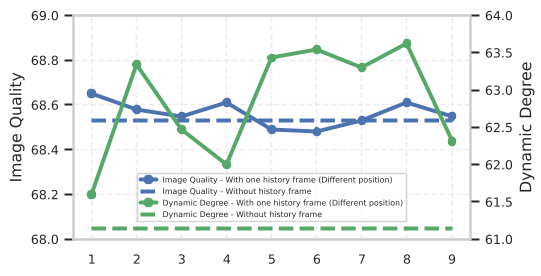
然而,作者通过实验(见图 2)发现了两个核心瓶颈:
- 冗余限制运动:密集的历史帧提供了过多的相似约束,导致模型在生成下一帧时倾向于“保守”,从而抑制了动作的演变。
- 职能混淆:早期的帧(远景锚点)与最近的帧(运动连续性)对模型的影响是不同的。现有的方法将它们视为同质的缓冲区,导致模型在长程外推时容易发生语义漂移(Drift)。
核心机制:Relaxed KV Memory (职能化内存)
Relax Forcing 的核心在于 “有所为,有所不为”。它放弃了密集的连续缓存,转而构建了一个结构化的稀疏集合 :
- Sink (S):固定选择视频开头的 2 帧。它们就像“定海神针”,确保视频在生成一分钟后,主角的长相和背景场景依然如初。
- Tail (T_i):保留最近生成的 1 帧。确保帧与帧之间的毫秒级平滑过渡。
- History (H_i):这是最精妙的部分。模型从中间区域动态筛选 1 帧最具代表性的历史。
放松评分(Relaxation Score)
如何选出这一帧 History?作者提出了一种全新的评分函数: 其中 是与 Sink 的稳定性一致性得分,而 是与最近 Tail 帧的冗余度得分。通过这种方式,选出的帧既能维持全局特征,又提供了与当前时刻不同的“新信息”,从而激发运动活力。
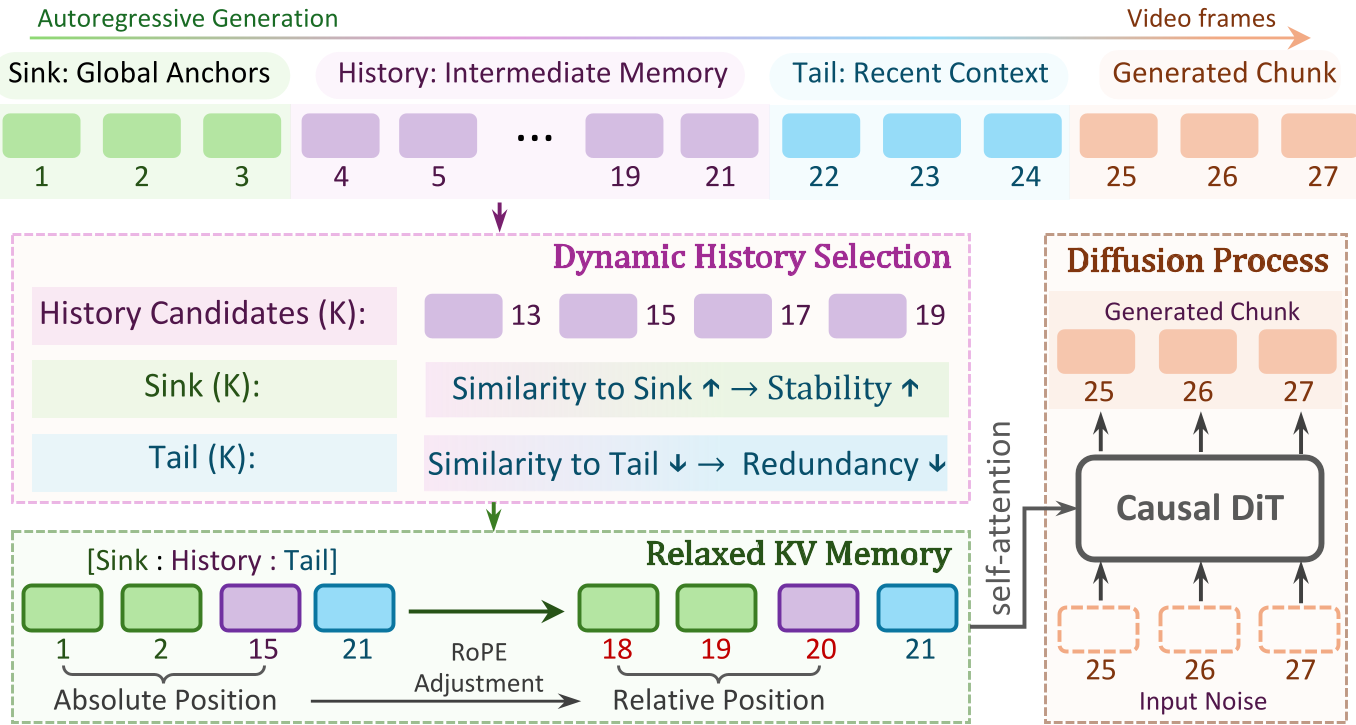
混合位置编码:解决时间断层的“胶水”
由于 是非连续的采样,传统的位置编码会导致时间感知的混乱。作者引入了 Hybrid RoPE:
- 对 Tail 使用绝对原始索引,保持当前的时间坐标。
- 对 Sink 和 History,将它们逻辑上“锚定”在 Tail 之前的一个连续区间内。 这种处理确保了模型既能感受到长程的时间跨度,又不会因为采样间隙产生语义跳变。
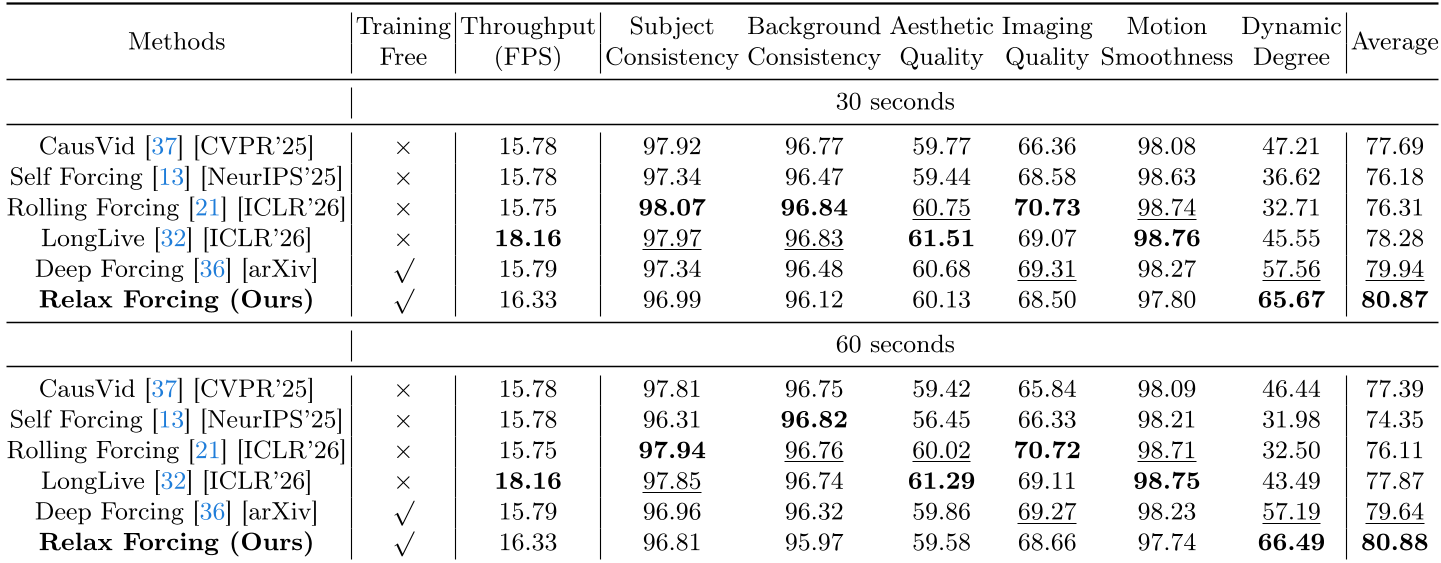
实验结果:更动感、更高效
在 VBench-Long 的严苛测试下,Relax Forcing 的表现堪称惊艳:
- 运动表现打破天花板:Dynamic Degree 从基线的 36.62 飙升至 65.67。
- 推理效率提升:由于 Attention 的计算量随 Token 数量二次增长,将内存从 18 帧精简到 4 帧后,自注意力计算时间缩短了 2.64 倍,整体推理提速约 26%。
深度洞察与总结
Relax Forcing 给了我们一个深刻的启示:在生成式 AI 中,遗忘有时和记忆同样重要。
- 贡献总览:它通过对内存职能的解耦,解决了长视频生成中“稳而不动”的痼疾,且作为一种 Training-free 的推理策略,具有极强的通用性。
- 局限性:尽管目前在 60 秒级别表现优异,但对于更复杂的非线性叙事(如多个场景切换),单纯靠 4 帧稀疏采样是否足够维持复杂的逻辑一致性,仍值得商榷。
- 展望:这种“结构化稀疏”的思想未来可以扩展到 3D 扩散或多模态大模型中,作为一种更高效的长上下文管理手段。
作者注:本文探讨的方法已在开源社区引起关注,对于追求长视频一致性的开发者,Relax Forcing 提供了一个极低成本的优化路径。