LaviGen is a novel framework that repurposes 3D generative models for autoregressive 3D layout generation. By operating directly in native 3D space rather than treating layouts as language, it achieves state-of-the-art results in physical plausibility (19% improvement) and inference speed (65% faster).
TL;DR
LaviGen shifts 3D layout generation from the domain of "Language Modeling" (JSON-text) back to "Geometric Modeling." By repurposing high-fidelity 3D generative priors (like TRELLIS), it defines layout generation as an autoregressive diffusion process in native 3D space. The result is a system that is 65% faster and 19% more physically plausible than previous vision-augmented baselines, effectively eliminating common issues like object overlapping and floating.
The Problem: The "Language" of Layouts is Too Shallow
Modern layout generators often rely on Large Language Models (LLMs) to output JSON strings representing bounding boxes. While LLMs have excellent semantic common sense (e.g., "chairs go around a table"), they suffer from a lack of physical grounding.
Previous works attempted to fix this through:
- Iterative Optimization: Slow and prone to local minima.
- 2D Visual Supervision: Using rendered images to "guide" the 3D layout, which is computationally heavy and fails to capture the full 3D complexity.
The authors of LaviGen argue that scene layout is simply a special type of geometric distribution. Instead of teaching a text model about space, why not use a model that already "understands" 3D geometry?
Methodology: Autoregressive 3D Diffusion
LaviGen adapts the TRELLIS structured 3D latent framework. It represents a scene as a set of voxel-indexed local latent codes.
1. Architecture & Identity-Awareness
The model takes the current scene state and a target object to generate the next state . To prevent the model from confusing the pre-existing environment with the new addition, the authors introduced Identity-aware Positional Embeddings. This adds a source flag (0 for scene, 1 for object) to the standard Rotary Position Embedding (RoPE), allowing the Multimodal Diffusion Transformer (MMDiT) to distinguish between the "canvas" and the "brush."
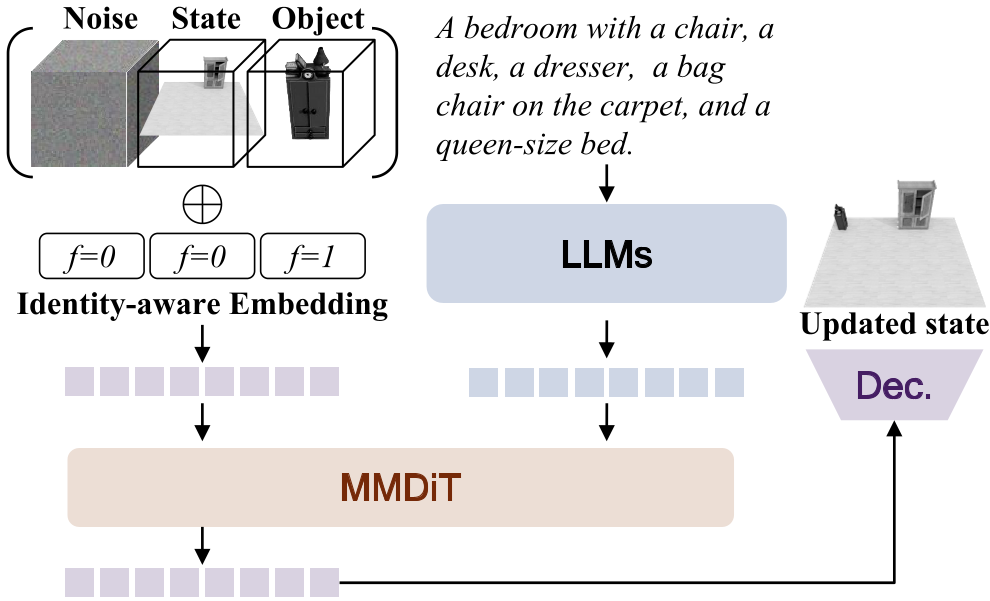 Figure: The adapted 3D diffusion model architecture showing identity-aware embedding integration.
Figure: The adapted 3D diffusion model architecture showing identity-aware embedding integration.
2. Solving Exposure Bias: Dual-Guidance Distillation
Autoregressive models usually suffer from exposure bias—the model is trained on ground-truth data but must predict based on its own (potentially flawed) previous outputs during inference.
LaviGen solves this via Dual-Guidance Self-Rollout Distillation:
- Holistic Guidance: A frozen base model acts as a "Global Teacher," ensuring the final completed scene looks coherent.
- Step-wise Guidance: A frozen causal teacher provides "per-step" corrections, ensuring each object placement is locally accurate.
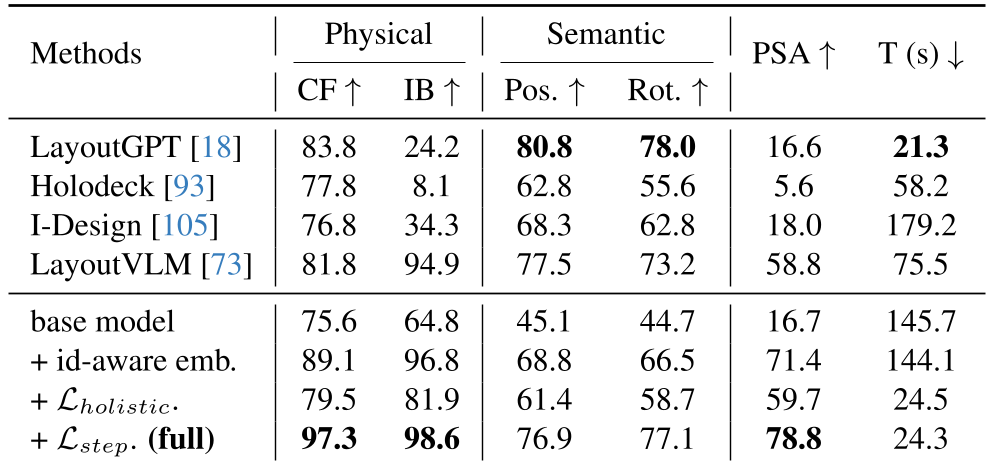
Experimental Performance
The quantitative leap is substantial. In the "Collision-Free" (CF) category, LaviGen reaches almost perfect scores (97.3), while traditional LLM-based methods like LayoutGPT struggle at 83.8.
The qualitative results highlight the "Native 3D Advantage." In complex scenarios like gaming rooms or cluttered bedrooms, LaviGen avoids the "object intersection" traps that plague language-only or 2D-optimized models.
 Figure: LaviGen vs. Baselines. Note how LaviGen maintains spatial boundaries in the "Gaming Room" example.
Figure: LaviGen vs. Baselines. Note how LaviGen maintains spatial boundaries in the "Gaming Room" example.
Beyond Generation: Completion and Editing
Because LaviGen operates in native 3D space, it naturally excels at:
- Layout Completion: Taking a partial room and filling it in based on an instruction.
- Layout Editing: Swapping, removing, or inserting objects while maintaining context-aware spatial coherence.
Critical Analysis & Conclusion
Takeaway
LaviGen represents a pivot back to 3D Native representations. It proves that for spatial tasks, a 3B-parameter Diffusion Transformer trained on geometric priors can outperform 70B+ LLMs that only "read" about space.
Limitations
The primary bottleneck is Voxel Resolution. Currently limited to a grid, the model may struggle with very small objects or fine-grained interactions. Future iterations utilizing sparse attention or higher-resolution octrees could potentially unlock even more complex scene synthesis.
In conclusion, LaviGen sets a new standard for AR/VR environment generation by grounding the "imagination" of diffusion models in the "reality" of 3D geometry.