本文提出了 SELF1E,这是首个仅需单个 [SEG] Token 且无需外部 Specialist Mask Decoder 即可实现高性能分割的多模态大模型(MLLM)。通过挖掘 MLLM 自身的表示能力,在 RefCOCO 等多项任务上达到了与复杂解码器架构相当的 SOTA 水平。
TL;DR
在多模态大模型(MLLM)步入像素级理解的今天,我们是否真的需要一个像 SAM 或 Mask2Former 这样的“外挂”解码器?本文提出的 SELF1E 给出了肯定的否定。它通过 单分割 Token(1 Embedding) 和 无解码器(Decoder-free) 的架构,不仅在性能上刷爆了 RefCOCO 和 Reasoning Segmentation 等榜单,更在推理速度上实现了对比基线的数倍提升。
核心动机:为什么要自力更生?
以往的逻辑总认为 LLM 擅长文字推理,而像素级的精准分割需要专业的视觉模型。因此,LISA 等 SOTA 工作普遍采用“MLLM 提供指令向量 + 外部解码器(Specialist Decoder)出图”的模式。
这种模式存在三个痛点:
- 参数冗余:引入几亿参数的外部解码器会显著增加推理延迟。
- 信息瓶颈:MLLM 为了效率,通常会进行 Pixel-shuffle 降采样(如 InternVL 系),大幅降低了用于分割的原始分辨率。
- 多 Token 开销:部分尝试去掉解码器的方法(如 UFO)需要生成 16 个 Token 来补偿,效率依然受限。
SELF1E 的直觉是:如果能找回被压缩掉的高分辨率信息,并加强 [SEG] Token 与 [IMG] Token 的互动,MLLM 本身就能成为顶尖的分割器。
方法论详解:三维出击打破分辨率僵局
1. 残差特征填充 (RFR) 与放大 (RFA)
为了解决 Pixel-shuffle 带来的空间损失,作者设计了双路径架构。它不仅保留了原始的未压缩特征(Pre-compressed features),还通过提取 LLM 处理前后的残差(Residual),将其填充回高分辨率维度。
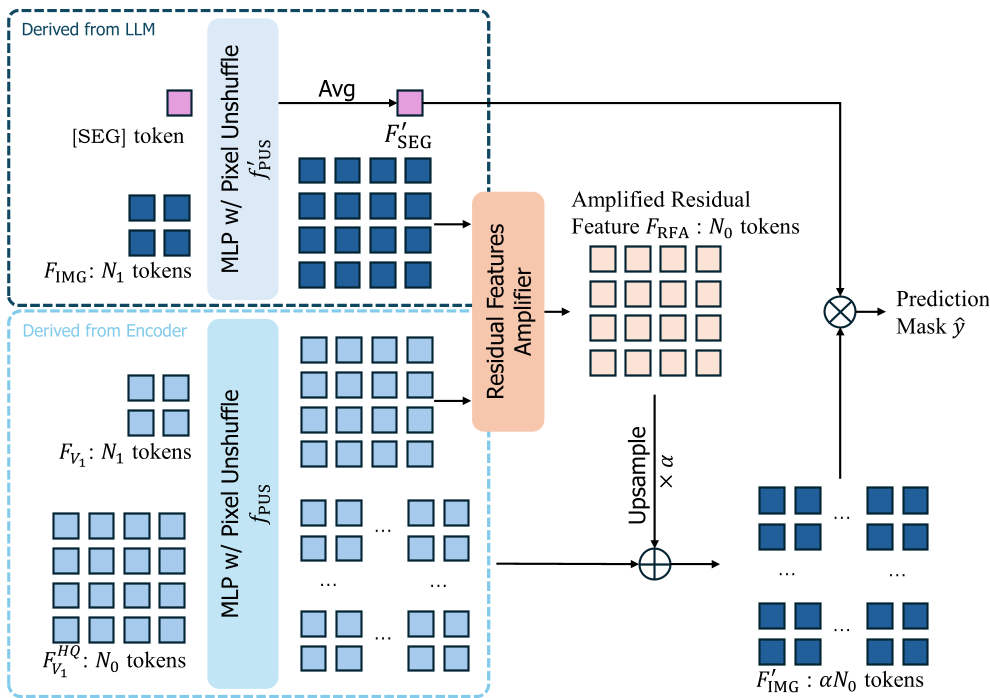 图 1:RFR 与 RFA 模块详解,展示了如何通过残差路径恢复细粒度特征
图 1:RFR 与 RFA 模块详解,展示了如何通过残差路径恢复细粒度特征
2. 双向 perception 掩码
传统的 LLM 采用 Causal Mask,[IMG] Token 看不到后面的 [SEG] Token。作者大胆打破这一策略,在分割任务中引入了 Image-to-Segmentation 的双向注意力互动。这意味着 [IMG] Token 在演化的每一层都能“感知”到分割目标的信息,从而更好地调整自身的特征分布。
实验与结果:快、准、稳
实验证明,在不借助外部解码器的情况下,SELF1E 在多项任务上表现惊人:
- Refering Segmentation:在 RefCOCOg 任务上,SELF1E-8B 达到了 82.8% cIoU,超越了所有带解码器的同类模型。
- Reasoning Segmentation:即便没有专门的分割解码器,其强大的 LLM 底座仍保留了极高的推理精度(cIoU 69.7%)。
- 推理效率:其 FPS 是 LISA 的 2.4 倍,是 UFO 的 9.1 倍。
 图 2:可视化对比显示,加入 RFR 与 PUS 模块后,模型能精准识别出如“腿部间隙”等细微结构
图 2:可视化对比显示,加入 RFR 与 PUS 模块后,模型能精准识别出如“腿部间隙”等细微结构
深度洞察
SELF1E 的成功揭示了一个深刻的学术见解:MLLM 的分辨率瓶颈不在于模型的参数容量,而在于信息流动的机制。 通过重新设计特征对齐(Alignment)而不是无脑堆砌外部模块,我们能获得更加优雅且高效的统一视觉-文本系统。
局限性:虽然分割能力爆表,但在 OCR 密集型任务和极高性能的知识问答上(如 TextVQA),由于任务侧重的偏移,仍存在细微的性能权衡(Trade-off)。
总结
SELF1E 证明了“大道至简”。它不仅刷新了性能边界,更为未来端侧(On-device)部署的高清实时分割多模态模型指明了方向。
关键词:InternVL, MLLM, Decoder-free Segmentation, Pixel-unshuffle, SELF1E