本文提出了 Relit-LiVE,一种新型视频重打光(Video Relighting)框架。通过联合学习重打光视频与环境视频(Environment Video),该方法在无需相机位姿先验的情况下,实现了物理一致且时间稳定的光影生成,在合成与真实评测中均达到 SOTA。
TL;DR
传统的视频重打光(Video Relighting)往往在“物理真实”与“生成质量”之间难以兼顾,且极度依赖昂贵的相机位姿数据。Relit-LiVE 通过联合生成“重打光视频”与“环境视频”,在无位姿先验的情况下,利用原始图像(Raw Reference)修正神经渲染误差,实现了极具物理真实感的倒影、折射与动态阴影效果。
背景定位:神经渲染的“最后一公里”
目前的视频重打光主要分为两条路线:一是直接生成派(如 Light-A-Video),光影控制粗糙且容易丢失材质细节;二是内在分解派(如 Diffusion Renderer),依赖物理 G-buffer 进行渲染。
Relit-LiVE 的出现填补了中间地带:它既保留了 G-buffer 的物理约束(Inductive Bias),又通过引入原始 RGB 视频填补了复杂光路(如 subsurface scattering)的视觉空缺,是当前视频编辑领域走向工业级应用的标杆之作。
核心洞察:为何需要“环境视频”?
在移动摄像头的视频中,环境贴图必须随相机位姿实时旋转(Warping)。前人工作要么要求精准的相机参数,要么假设环境静止。 Relit-LiVE 的天才之处在于将“打光转换”看作一种生成任务:模型在输出结果的同时,预测每一帧对应的、对齐过的环境贴图分支。这种联合学习(Joint Learning)不仅免去了相机标定的烦恼,还迫使模型在潜空间学到了光影与几何的耦合关系。
架构深度解析
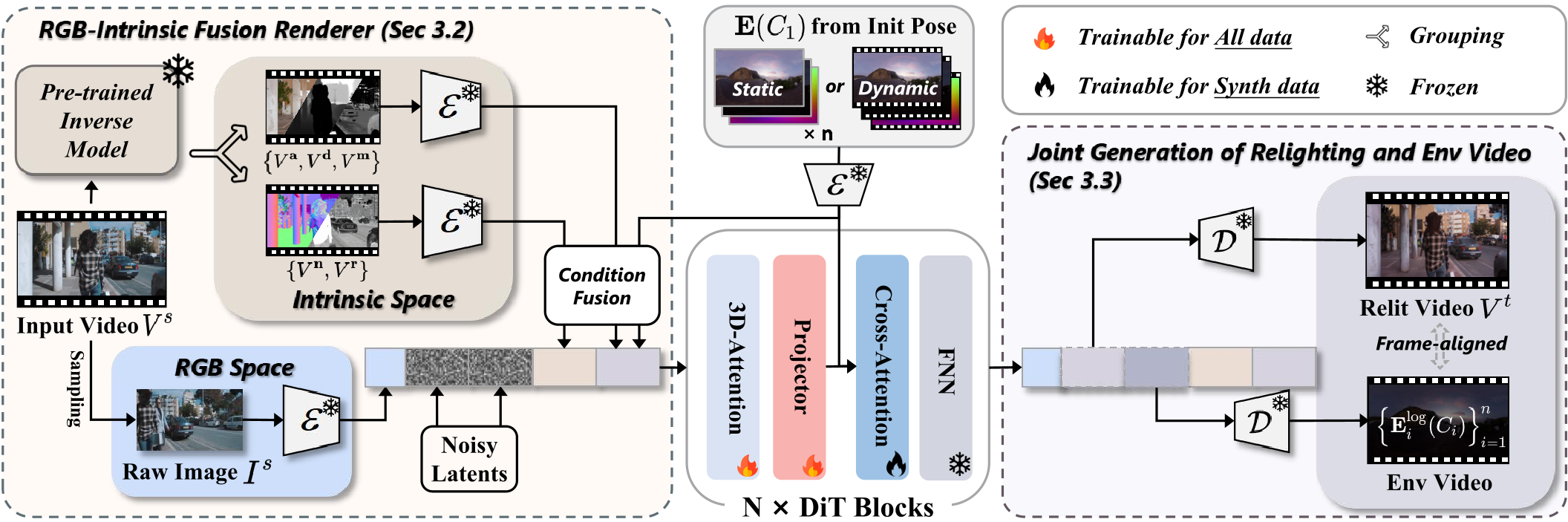
该架构主要包含三个关键模块:
- RGB-Intrinsic 融合渲染器:为了防止模型在内在属性(Albedo, Normal 等)估测错误时产生伪影,作者将编码后的原始图像潜向量(Raw Latent)与 G-buffer 潜向量融合。
- 组内加法优化(Group-wise Addition):为了降低计算开销,作者并未暴力堆叠所有特征通道,而是将相关性强的属性(如 Roughness 和 Metallic)进行加权求和,在降低 25% 显存占用的同时保持了控制精度。
- 双路灯光控制:环境贴图通过 Cross-Attention 和直接特征融合(Feature Fusion)双重注入,确保模型既能捕捉宏观色温,又能保留微观反射纹理。
实验战绩与应用展示
在对比实验中,Relit-LiVE 在合成数据集和 MIT 真实评测集中均大幅领先 Baseline。特别是在复杂材质(如玻璃瓶、塑料袋)的重打光上,前作往往会出现细节模糊或材质崩坏,而 Relit-LiVE 能清晰呈现折射逻辑。

核心下游能力:
- 流式视频处理:支持分段长视频重打光,保持长程的一致性。
- 物体插入与编辑:在修改 intrinsic 属性后,新插入的物体能获得完美的阴影掩蔽和环境反射。
- 视频去光效应(Delighting):移除原始视频中的强高光,为 3D 重建提供纯净的材质贴图。
资深主编点评
Relit-LiVE 解决了一个长期被忽略的痛点:内在分解的不完美性。它通过 IPE(内在感知增强)和 SIC(自监督照明一致性)两套策略,构建了一个能从海量无标注野外视频中学习的闭环。
局限性分析:尽管通过架构优化降低了开销,但在 A800 GPU 上生成 57 帧视频仍需约 10 分钟。这意味着实时性仍是其大规模工业化(如直播实时滤镜)的主要阻碍。
总结
Relit-LiVE 不仅仅是一个重打光工具,它展示了如何通过扩散模型将复杂的物理渲染管线“生成化”。对于那些追求极致电影感视频编辑的研究者来说,这篇论文提供的“RGB 参考引导”思路极具参考价值。