The paper introduces RLCSD (Reinforcement Learning with Contrastive on-policy Self-Distillation), a novel framework for training reasoning models. By contrasting teacher distributions conditioned on correct vs. incorrect solutions, it identifies and removes "privilege-induced style drift," achieving SOTA results across Qwen3 and Olmo-3 models in mathematical and logical reasoning tasks.
TL;DR
Training reasoning models using On-Policy Self-Distillation (OPSD) often fails because the model learns to mimic the style of a "hinted" teacher (e.g., becoming more assertive or shorter) rather than its reasoning logic. RLCSD fixes this by using a contrastive approach: it compares responses given a "correct" hint against a "wrong" hint. This cancels out the "style drift," focusing the learning signal on critical task tokens (numbers, operators). The result? Unprecedented stability and significant SOTA gains in Math and Logic benchmarks.
The Invisible Trap: Privilege-Induced Style Drift
In the quest to move beyond sparse "correct/incorrect" rewards, researchers used OPSD: letting a model teach itself by looking at the ground truth. However, the authors of RLCSD noticed a peculiar pathology they call Privilege-Induced Style Drift.
When a model is "hinted" with a solution, its internal probability distribution shifts. But it doesn't just get smarter about the math; it gets "lazy" or "bossy." It starts prioritizing discourse markers like "Therefore" or "Wait" (Style Tokens) by nearly 3x the magnitude of actual mathematical symbols (Task Tokens).
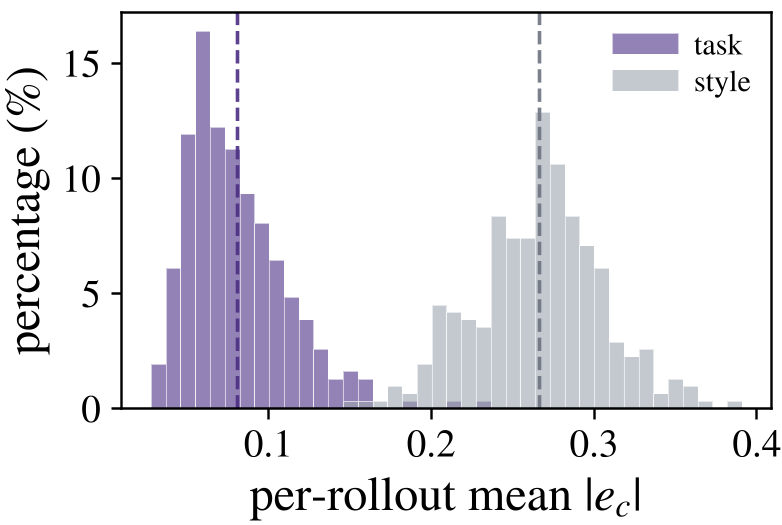 Figure: The "Privilege" mostly affects style tokens (0.263) rather than the math tokens (0.083) that actually solve the problem.
Figure: The "Privilege" mostly affects style tokens (0.263) rather than the math tokens (0.083) that actually solve the problem.
This drift leads to two catastrophic failure modes:
- Entropy Explosion: The model becomes unstable and generates nonsense.
- Premature Shrinkage: The model stops "thinking" step-by-step and jumps to short, often wrong, conclusions.
Methodology: The Power of Subtraction
The "Aha!" moment of RLCSD is simple yet profound: If both correct and incorrect hints induce the same stylistic bias, why not subtract them?
The Contrastive Formula
Instead of just looking at the gap between the student and a "correct" teacher (), RLCSD calculates the gap for a "wrong" teacher () and takes the difference:
By using an identical prompt template for both, the "style" component cancels out. What remains is a "purified" signal that points directly to the tokens responsible for correctness.
The RLCSD Pipeline
- Symmetric Hinting: Feed the teacher one correct and incorrect student rollouts.
- Token Modulation: Instead of replacing the RL reward (GRPO), use this purified signal to modulate the advantage.
- Two-Path Loss: Separate tokens that need modulation from those that don't, ensuring the dense signal isn't diluted by the "noise" of easy tokens.
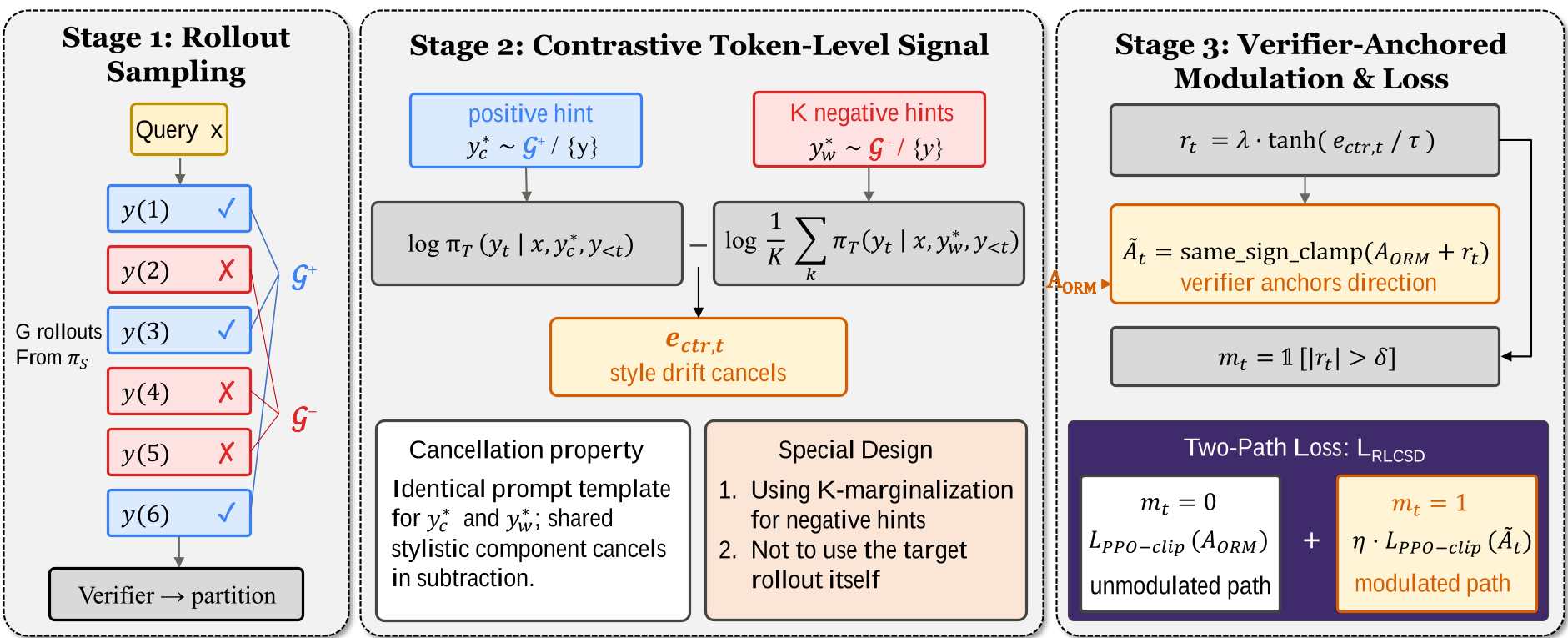 Figure: The RLCSD pipeline from rollout partitioning to contrastive signal generation.
Figure: The RLCSD pipeline from rollout partitioning to contrastive signal generation.
Experimental Results: Stable Reasoning at Scale
RLCSD was tested on Qwen3 (1.7B to 8B) and Olmo-3-7B. Unlike previous methods (SDPO, SRPO) which showed wild swings in response length or entropy, RLCSD remained as stable as standard GRPO but was much more effective.
Key Performance Highlights:
- Out-of-Distribution Logic: On 11-role logical puzzles, RLCSD improved Qwen3-8B by a staggering +21.0%.
- Math Prowess: Consistently beat GRPO across AMC and AIME benchmarks.
- Generalization: The contrastive principle worked even when plugged into other OPSD methods, proving it’s a fundamental discovery about how LLMs learn from hints.
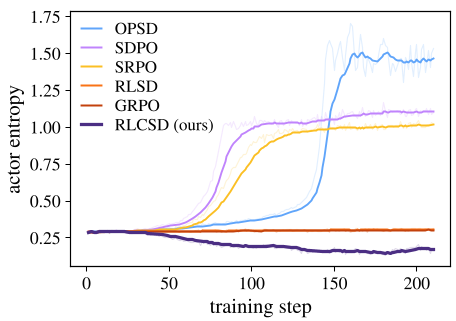 Figure: RLCSD maintains stable entropy and response length, while OPSD and SDPO explode or collapse.
Figure: RLCSD maintains stable entropy and response length, while OPSD and SDPO explode or collapse.
Critical Analysis & Conclusion
The brilliance of RLCSD lies in its diagnosis. It proves that in the era of "reasoning" models (like DeepSeek-R1 or Qwen-Think), the structure of the reward signal is just as important as the amount of data.
Limitations:
- Compute: It requires more teacher forward passes (one for each negative hint). However, the authors show this is negligible (~14s vs ~9s) compared to the time spent generating long reasoning chains.
- Dependence on Errors: The method requires the model to generate at least one wrong and one right answer per prompt to form the contrast.
Future Impact: This paper sets a new standard for how we should treat "privileged" information in RL. Beyond self-distillation, this "style-cancellation" logic could be the key to making cross-model distillation (e.g., distilling a huge GPT-4 teacher into a small local model) actually transfer intelligence instead of just tone.
Senior Editor's Note: RLCSD is a masterclass in identifying a subtle pathology—Style Drift—and solving it with an elegant mathematical symmetry. It is highly recommended for anyone building the next generation of LLM reasoning pipelines.