本文提出了 Perception-Exploration Policy Optimization (PEPO),一种针对多模态大模型(LVLMs)的 Token 级强化学习框架。该方法通过结合隐藏层状态的视觉相似度和 Token 熵,在 GRPO 和 DAPO 等主流 RLVR 框架上实现了显著的推理性能提升,特别是在几何推理、视觉寻物和复杂拼图任务中达到 SOTA。
TL;DR
在多模态思维链(CoT)推理中,并非所有 Token 都同等重要。南开大学 VCIP 团队提出的 PEPO (Perception-Exploration Policy Optimization) 框架,首次深入探讨了多模态推理中“感知锚定”与“逻辑探索”的互补性。通过对 Token 级优势值进行动态重加权,PEPO 在不增加额外参数的情况下,显著增强了 LVLMs 在几何、数学及视觉定位任务上的表现。
1. 痛点:被忽略的 Token 差异性
目前的强化学习框架(如 DeepSeek 提出的 GRPO)在优化 LVLM 时,通常采用序列级奖励(Outcome-based Reward)。这意味着如果一个几何题答对了,整个推理序列中的所有 Token(包括废话、过渡词和核心逻辑)都会获得同样的“奖励”。
这种“大水漫灌”式的优化存在两大弊端:
- 感知失效:模型可能通过语言习惯凑出了正确答案,而非真正看懂了图片。
- 梯度不平衡:大量的语言填充词占据了梯度更新的主导地位,掩盖了关键的视觉感知步骤。
2. 物理直觉:感知(Perception)与探索(Exploration)
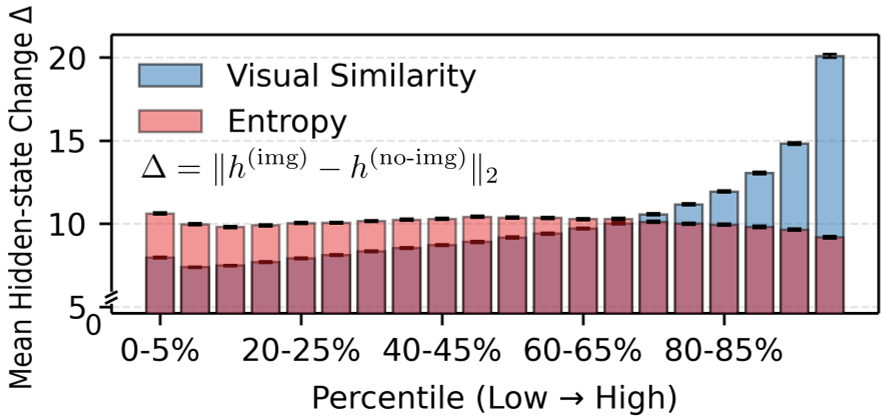
作者通过实验发现了一个有趣的规律:正确的推理往往伴随着一小部分与视觉 Token 高度相关的关键 Token。
- 感知先验(VS):通过计算响应 Token 与视觉 Token 隐藏层状态的余弦相似度,可以精准识别出哪些 Token 正在通过图像寻找证据(如“直角”、“三角形”等实体)。
- 探索熵(Entropy):高熵 Token 通常出现在逻辑转折点(如“因此”、“但是”),代表了模型在推理路径上的不确定性和尝试。
PEPO 的核心直觉是:好的多模态推理应当在关键视觉感知处保持专注,在逻辑决策点积极探索。
3. 核心方法论:平滑门控重加权
PEPO 并没有设计复杂的辅助网络,而是巧妙地在现有的 GRPO/PPO 流程中插入了一个感知-探索融合模块:
- 相似度提取:计算响应 Token 与视觉特征的 Cross-layer 余弦相似度。
- 门控融合:利用
tanh激活函数构建平滑门控,将归一化后的感知得分与熵得分结合。 - 优势分配:将传统的序列优势值 $A^{(i)}$ 重新分配给每个 Token $t$,形成 $A_t^{(i)}$。
这种设计通过一个 $\lambda$ 调度策略,在训练初期保持稳定,后期逐渐强化 Token 级的精细化引导,确保了感知与逻辑的深度耦合。
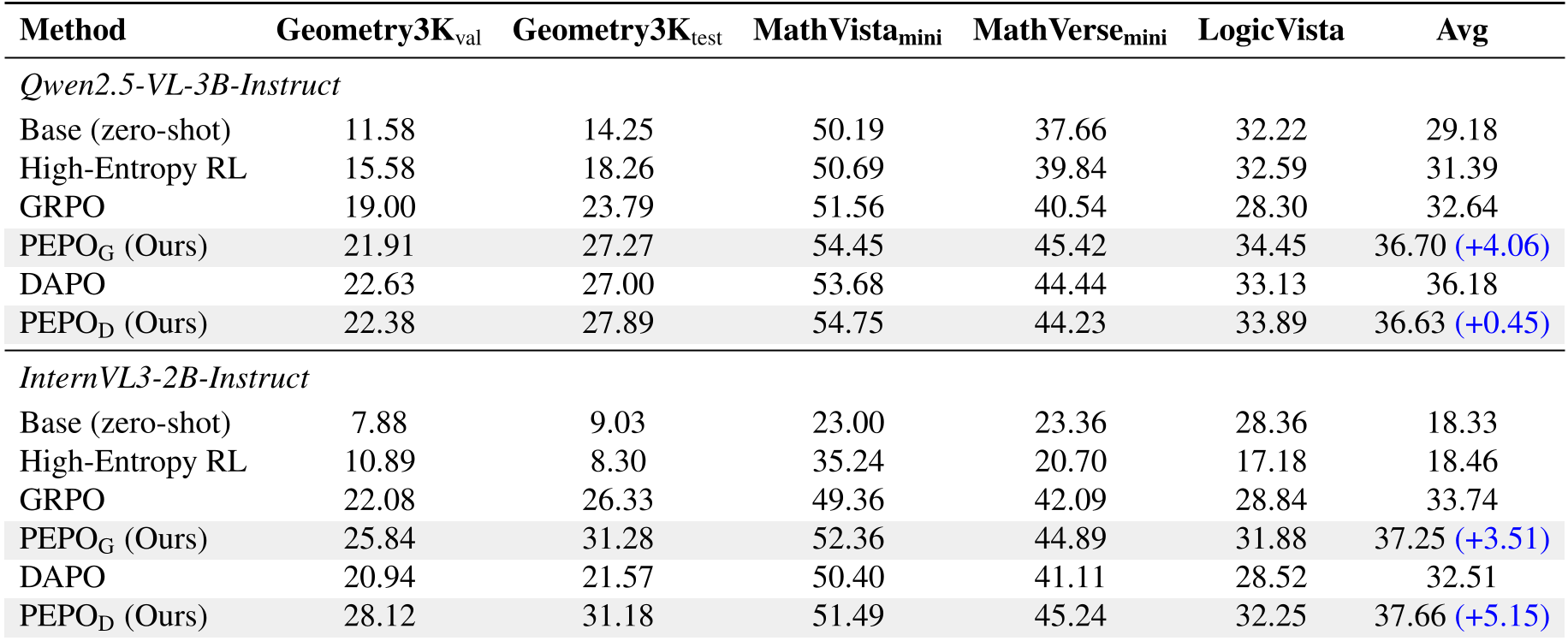
4. 实验战绩:全线 SOTA
实验涵盖了从 Qwen2.5-VL-3B 到 InternVL3-2B 的多种架构。在 Geometry3K 几何推理任务中,PEPO 相比强基线 GRPO 带来了显著的性能飞跃(+3.67 pts)。
更深刻的发现:
- 效率更高:PEPO 倾向于生成更短、更高效的推理链,减少了冗余的“幻觉”文本。
- 鲁棒性强:在少样本(Few-shot)和跨域(Out-of-domain)测试中表现尤为强劲,证明感知能力的增强带来了更好的迁移性。
5. 深度洞察与总结
PEPO 的价值在于提出了一个非常简洁且符合直觉的视角:LVLM 的强化学习不应只是语言模型的延伸,而必须显式地考虑视觉感知的权重。
局限性:尽管在 3B 级别的模型上表现优异,但在 70B 或更大体量的模型上,由于隐藏层相似度计算的计算成本随 Layer 数增加,可能需要更高效的采样策略。
未来启示:这一机制可以进一步推广到视频 CoT 或机器人操控任务中,在这些领域,“动作”与“感知流”的实时对齐(Grounding)比纯文本逻辑更为关键。
本文由资深学术技术主编重构。PEPO 开源代码已发布在 GitHub (xzxxntxdy/PEPO)。