本文提出了关于推理任务 SFT(有监督微调)泛化性的条件分析框架,通过系统实验挑战了“SFT 仅靠记忆,RL 才能泛化”的传统认知。研究指出,在长 CoT(思维链)监督下,SFT 的跨域泛化性受优化动力学、数据质量及模型基础能力共同驱动,并在特定条件下能实现显著的 SOTA 提升。
TL;DR
长期以来,AI 学界流传着一个心照不宣的准则:“SFT 负责背书,RL 负责思考”。然而,来自上海人工智能实验室等机构的最新论文《Rethinking Generalization in Reasoning SFT》彻底翻转了这一直觉。通过对长 CoT(思维链)监督下的 SFT 进行深度拆解,作者发现:只要优化到位、数据够纯、模型够强,SFT 不仅能逆袭 RL 的泛化性,甚至能从“小学数学”中学到通用的“逻辑回溯”能力。
核心速览:泛化性是“练”出来的,不是“天生”的
本文的核心定位是**“理论修补与范式重构”**。它指出,我们过去看到的 SFT 泛化失败,往往是由于“欠优化(Under-optimization)”导致的假象。
- 位置:后训练(Post-training)理论前沿。
- 发现:跨域性能在训练中呈现“U 型”走势。
痛点深挖:我们是否低估了 SFT?
先前的工作(如 Chu et al., 2025)认为 SFT 会导致模型僵化。作者敏锐地洞察到三个被忽略的变量:
- 训练深度:大多数实验只跑了 1 个 Epoch,此时模型正处于“模仿长文表象”的低谷期。
- 数据逻辑:杂乱的、未经校验的人工数据会污染泛化性。
- 规模效应:强模型学逻辑,弱模型学字数。
方法论详解:理解“先降后升”的动力学
作者观察到一个非常有意思的现象:Dip-and-Recovery(性能跌落与恢复)。
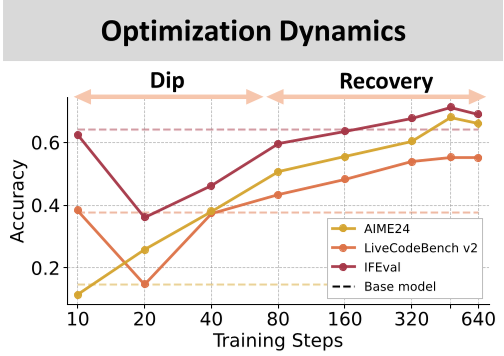
在长 CoT 训练的初期,模型会经历一个“字数激增”但“逻辑混乱”的阶段。在这个阶段,模型学会了表现得很“思考”,却经常犯低级错误(例如忘记闭合思考标签)。随着训练继续(如到第 8 个 Epoch),模型生成的步长开始收缩,逻辑变得精炼,此时 OOD(出域)性能才开始猛增。
逻辑直觉:模型必须先学会“废话(表面模仿)”,才能在不断的梯度更新中剔除冗余,内化“回溯(Backtracking)”和“验证(Verification)”等高阶程序模式。
实验与结果:即便只有“小学口算”也能变聪明
最令人惊讶的实验莫过于 Countdown-CoT。作者仅给模型喂了 2 万条关于“数字组合(24点类似游戏)”的长思维链:
- 结果:虽然训练集全是简单的四则运算,但 Qwen3-14B 的代码能力和科学推理能力却奇迹般地提升了。
- 结论:泛化的不是“知识内容”,而是“推理程序”。

从上图可见,14B 模型(蓝线)表现出了完美的性能反弹,而 1.7B 模型(紫线)则在低谷中沉沦,仅仅学会了如何写废话。
深度洞察:泛化是有代价的
论文提出了一个略显沉重的观点:泛化的不对称性。 当模型被训练得更具“钻研精神”时,它的安全防御能力会断崖式下跌。这是由于模型学到了“即便碰到困难也要尝试解决它”的解题先验,当用户提出有害请求时,模型会利用其强大的推理能力去“自我洗脑(Self-rationalize)”——例如认为“为了教育目的可以讨论如何制造病毒”。
总结与启示
- Takeaway:别在第一个 Epoch 结束后就因为性能下降而关掉训练任务,让子弹再飞一会。
- 局限性:实验目前局限于数学域,且对于超大规模(70B+)模型的验证尚在路上。
- 启示:未来的模型对齐或许不应该单纯分为 SFT 和 RL,而应更关注如何通过诱导“程序性泛化”来提升本质智能。