ReLi3D is a unified end-to-end pipeline that reconstructs high-quality 3D geometry, spatially-varying PBR materials, and HDR environment illumination from sparse multi-view images in under 0.3 seconds. It utilizes a cross-view transformer fusion and a two-path prediction strategy to achieve state-of-the-art disentanglement of lighting and appearance.
TL;DR
ReLi3D is the first unified feed-forward model that converts sparse, unconstrained images into production-ready 3D assets—complete with SVBRDF materials and HDR lighting—in under 0.3 seconds. By leveraging multi-view constraints within a transformer-triplane architecture and a differentiable Monte Carlo renderer, it solves the classic "baked-in lighting" problem that plagues current fast 3D generators.
Academic Positioning: This work bridges the gap between fast Large Reconstruction Models (LRMs) (like TripoSR/SF3D) and high-quality Inverse Rendering optimization (like NeRF/Gaussian Splatting), moving the field toward instantaneous, relightable digital twins.
1. The Core Tension: Speed vs. Physical Plausibility
In the current 3D vision landscape, we face a frustrating trade-off:
- Optimization-based Methods: Achieve stunning results by "overfitting" to a scene but take minutes or hours.
- LRMs (Feed-forward): Generate 3D meshes in milliseconds but usually "bake" the lighting into the textures. If you try to put a generated object into a new lighting environment, it looks "fake" because its original shadows and highlights are stuck on its surface.
The fundamental culprit is ambiguity. For a single image, the neural network cannot tell if a white pixel is a white surface or a black surface hit by a bright flash.
2. Methodology: Geometry, Materials, and Lighting in Two Paths
The insight of ReLi3D is that multiple views provide the constraints needed to break this ambiguity. If a surface point is seen from two angles, the fixed material property (albedo) remains constant, while the view-dependent reflection changes, allowing the model to "math out" the difference.
A. The Cross-View Transformer
Unlike previous models that process images independently and average them, ReLi3D uses a Hero View mechanism. One image acts as the primary "query," while other views provide "context" through a cross-conditioning transformer. This builds a unified Triplane feature set that is inherently consistent across viewpoints.
B. The Two-Path Architecture
The Triplane then feeds into two parallel "brains":
- Path 1 (Geometry & Appearance): Predicts the mesh (using Flexicubes) and the svBRDF parameters (Albedo, Roughness, Metallic, Normals).
- Path 2 (Illumination): Uses a dedicated transformer to predict a RENI++ latent code, representing the high-dynamic-range (HDR) world map surrounding the object.
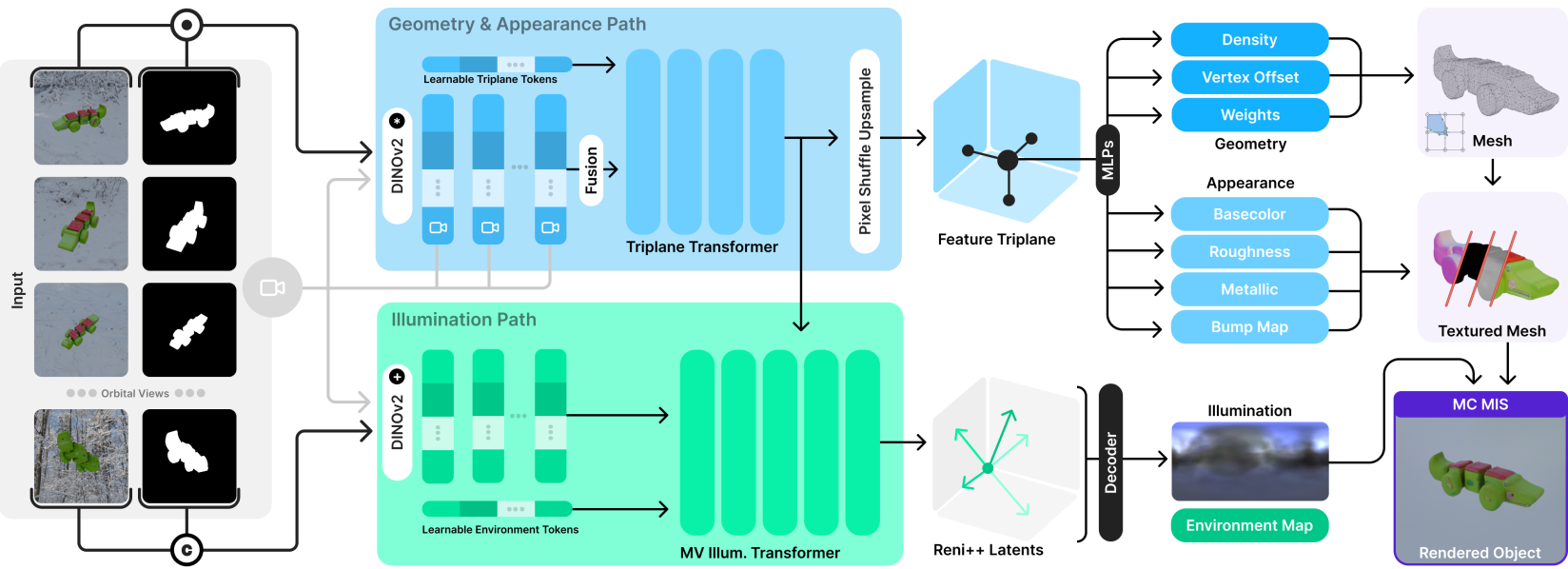 Figure 2: The ReLi3D pipeline. Note the dual-path split where geometry and lighting are separately managed but jointly rendered.
Figure 2: The ReLi3D pipeline. Note the dual-path split where geometry and lighting are separately managed but jointly rendered.
3. Disentangled Training via MC+MIS
To ensure the "Albedo" map actually represents color and not lighting, the authors employ a differentiable Monte Carlo Multiple Importance Sampling (MC+MIS) renderer.
During training, the model must render the object back into a 2D image. If the model puts a shadow in the Albedo map instead of calculating it via the Illumination path, the physical laws of the MC renderer will penalize it. This "physics-constraint" forces the network to learn true material properties.
4. Performance & Results
ReLi3D dominates in Relighting Fidelity. Because it reconstructs true PBR materials (Roughness/Metallic maps), the objects look natural when moved from an "indoor" training set to a "sunset" test environment.
- Speed: ~0.3s (vs. 30s-60s for diffusion models like Hunyuan3D).
- Material Quality: Albedo PSNR is ~35% higher than previous state-of-the-art (SF3D).
- Consistency: Adding even 2-4 views significantly reduces geometric errors (CD) by roughly 27%.
 Figure 3: Relighting Comparison. ReLi3D objects (right) react naturally to new light sources, whereas baselines often look flat or inconsistent.
Figure 3: Relighting Comparison. ReLi3D objects (right) react naturally to new light sources, whereas baselines often look flat or inconsistent.
5. Critical Analysis & Future Outlook
Key Takeaway
ReLi3D proves that we don't need "bigger" models or "more" data as much as we need better inductive biases. Using the laws of physics (via the MC renderer) acts as a powerful regularizer that synthetic data alone cannot provide.
Limitations
- Resolution: The 384x384 triplane resolution is a bottleneck. High-frequency textures (like fine fabric) still appear slightly blurred compared to multi-minute optimization methods.
- Specular Complexity: In cases with many tiny, bright lights (e.g., a disco ball), the RENI++ prior can struggle, leading to some baked-in highlights.
The Future
This approach is a massive win for AR/VR and E-commerce. The ability to take 3 photos of a product and immediately get a relightable, high-quality 3D asset on a mobile device is now within reach. The next step will likely involve scaling this architecture with Video Generative Priors to handle even more complex occlusions.
Summary: ReLi3D isn't just another 3D reconstructor; it's a step toward machines that truly understand the interaction between light and matter.